
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Охарактеризуйте единицы измерения компьютерной информации в двоичной системе счисления.
В качестве наименьшей единицы измерения информации принят 1 бит. 1 бит соответствует одному разряду в двоичной системе счисления. Эта система лежит в основе архитектуры компьютеров. Для представления всего многообразия величин в компьютере объединяют несколько двоичных разрядов. Поэтому более крупными единицами измерения И в компьютере являются: 1 байт = 8 бит; 1 Кбайт=210 байт; 1 Мбайт = 210 Кбайт; 1 Гбайт = 210 Мбайт. Поскольку информация в компьютере хранится в дискретной форме, для ее записи используется некоторый конечный набор знаков, называемый алфавитом. Очень часто в качестве алфавита используется таблица кодов, содержащая около 256 знаков. Каждому знаку соответствует числовой код. Этот код хранит образ соответствующего знака в памяти компьютера. Для понимания системы кодирования информации необходимо рассмотреть правила преобразования числовых кодов в различные системы счисления. В восьми разрядах, например, можно записать 2^8 = 256 различных целых двоичных чисел - от 00000000 до 11111111, что вполне достаточно для того, чтобы дать уникальное (неповторяющееся) 8-битовое обозначение каждой заглавной и строчной букве русского и английского алфавитов, всем арабским цифрам, знакам препинания, некоторым другим необходимым символам, а также служебным кодам для передачи информации (то есть всем символам, которые мы видим на клавиатуре компьютера). Именно этой достаточностью объясняется, почему единицей измерения компьютерной информации служит восьмибитовое число - байт. 7. Для чего нужна кодовая таблица символов? Что такое ASCI |коды? Кодовая таблица — это внутреннее (закодированное) представление в машине букв, цифр, символов и управляющих сигналов. Так, латинская буква А в кодовой таблице представлена десятичным числом 65D (внутри ЭВМ это число будет представлено двоичным числом 01000001В), латинская буква С — числом 67D, латинская буква М — 77D и т. д. Таким образом, слово «САМАРА», написанное заглавными латинскими буквами, будет циркулировать внутри ЭВМ в виде цифр: 67D-65D-77D-65D-80D-65D. Если говорить точнее, то внутри ЭВМ данное слово циркулирует в виде двоичных чисел: 01000011В-01000001В-01001101В-01000001В-01010000В-01000001В. Аналогично кодируются цифры (например, 1 — 49D, 2 — 59D) и символы (например,! — 33D, + — 43D).
Наряду с алфавитно-цифровыми символами в кодовой таблице закодированы управляющие сигналы. Например, код 13D заставляет печатающую головку принтера вернуться к началу текущей строки, а код 10D перемещает бумагу, заправленную в принтер, на одну строку вперед. Кодовая таблица может быть представлена не только с помощью десятичной СС, но и при помощи шестнадцатеричной СС. Еще раз обращаем внимание на тот факт, что внутри ЭВМ циркулируют сигналы, представленные в двоичной системе счисления, а в кодовой таблице для большего удобства чтения пользователем — в десятичной или шестнадцатеричной СС. Каждая буква, цифра, знак препинания или управляющий сигнал кодируются восьмиразрядным двоичным числом. С помощью восьмиразрядного числа (однобайтового числа) можно представить (закодировать) 256 произвольных символов — букв, цифр и вообще графических образов. Во всем мире в качестве стандарта принята кодовая таблица ASCII (A merican S tandard C ode for I nformation I nterchange — Американский стандарт кодов для обмена информацией). Таблица ASCII регламентирует (строго определяет) ровно половину возможных символов (латинские буквы, арабские цифры, знаки препинания, управляющие сигналы). Для их кодировки используются коды от 0D до 127D. Вторая половина кодовой таблицы ASCII (с кодами от 128 до 255) не определена американским стандартом и предназначена для размещения символов национальных алфавитов других стран (в частности, кириллицы — русских букв), псевдографических символов, некоторых математических знаков. В разных странах, на различных моделях ЭВМ, в разных операционных системах могут использоваться и разные варианты второй половины кодовой таблицы (их называют расширениями ASCII). Например, таблица, которая используется в операционной системе MS-DOS, называется CP-866. Используя эту таблицу для кодировки слова «САМАРА», записанного русскими буквами, получим такие коды:
При работе в операционной системе Windows используется таблица кодов CP‑1251, в которой кодировка латинских букв совпадает с кодировкой таблиц CP-866 и ASCII, а вторая половина таблицы имеет собственную раскладку (кодировку) символов. Поэтому слово «САМАРА», написанное заглавными русскими буквами, будет иметь внутри ЭВМ другое представление:
209D-192D-204D-192D-208D-192D. Таким образом, внешне одинаковое слово (например, «САМАРА») внутри ЭВМ может быть представлено различным образом. Естественно, это вызывает определенные неудобства. При работе в Интернет национальный текст порой становится нечитаемым. Наиболее вероятной причиной в этом случае является несовпадение кодировок второй половины кодовых таблиц. Заметим, что если для составления писем, отправляемых по электронной почте, используется первая половина кодовой таблицы (латиница), то проблемы с кодировкой не возникают. Общим недостатком всех однобайтовых кодовых таблиц (в них для кодировки используются восьмиразрядные двоичные числа) является отсутствие в коде символа какой-либо информации, которая подсказывает машине, какая в данном случае используется кодовая таблица. Сообществом фирм Unicode предложена в качестве стандарта другая система кодировки символов. В этой системе для представления (кодирования) одного символа используются два байта (16 битов), и это позволяет включить в код символа информацию о том, какому языку принадлежит символ и как его нужно воспроизводить на экране монитора или на принтере. Два байта позволяют закодировать 65 536 символов. Правда, объем информации, занимаемой одним и тем же текстом, увеличится вдвое. Зато тексты всегда будут «читаемыми» независимо от использованного национального языка и операционной системы. 8. Где используется универсальная система UNICODE? Юникод, или Уникод (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium), объединяющей крупнейшие IT-корпорации. Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становятся ненужными кодовые страницы. Стандарт состоит из двух основных разделов: универсальный набор символов (UCS, Universal Character Set) и семейство кодировок (UTF, Unicode Transformation Format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа. Семейство кодировок определяет машинное представление последовательности кодов UCS. Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены коды от U+0400 до U+052F
|
||||||
|
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 380; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.93.210 (0.007 с.) |
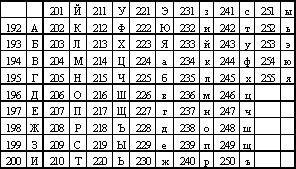 145D-128D-140D-128D-144D-128D.
145D-128D-140D-128D-144D-128D.


