
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Этапы построения деревьев решений
При построении деревьев решений особое внимание уделяется следующим вопросам: выбору критерия атрибута, по которому пойдет разбиение, остановки обучения и отсечения ветвей. Рассмотрим все эти вопросы по порядку.
Правило разбиения. Каким образом следует выбрать признак? Для построения дерева на каждом внутреннем узле необходимо найти такое условие (проверку), которое бы разбивало множество, ассоциированное с этим узлом на подмножества. В качестве такой проверки должен быть выбран один из атрибутов. Общее правило для выбора атрибута можно сформулировать следующим образом: выбранный атрибут должен разбить множество так, чтобы получаемые в итоге подмножества состояли из объектов, принадлежащих к одному классу, или были максимально приближены к этому, т.е. количество объектов из других классов («примесей») в каждом из этих множеств было как можно меньше. Были разработаны различные критерии, но мы рассмотрим только два из них:
Теоретико-информационный критерий Алгоритм C4.5, усовершенствованная версия алгоритма ID3 (Iterative Dichotomizer), использует теоретико-информационный подход. Для выбора наиболее подходящего атрибута, предлагается следующий критерий:
где, Info(T) – энтропия множества T, а
(2)
Множества T1, T2, … Tn получены при разбиении исходного множества T по проверке X. Выбирается атрибут, дающий максимальное значение по критерию (1). Впервые эта мера была предложена Р. Куинленом в разработанном им алгоритме ID3. Кроме вышеупомянутого алгоритма C4.5, есть еще целый класс алгоритмов, которые используют этот критерий выбора атрибута.
Статистический критерий Алгоритм CART использует так называемый индекс Gini (в честь итальянского экономиста Corrado Gini), который оценивает «расстояние» между распределениями классов.
где c – текущий узел, а pj – вероятность класса j в узле c.
Правило остановки. Разбивать дальше узел или отметить его как лист?
В дополнение к основному методу построения деревьев решений были предложены следующие правила: · Использование статистических методов для оценки целесообразности дальнейшего разбиения, так называемая «ранняя остановка» (prepruning). В конечном счете «ранняя остановка» процесса построения привлекательна в плане экономии времени обучения, но здесь уместно сделать одно важное предостережение: этот подход строит менее точные классификационные модели и поэтому ранняя остановка крайне нежелательна. Признанные авторитеты в этой области Л.Брейман и Р. Куинлен советуют буквально следующее: «Вместо остановки используйте отсечение».
· Ограничить глубину дерева. Остановить дальнейшее построение, если разбиение ведет к дереву с глубиной превышающей заданное значение. · Разбиение должно быть нетривиальным, т.е. получившиеся в результате узлы должны содержать не менее заданного количества примеров.
Этот список эвристических правил можно продолжить, но на сегодняшний день не существует такого, которое бы имело большую практическую ценность. К этому вопросу следует подходить осторожно, так как многие из них применимы в каких-то частных случаях.
Правило отсечения. Каким образом ветви дерева должны отсекаться? Очень часто алгоритмы построения деревьев решений дают сложные деревья, которые «переполнены данными», имеют много узлов и ветвей. Такие «ветвистые» деревья очень трудно понять. К тому же ветвистое дерево, имеющее много узлов, разбивает обучающее множество на все большее количество подмножеств, состоящих из все меньшего количества объектов. Ценность правила, справедливого скажем для 2-3 объектов, крайне низка, и в целях анализа данных такое правило практически непригодно. Гораздо предпочтительнее иметь дерево, состоящее из малого количества узлов, которым бы соответствовало большое количество объектов из обучающей выборки. И тут возникает вопрос: а не построить ли все возможные варианты деревьев, соответствующие обучающему множеству, и из них выбрать дерево с наименьшей глубиной? К сожалению, это задача является NP-полной, это было показано Л. Хайфилем (L. Hyafill) и Р. Ривестом (R. Rivest), и, как известно, этот класс задач не имеет эффективных методов решения. Для решения вышеописанной проблемы часто применяется так называемое отсечение ветвей (pruning). Пусть под точностью (распознавания) дерева решений понимается отношение правильно классифицированных объектов при обучении к общему количеству объектов из обучающего множества, а под ошибкой – количество неправильно классифицированных. Предположим, что нам известен способ оценки ошибки дерева, ветвей и листьев. Тогда, возможно использовать следующее простое правило:
- построить дерево; - отсечь или заменить поддеревом те ветви, которые не приведут к возрастанию ошибки. В отличии от процесса построения, отсечение ветвей происходит снизу вверх, двигаясь с листьев дерева, отмечая узлы как листья, либо заменяя их поддеревом. Хотя отсечение не является панацеей, но в большинстве практических задач дает хорошие результаты, что позволяет говорить о правомерности использования подобной методики.
Иногда даже усеченные деревья могут быть все еще сложны для восприятия. В таком случае, можно прибегнуть к методике извлечения правил из дерева с последующим созданием наборов правил, описывающих классы. Для извлечения правил необходимо исследовать все пути от корня до каждого листа дерева. Каждый такой путь даст правило, где условиями будут являться проверки из узлов встретившихся на пути.
|
||||||
|
|
Последнее изменение этой страницы: 2016-08-15; просмотров: 701; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.227.228.95 (0.008 с.) |
 (1)
(1)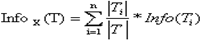
 (3)
(3)



