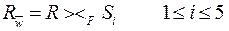Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Распределенные базы данных и СУБДСодержание книги
Похожие статьи вашей тематики
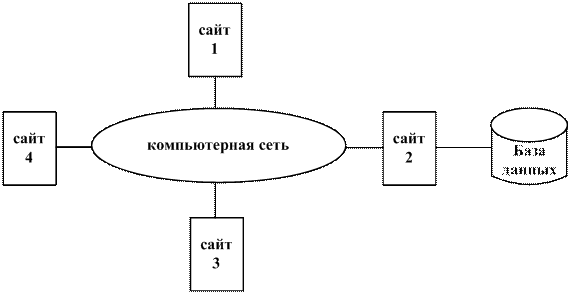
Поиск на нашем сайте Распределенные базы данных и СУБД Технология распределенных баз данных (РБД), получающая в настоящее время широкое распространение, способствует обратному переходу от централизованной обработки данных к децентрализованной. Создание технологии систем управления РБД (СУРБД) является одним из самых больших достижений в области баз данных (БД). Ранее (на 4 курсе) мы рассматривали в основном системы с централизованными базами данных, то есть такие системы, в которых единственная логическая база данных размещалась в пределах одного сайта (ЭВМ) и управлялась единственной системой управления. В рамках этого курса мы рассмотрим концепции и различные вопросы, связанные с распределенными СУБД (РСУБД), которые позволяют конечным пользователям иметь доступ не только к данным, сохраняемым на их собственном сайте, но и к данным, размещенным на различных удаленных сайтах. 1.1 Основные определения, концепции и классификация распределенных систем Основной причиной разработки систем, использующих базы данных, является стремление интегрировать все обрабатываемые в организации (фирме, и т.д.) данные в единое целое и обеспечить к ним (данным) контролируемый доступ. Действительно, интеграция и представление контролируемого доступа необходимы для централизованной обработки данных (централизации), однако последняя, то есть централизация не является самоцелью. На практике создание компьютерных сетей приводит к децентрализации обработки данных. Это обусловлено тем, что децентрализация (децентрализованный подход) более адекватно во многих случаях отражает организационную структуру организации (предприятий, фирм, компаний), логически состоящих из отдельных подразделений (цехов, отделов, проектных групп и т.д.). Эти подразделения физически распределены по разным помещениям (офисам, филиалам, зданиям и т.д.). При этом каждое подразделение (отдельная единица) имеет дело в основном с собственным набором данных [1], но, кроме того, может нуждаться в данных из других подразделений. Разработка РБД позволяет сделать данные, поддерживаемые каждым из существующих подразделений организации, общедоступными, обеспечив при этом их сохранение именно в тех местах, где они чаще всего используются. Основные концепции распределенной обработки данных Очень важно понимать различия, существующие между распределенными СУБД и распределенной обработкой данных (РОД). РОД – обработка с использованием централизованной базы данных, доступ к которой может осуществляться с различных компьютеров сети (клиент-сервер). Ключевым моментом в определении РБД (§1.1.1) является то, что система (СУРБД) работает с данными, физически распределенными в сети. Если же данные хранятся централизованно, то даже в том случае, когда доступ к ним (данным) обеспечивается от любого пользователя сети, такая система просто поддерживает распределенную обработку данных (РОД), но не может рассматриваться, как распределенная СУБД. Пример топологии системы с РОД приведен на рис. 1.2
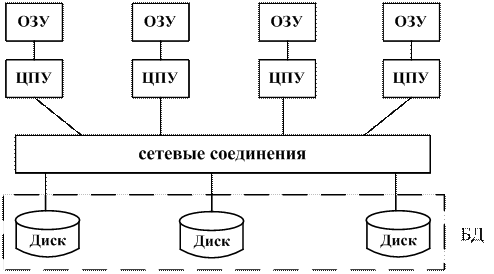
Рис. 1.2. Топология системы с РОД Системы с разделением дисков (СРД) СРД строятся из менее тесно связанных между собой компонентов. Они являются оптимальным вариантом для приложений, которые унаследовали высокую централизацию обработки и должны обеспечивать самые высокие показатели доступности и производительности (рис. 1.5). Каждый из процессоров имеет непосредственный доступ ко всемсовместно используемым дисковымустройствам, но обладает собственной оперативной памятью.
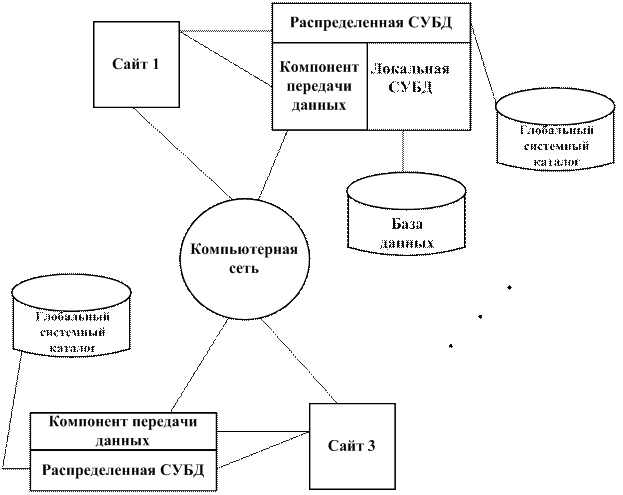
Рис. 1.5. Архитектура системы с параллельной обработкой с разделением дисков Эта архитектура, также как и СБР, исключает узкие места, связанные с совместно используемой оперативной памятью. Однако, в отличие от архитектуры без разделения, данная архитектура исключает упомянутые узкие места без внесения дополнительной нагрузки, связанной с физическим распределением данных по отдельным устройствам. СРД в некоторых случаях называют «кластерами». Следует отметить, что параллельные технологии обычно используют в случае исключительнобольших баз данных (более 1012 байт), или в системах, которые должны поддерживать выполнение тысяч транзакций в секунду. То есть подобные системы нуждаются в доступе к большому объему данных и, в то же время, должны обеспечить приемлемое время реакции на запрос. Параллельные СУБД могут использовать различные вспомогательные технологии, позволяющие повысить производительность обработки сложных запросов, за счет применения методов распараллеливания операций сканирования, соединения и сортировки, что позволяет нескольким процессорным узлам автоматически распределять между собой текущую нагрузку. В настоящее время все крупные разработчики СУБД поставляют, так называемые, параллельные версии созданных ими продуктов. Мультибазовые системы Мультибазовые системы – распределенные системы управления базами данных, в которых управление каждым из сайтов осуществляется совершенно автономно, принято называть мультибазовыми (МБС) или МБСУБД. В таких МБС предпринимаются попытки интеграции таких систем баз данных, в которых весь контроль над отдельными локальными системами целиком и полностью осуществляется их операторами. Одним из следствий полной автономии сайтов является отсутствиенеобходимостивнесенияизменений в локальные СУБД. А из этого следует, что мультибазовые СУБД требуют создания поверх существующих локальных систем дополнительногоуровняпрограммногообеспечения, предназначенного для обеспечения необходимой функциональности МБСУБД. МБС позволяют конечным пользователям разных сайтов получать доступ и совместно использовать данные без необходимости физической интеграции существующих баз данных. Они обеспечивают пользователям (операторам) возможность управлять базами данных их собственных сайтов без какого-либо централизованного контроля, который обязательно присутствует в обычных типах СУРБД. Администратор (оператор) локальной базы данных можетразрешитьдоступ к определенной части своей базы данных посредством создания так называемой схемы экспорта, определяющей, к каким элементам локальной базы данных смогут получать доступ внешние пользователи. Другими словами, мультибазовая СУБД является такой СУБД, которая прозрачным образом располагается поверх существующих баз данных и файловых систем, предоставляя их или часть их своим пользователям, как некоторую единуюбазуданных. МБСУБД поддерживает глобальную схему, на основании которой пользователи могут строить запросы и модифицировать данные. МБСУБД работает только с глобальной схемой, тогда как локальные СУБД собственными силами обеспечивают поддержку данных всех их пользователей. Глобальная схема создается посредством интеграции схем локальных баз данных. Программное обеспечение МБСУБД предварительно транслирует глобальные запросы и превращает их в запросы и операторы модификации данных соответствующих локальных СУБД. Затем полученные после выполнения локальных запросов результаты сливаются в единый глобальный результат, предоставляемый конечному пользователю. Кроме того, МБСУБД осуществляет контроль за выполнением фиксации или отката отдельных операций глобальных транзакций в локальных СУБД, а также обеспечивает целостность данных в каждой из локальных баз данных. Программы МБСУБД управляют различными шлюзами, с помощью которых они контролируют работу локальных СУБД. К примеру МБС Uni SQL/M фирмы Uni SQL Inc. позволяет разрабатывать приложения с помощью единого глобального представления и единственного языка доступа к базе данных для работы со многими гетерогенными реляционными и объектно-ориентированными СУБД. Преимущества Повышение надежности Если организована в распределенной системе репликация данных, в результате чего данные и их копии будут размещены на более чем одном сайте, то отказ отдельного узла или соединительной линии связи между узлами не приведет к недоступности данных в системе. Экономические выгоды В шестидесятые годы мощность вычислительной установки возрастала пропорционально квадрату стоимости ее оборудования. Поэтому система, стоимость которой была втрое выше стоимости данной, превосходили ее по мощности (обычно) в девять раз. Эта зависимость получила название закона Гроша [1]. Однако в настоящее время считается общепринятым положение, согласно которому намного дешевле собрать из небольшихкомпьютеров систему, мощность которой будет эквивалентна мощности одного большогокомпьютера. Оказывается, что намного выгоднее устанавливать в подразделениях организации собственные маломощные компьютеры и добавить в сеть новые рабочие станции, чем модернизировать (умощнять) систему с мейнфреймом (центральнойЭВМ). Второй потенциальный источник экономии имеет место в том случае, когда базы данных географически удалены друг от друга и приложения требуют осуществления доступа к распределенным данным. В этом случае из-за относительно высокой стоимости передаваемых по сети данных (по сравнению со стоимостью их локальной обработки) может оказаться экономически выгодным разделить приложение на соответствующие части и выполнять необходимую обработку на каждом из сайтов локально. Модульность системы В распределенной среде расширение существующей системы намного проще. Добавление в сеть нового сайта не оказывает влияния на функционирование уже существующих. Подобная гибкость позволяет организации легко расширяться. Перегрузки из-за увеличения размера базы данных обычно устраняются путем добавления в сеть новых вычислительных мощностей и устройств дисковой памяти. В централизованных СУБД рост размера базы данных может потребовать замены и оборудования (более мощной системой), и используемого программного обеспечения (более мощной и/или гибкой СУБД). Недостатки Повышение сложности РСУБД являются более сложными программными комплексами, чем ЦСУБД. Тот факт, что данные могут подвергаться репликации, также добавляет дополнительный уровень сложности в ПО СУРБД, и если репликация данных не будет поддерживаться на требуемом уровне, распределенная система будет иметь более низкий уровень доступности данных, надежности и производительности, чем централизованные системы (ЦС). Увеличение стоимости Увеличение сложности означает и увеличение затрат на приобретение и сопровождение СУРБД (по сравнению с обычными ЦСУБД). Разворачивание распределенной СУБД потребует дополнительного оборудования, необходимого для обеспечения сложных соединений между сайтами. Следует ожидать и роста расходов на оплату каналов связи, вызванных возрастанием сетевого графика (загрузки каналов). Кроме того, возрастают затраты на оплату труда персонала, который потребуется для обслуживания локальных СУБД и сетевых соединений. Усложнение проблем защиты В ЦС доступ к данным сравнительно легко контролируется. Однако в РС необходимо организовать контроль доступа не только к данным, реплицируемым на несколько различных сайтов, но и защиту сетевых соединений самихпосебе. Раньше сети рассматривались как совершенно незащищенные каналы связи. Сейчас есть прогресс в защите сетевых соединений. Отсутствие стандартов Функционирование РСУБД зависит от эффективности используемых каналов связи, но только в последнее время стали вырисовываться контуры стандарта на каналы связи и протоколы доступа к данным. Отсутствие стандартов ограничивает потенциальные возможности РСУБД и РБД. Кроме того, не существует инструментальных средств и методологий, способных помочь пользователям в преобразовании ЦС в РС. Недостаток опыта В настоящее время в эксплуатации уже находятся РСУБД специального назначения, что позволило уточнить требования к используемым протоколам и установить круг основных проблем. Однако РС общегоназначения еще не получили распространения. Соответственно, еще не накоплен необходимый опыт промышленной эксплуатации РС, сравнимый с опытом эксплуатации ЦС. Такое положение дел является сдерживающим фактором для многих потенциальных сторонников новых информационных технологий. Функции распределенных СУБД Очевидно, что типичная распределенная СУБД должна обеспечивать, как минимум, тот же набор функциональных возможностей, который был определен для централизованных СУБД (см. стр. 2): ¾ обеспечение возможности определения описания данных; ¾ обеспечение возможности манипулирования данными; ¾ обеспечения контролируемого доступа к БД. Кроме того, РСУБД должна представлять следующий набор функциональных возможностей: ¾ расширенные службы установки соединений должны обеспечивать доступ к удаленнымсайтам и позволять передавать запросы и данные между сайтами, входящими в сеть; ¾ расширенные средства ведения каталога, позволяющие сохранить сведения о распределенииданныхвсети; ¾ средства обработкираспределенныхзапросов, включая механизмы оптимизации запросов и организации удаленного доступа; ¾ Расширение функций управления параллельностью, позволяющих поддерживать целостность реплицируемых данных; ¾ Расширение функций восстановления, учитывающих возможность отказов в работе отдельных сайтов и отказов линий связи. Локальные схемы Каждая локальная СУБД имеет свой собственный набор схем. Локальная концептуальная и локальная внутренняя схемы полностью соответствуют эквивалентным уровням структуры ANSI-SPARC. Локальная схема отображения используется для отображения фрагментоввсхемераспределения во внутренние объекты локальной базы данных. Эти элементы являются зависимыми от типа используемой СУБД и служат основой для построения гетерогенных (разнообразных) СУБД. Независимо от рекомендованной общей архитектуры СУРБД компонентная архитектура СУРБД должна включать четыре следующих важнейших компонента (рис. 1.4.1) [1]: 1) локальную СУБД; 2) компонент передачи данных; 3) глобальный системный каталог; 4) распределенную СУБД (СУРБД). Для упрощения на рис. 1.4.2 сайт 2 не показан, поскольку его структура не отличается от структуры сайта 1.
Рис. 1.4.2. Компонентная архитектура распределенной СУБД Локальная СУБД Компонент ЛСУБД представляет собой стандартную СУБД, предназначенную для управления локальными данными на каждом из сайтов, входящих в состав распределенной БД. ЛСУБД имеет свой собственный системный каталог, в котором содержится информация о данных, сохраняемых на этом сайте. В гомогенных системах на каждом из сайтов в качестве локальной СУБД используется одинитотжепрограммныйпродукт. В гетерогенных системах существуют, по крайней мере, два сайта, использующих различныетипыСУБД и/или различные типы вычислительных платформ.
Компонент передачи данных КПД представляет собой программное обеспечение, позволяющее всем сайтам взаимодействовать между собой. Он содержит сведения о существующих сайтах и линиях связи между ними. Распределенная СУБД Компонент распределенной СУБД является управляющимпоотношениюковсейсистемеэлементом. В предыдущем разделе описаны основные функциональные возможности, которыми должен обладать этот компонент. Обсуждение этих функциональных возможностей будет продолжено в следующих разделах. Распределение данных Существует четыре альтернативных стратегии распределения (размещения) данных в системе: 1. централизованное; 2. раздельное (фрагментированное); 3. размещение с полной репликацией; 4. размещение с выборочной репликацией. 1. Централизованное размещение. Данная стратегия предусматривает создание на одном из сайтов (сервере) единственной базы данных под управлением СУБД, доступ к которой будут иметь все пользователи сети (эта стратегия под названием «распределенная обработка» уже рассматривалась ранее (лекция 1)). В этом случае так называемая локальность ссылок (упрощенно: удобство в получении данных) минимальна для всех сайтов (клиентов), за исключением центрального, поскольку для получения любого доступа к данным требуется установка сетевого соединения. Соответственно уровень затрат на передачу данных будет высок, а уровень надежности и доступности в системе низок, поскольку отказ на центральном сайте вызывает паралич работы всей системы. 2. Раздельное (фрагментированное) размещение. В этом случае база данных разбивается на непересекающиесяфрагменты, каждый из которых размещается на одномизсайтов системы. Если элемент данных будет размещен на том сайте, на котором он чаще всего используется, то полученный уровень локальности ссылок будет высок. При отсутствии репликации стоимость хранения данных будет минимальна, но при этом будет невысок уровень надежности и доступности данных в системе. Однако он будет выше, чем в предыдущем варианте (ЦР), поскольку отказ на любом из сайтов вызовет утрату доступа только к той части данных, которая на нем хранилась. При правильно выбранном способе распределения данных уровень производительности в системе будет относительно высоким, а уровень затрат на передачу данных – низким. 3. Размещение с полной репликацией. Данная стратегия предусматривает размещение полнойкопии всей базы данных на каждом из сайтов системы. Следовательно, локальность ссылок, надежность и доступность данных, а также уровень производительности будут максимальны. Однако стоимость устройств хранения данных и уровень затрат на передачу данных в этом случае также будут самыми высокими. Для преодоления части этих проблем иногда используется технология моментальных снимков. Моментальный снимок представляет собой копию базы данных в определенный момент времени. Эти копии обновляются через некоторый установленный интервал времени – например, один раз в час или в неделю, - а потому они не всегда будут актуальными в текущий момент. Иногда в распределенных системах моментальные снимки используются для реализации представлений, что позволяет улучшить время выполнения в базе данных операций представления. 4. Размещение с выборочной фрагментацией. Данная система представляет собой комбинацию методов фрагментации, репликации и централизации. Одни массивы данных распределяются на фрагменты, что позволяет добиться для них высокой локальности ссылок. Другие массивы данных, которые используются на многих сайтах, но не подвержены частым обновлениям, подвергаются репликации. Третьи (оставшиеся) данные хранятся централизованно. Целью применения данной стратегии является объединениевсех преимуществ, существующих в рассмотренных ранее стратегиях размещения, с одновременным исключением свойственных им недостатков. Характеристики всех рассмотренных стратегий приведены в табл. 1.5.1. Фрагментация Назначение фрагментации Необходимость фрагментации вызывают следующие причины. Условия пользования. Чаще всего приложения работают с некоторыми представлениями (фрагментами или частями базового отношения), а не с полными базовыми отношениями. Следовательно, с точки зрения распределения данных, целесообразнее организовать работу приложений с определенными фрагментами отношений, выступающими как распределяемые элементы. Эффективность. Данные хранятся в тех местах, в которых они чаще всего используются. Кроме того, исключается хранение данных, которые не используются локальными приложениями. Параллельность. Поскольку фрагменты являются распределенными элементам, транзакции могут быть разделены на несколько подзапросов, обращающихся к различным фрагментам. Такой подход дает возможность повысить уровень параллельности обработки в системе, т. е. позволяет транзакциям, которые допускают это, безопасно выполняться в параллельном режиме. Защищенность. Данные, не используемые приложениями, не хранятся на соответствующих (т.е. тех же) сайтах, а значит неавторизованные (несанкционируемые) пользователи не смогут получить к ним доступ. Механизму фрагментации свойственны два основных недостатка (ранее обсуждались). Производительность. Производительность приложений, требующих доступа к данным из нескольких фрагментов, расположенных на различных сайтах, может оказаться недостаточной (ниже требуемой). Целостность данных. Поддержка целостности данных может существенно осложняться, поскольку функциональнозависимыеданные могут оказаться фрагментированными и размещаться на различных сайтах. 1...1 Корректность фрагментации Фрагментация данных не должна выполняться непродуманно, наугад. Следует обязательно придерживаться при фрагментации следующих трех правил. 1. Полнота. Если экземпляр отношения R разбивается на горизонтальные фрагменты R1, R2, …, Rn, то каждый элемент данных, присутствующий в отношении R, должен присутствовать, по крайней мере, в одном из созданных фрагментов. Выполнение этого правила гарантирует, что какие-либо данные не будут утрачены в результате выполнения фрагментации. 2. Восстанавливаемость. Должна существовать операция реляционной алгебры (например, «объединение»), позволяющая восстановить отношение R из его фрагментов. Это правило гарантирует сохранение функциональных зависимостей. 3. Непересекаемость. Если элемент данных di (домена d1, d2, …, di,…, dm) присутствует во фрагменте R, то он не должен одновременно присутствовать в каком-либо ином фрагменте. Исключением из этого правила является операция вертикальная фрагментация, поскольку в этом случае в каждом фрагменте должны присутствовать атрибуты значения первичного ключа, необходимые для восстановления исходного отношения. Данное правило гарантирует минимальную избыточность данных во фрагментах. Типы фрагментации Существует два основных типа фрагментации: горизонтальная и вертикальная. Горизонтальные фрагменты представляют собой подмножествакортежей отношения, т.е. выделенный по горизонтали фрагмент отношения (рис.1.5.2.1). Они выделяются с помощью операции выборки РА.
Рис. 1.5.2.1. Горизонтальная фрагментация Вертикальные фрагменты представляют собой подмножества атрибутов и их значений отношения, т.е. выделенный по вертикали фрагмент отношения (рис.1.5.2.2.). Они выделяются с помощью операции проекции РА.
Рис.1.5.2.2. Вертикальная фрагментация Кроме того, существует еще два типа более сложной фрагментации: смешанная и производная. Смешанный фрагмент образуется либо посредством дополнительной вертикальной фрагментации созданных ранее горизонтальных фрагментов, либо за счет вторичной горизонтальной фрагментации предварительно определенных вертикальных фрагментов. Смешанная фрагментация определяется с помощью операций выборки и проекции РА (рис. 1.5.2.3).
Рис.1.5.2.3. Смешанная фрагментация а) горизонтально разделенные вертикальные фрагменты; б) вертикально разделенные горизонтальные фрагменты. Производная горизонтальная фрагментация. Некоторые приложения включают операции соединения двух или больше отношений. Если отношения сохраняются в различных местах, то выполнение их соединения создаст очень большую дополнительную нагрузку на систему. В подобных случаях более приемлемым решением будет размещение соединяемых отношений или их фрагментов в одном и том же месте. Данная цель может быть достигнута за счет применения производной горизонтальной фрагментации. Производный фрагмент – это горизонтальный фрагмент отношения, созданный на основе дочернего отношения – горизонтального фрагмента родительского отношения. Термин «дочернее» используется для ссылок на отношение, содержащее внешний ключ, а термин «родительское» - для ссылок на отношение с соответствующим первичным ключом. Определение производных фрагментов осуществляется с помощью операции полусоединения РА. Если заданы дочернее отношение R и родительское отношение S, то производный фрагмент отношения R может быть определен так:
Здесь значение w – это количество горизонтальных фрагментов, определенных для отношения S, а параметр F задает атрибут, по которому выполняется их соединение. Отказ от фрагментации. Последний вариант возможной стратегии состоит в отказе от фрагментации отношения. Репликации. Репликацию можно определить как процессгенерации и воспроизведения нескольких копий данных, размещенных на одном или нескольких сайтах. Механизм репликации важен, поскольку позволяет организации обеспечивать доступ пользователям к актуальным данным там и тогда, когда они в этом нуждаются. Использование репликации позволяет достичь многих преимуществ, включая: 1) повышение производительности (в тех случаях, когда централизованный ресурс оказывается перегруженным), 2) повышение надежности хранения, 3) наличие горячей резервной копии на случай восстановления. Виды репликации Протоколы обновления реплицируемых данных построены на допущении, что обновления всех копий данных выполняются какчастьсамойтранзакцииобновления. Другими словами, все копии реплицируемых данных обновляются одновременно с изменением исходной копии (т.е. родительского отношения), как правило, с помощью протокола двухфазной фиксации транзакций. Такой вариант репликации называется синхронной репликацией. Хотя этот механизм может быть просто необходим для некоторого класса систем, в которых все копии данных требуется поддерживать в абсолютно синхронном состоянии (например, в случае финансовых операций, ему свойственны определенные недостатки). В частности, транзакция не может быть завершена, если один из сайтов с копией реплицируемых данных окажется недоступным. Кроме того, множество сообщений, необходимых для координации процесса синхронизации данных, создает дополнительную нагрузку на корпоративную сеть. Многие распределенные СУБД представляют другой механизм репликации, получивший название асинхронного. Он предусматривает обновление целевых баз данных (на сайтах 2÷N) после выполнения обновления исходной базы данных (на сайте, к примеру, 1). При этом имеет место задержка в восстановлении согласованности данных. Она может варьироваться от нескольких секунд до нескольких часов или даже дней. Однако рано или поздно данные во всех копиях будут приведены в исходное состояние. Такой подход нарушает принцип независимости от места размещения распределенных данных, но, тем не менее, он вполне может пониматься как приемлемый компромисс между целостностью данных и их доступностью. Последнее свойство может быть важнее для организаций, чья деятельность допускает работу с копией данных, необязательноточносинхронизированной на текущий момент. Функции службы репликации В качестве базового уровня служба репликации (СР) распределенных данных должна быть способна копировать данные из одной базы данных в другую синхронно или асинхронно. Но кроме этого, требуется, чтобы она (СР) выполняла и другие функции. Масштабируемость. СР должна эффективно обрабатывать как малые, так и большие объемы данных. Отображение и трансформация. Служба репликации (СР) должна поддерживать репликацию данных в гетерогенных системах, использующих несколько платформ. Это может быть связано с необходимостью отображения и преобразования данных из одной модели данных в другую или же преобразования некоторого типа данных в другой тип данных, но для среды другой СУБД. Средства определения схемы репликации. Система должна предоставить механизм, позволяющий привилегированным пользователям задавать данные и объекты, подлежащиерепликации. Механизм подписки. СР должна включать механизм, позволяющий привилегированным пользователям оформлять подписку на данные и другие подлежащие репликации объекты. Механизм инициализации. СР должна включать средства, обеспечивающие инициализацию вновь создаваемой реплики. Схемы владения данными Владение данными определяет, какому из сайтов будет представлена привилегия обновления данных. Основными типами схем владения являются варианты: «ведущий - ведомый», «рабочий поток», «повсеместное обновление». 1. При организации владения данными по схеме «ведущий - ведомый» асинхронно реплицируемые данные принадлежат одному из сайтов, называемому ведущим или первичным, и могут обновляться только на нем. Здесь можно привести аналогию между издателем и подписчиками. Издатель (ведущийсайт) публикует свои (обновленные) данные. Все остальные сайты (подписчики) только лишь подписываются на эти данные, принадлежащие ведущему сайту, т.е. имеют собственные локальные копии, доступные им только длячтения. Потенциально каждый из сайтов может играть роль ведущего для различных, не перекрывающихся наборов данных. Однако в системе может существовать только один сайт, на котором располагается ведущая обновляемая копия каждогоконкретногонабораданных. Следовательно при такой схеме владения данными конфликты обновления данных в системе полностью исключены. 2. При организации схемы владения данными по схеме «рабочий поток» есть возможность передавать право обновления реплицируемых данных от одного сайта к другому. Однако, в каждый конкретный момент времени существует толькоодинсайт, имеющий право обновлять некоторый конкретный набор данных. При такой схеме также удается избежать появления конфликтов обновления, хотя этой модели свойственен больший динамизм. При такой схеме приложения могут быть распределены по различным сайтам, и когда данные реплицируются или пересылаются на следующий сайт в цепочке, вместе с ними передается и право на их обновление. Типичным примером использования схемы «рабочий поток» является система обработки запросов, в которой работа с каждым заказом выполняется в несколькоэтапов, например, оформление заказа, подготовка счета (в отделении компании), выписка счета (в центральном офисе компании) и т.д. (рис. 1.5.3.1).
Рис. 1.5.3.1. Схема владения «рабочий поток» 3. Схема владения «повсеместное обновление» создает равноправную среду, в которой множество сайтов имеют одинаковые права на обновление реплицируемых данных. В результате локальные сайты получают возможность работать автономно даже в тех случаях, когда другие сайты недоступны. Однако, разделение права владения может вызвать возникновение в системе конфликтов, поэтому служба репликации в этой схеме должна использовать тот или иной метод выявления и разрешения конфликтов. Моментальные снимки таблиц Метод моментальных снимков таблиц позволяет асинхронно распространять результаты изменений, выполненных в отдельных таблицах, группах таблиц, представлениях или фрагментах таблиц в соответствии с заранее установленным графиком (например, ежедневно в 23.00). Реализован в СУБД Oracle 8. Общий подход к созданию моментальных снимковсостоит в использовании файла журналавосстановлениябазыданных, что позволяет минимизировать уровень дополнительной нагрузки на систему. Основная идея состоит в том, что файл журнала восстановления является лучшим источником для получения сведений об изменениях в исходных данных. Достаточно иметь механизм, который будет обращаться к файлу журнала для выявления изменений в исходных данных, после чего распространять обнаруженные изменения на целевые базы данных, не оказывая никакого влияния на нормальное функционирование исходной системы. Для отправки сведений об изменениях на другие сайты целесообразно применять методорганизацииочередей. Если произойдет отказ сетевого соединения или целевого сайта, то сведения об изменениях могут сохраняться в очередях до тех пор, пока соединение не будет восстановлено. Для гарантии сохранения согласованности данных порядокдоставки сведений на целевые сайты должен сохранять исходную очередностьвнесенияизменений. Различные СУБД реализуют механизм моментальных снимков по-разному: в некоторых случаях данный процесс является частью самого сервера СУБД, тогда как в других случаях он реализуется как независимый внешний сервер. Триггеры базы данных Альтернативный подход методу моментальных снимков заключается в предоставлении пользователям возможности создавать приложения, выполняющие репликацию данных с использованием механизма триггеров базы данных. В этом случае на пользователей возлагается ответственность за написание тех триггерных процедур, которые будут вызываться при возникновении соответствующих событий, например, при создании новых записей или обновлении уже существующих. Хотя подобный подход представляет большую гибкость, чем механизм создания моментального снимка, ему также присущи определенные недостатки: 1. Отслеживание запуска и выполнения триггерных процедур создает дополнительную нагрузку на систему. 2. Триггеры взводятся (выполняются) при каждом изменении строки в ведущей таблице. Если ведущая таблица подвержена частым обновлениям, вызов триггерных процедур может создавать существеннуюдополнительнуюнагрузку на приложения и сетевые соединения. В противоположность этому, при использовании моментальных снимков все выполненные изменения пересылаются за одну операцию. 3. Триггеры не могут выполняться в соответствии с некоторым графиком. Онивыполняютсявтотмомент, когдапроисходитобновлениеданныхвведущейтаблице. Моментальные снимки могут создаваться в соответствии с установленным графиком или даже вручную. В любом случае это позволяет исключить дополнительную нагрузку от репликации данных в периоды пиковой нагрузки на систему. 4. Если реплицируется несколько связанных таблиц, синхронизация их репликации может быть достигнута за счет использования механизма групповых обновлений. Решить эту задачу с помощью триггеров существенно сложнее. 5. Аннулирование результатов выполнения триггерной процедуры в случае отмены или отката транзакции – достаточно сложная зад
|
||
|
|
Последнее изменение этой страницы: 2017-02-05; просмотров: 1539; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.214 (0.02 с.) |