
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Графическое изображение рядов распределения.Содержание книги
Поиск на нашем сайте Графики являются наглядной формой отображения рядов распределения. Для изображения рядов применяются линейные графики и плоскостные диаграммы, построенные в прямоугольной системе координат. Для графического представления атрибутивных рядов распределения используются различные диаграммы: столбиковые, линейные, круговые, фигурные, секторные и т. д. Для дискретных вариационных рядов графиком является полигон распределения. Полигоном распределения называется ломаная линия, соединяющая точки с координатами График строится в принятом масштабе. Вид полигона распределения приведен на рис. 5.1.
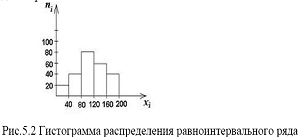
Для изображения интервальных вариационных рядов применяют гистограммы, представляющие собой ступенчатые фигуры, состоящие из прямоугольников, основания которых равны ширине интервала Для графического представления вариационных рядов может использоваться также кумулята – ломаная линия, составленная по накопленным частотам (частостям). Накопленные частоты наносятся в виде ординат; соединяя вершины отдельных ординат отрезками прямой, получаем ломаную линию, имеющую неубывающий вид. Координатами точек на графике для дискретного ряда являются При построении графиков рядов распределения большое значение имеет соотношение масштабов по оси абсцисс и оси ординат. В этомслучае и необходимо руководствоваться «правилом золотого сечения», всоответствии с которым высота графика должна быть примерно в два раза меньше его основания. При проведении эмпирического исследования ряда распределения рассчитываются и анализируются следующие группы показателей: • показатели положения центра распределения; • показатели степени его однородности; • показатели формы распределения. Показатели положения центра распределения. К ним относятся степенная средняя в виде средней арифметической и структурные средние – мода и медиана. Средняя арфметическая для дискретного ряда распределения рассчитывается по формуле:
В отличие от средней арифметической, рассчитываемой на основе всех вариант, мода и медиана характеризует значение признака у статистической единице, занимающей определенное положение в вариационном ряду. Медиана ( Me ) - значение признака у статистической единицы, стоящей в середине ранжированного ряда и делящей совокупность на две равные по численности части. Мода (Mo) - наиболее часто встречаемое значение признак в совокупности. Мода широко используется в статистической практике приизучении покупательского спроса, регистрации цен и др. Для дискретных вариационных рядов Mo и Me выбираются в соответствии с определениями: мода - как значение признака с наибольшей частотой Медиану используют как наиболее надежный показатель типичного значения неоднородной совокупности, так как она нечувствительна ккрайним значениям признака, которые могут значительно отличаться отосновного массива его значений. Кроме этого, медиана находитпрактическое применение вследствие особого математического свойства: Данные приведены в таблице 5.2.
Мода выбирается по максимальному значению частоты: при n max = 14 Mo =4, т.е. чаще всего встречается 4-ый разряд. Для нахождения медианы Me определяются центральные единицы Мода определяется следующим образом: • По максимальному значению частоты определяется интервал, в котором находится значение моды. Он называется модальным. • Внутри модального интервала значение моды вычисляется по формуле:
Для расчета медианы в интервальных рядах используется следующий подход: • По накопленным частотам находится медианный интервал. Медианным называется интервал, содержащий центральную единицу. • Внутри медианного интервала значение Me определяется по формуле:
В неравноинтервальных рядах при вычислении Mo используется другая частотная характеристика – абсолютная плотностьраспределения:
Расчет моды и медианы для интервального ряда распределения рассмотрим на примере ряда распределения рабочих по стажу, приведенного в таблице 5.3.
Расчет Mo: • Максимальная частота n max = 13, она соответствует четвертой группе, следовательно, модальным является интервал с границами 12 – 16 лет. • Моду рассчитаем по формуле:
Чаще всего встречаются рабочие со стажем работы около 13 лет. Мода не находится в середине модального интервала, она смещена к его нижней границе, связано это со структурой данного ряда распределения (частота предмодального интервала значительно больше частоты постмодального интервала). Расчет медианы: • По графе накопленных частот определяется медианный интервал. Он содержит 25 и 26-у статистические единицы, которые находятся в разных группах – в 3-ей и 4-ой. Для нахождения Me можно использовать любую из них. Расчет проведем по 3-ей группе:
Такое же значение Me можно получить при её расчете по 4-ой группе:
При сдвоенном центре Me всегда находится на стыке интервалов, содержащих центральные единицы. Вычисленное значение Me показывает, что у первых 25 рабочих стаж работы – менее 12 лет, а у оставшихся 25-ти, следовательно, - более 12 лет. Моду можно определить графически по полигону распределения в дискретных рядах, по гистограмме распределения – в интервальных, а медиану - по кумуляте. Для нахождения моды в интервальном ряду правую вершину модального прямоугольника нужно соединить с правым верхним углом предыдущего прямоугольника, а левую вершину – с левым верхним углом последующего прямоугольника. Абсцисса точки пересечения этих прямых и будет модой распределения. Для определение медианы высоту наибольшей ординаты кумуляты, соответствующей общей численности совокупности, делят пополам. Через полученную точку проводят прямую, параллельную оси абсцисс, до пересечения ее с кумулятой. Абсцисса точки пересечения является медианой. Кроме Mo и Me в вариантных рядах могут быть определены и другие структурные характеристики – квантили. Квантили предназначены для более глубокого изучения структуры ряда распределения. Квантиль – это значение признака, занимающее определенное место в упорядоченной по данному признаку совокупности. Различают следующие виды квантилей: • квартили • децили • перцентели - значения признака, делящие совокупность на 100 равных частей. Если данные сгруппированы, то значение квартиля определяется по накопленным частотам: номер группы, которая содержит i -ый квантиль. Определяется как номер первой группы от начала ряда, в котором сумма накопленных частот равна или превышает i ·N, где I – индекс квантиля. Если ряд интервальный, то значение квантиля определяется по формуле:
Рассчитаем квартили для ряда распределения рабочих участка по стажу работы:
Следовательно, у четверти рабочих стаж менее 7 лет и у четверти – более 16 лет. Таким образом, для характеристики положения центра ряда распределения можно использовать 3 показателя: среднее значение признака, мода, медиана. При выборе вида и формы конкретного показателя центра распределения необходимо исходить из следующих рекомендаций: • для устойчивых социально-экономических процессов в качестве показателя центра используют среднюю арифметическую. Такие процессы характеризуются симметричными распределениями, в которых
• для неустойчивых процессов положение центра распределения характеризуется с помощью Mo или Me. Для асимметричных процессов предпочтительной характеристикой центра распределения является медиана, поскольку занимает положение между средней арифметической и модой. Вторая важнейшая задача при определении общего характера распределения – это оценка степени его однородности. Однородность статистических совокупностей характеризуется величиной вариации (рассеяния) признака, т.е. несовпадением его значений у разных статистических единиц. Для измерения вариации в статистике используются абсолютные и относительные показатели. Выяснение общего характера распределения предполагает не только оценку степени его однородности, но и исследование формы распределения, т.е. оценку симметричности и эксцесса. Из математической статистики известно, что при увеличении объема статистической совокупности В статистике различают следующие виды кривых распределения: • одновершинные кривые; • многовершинные кривые. Однородные совокупности описываются одновершинными распределениями. Многовершинность распределения свидетельствует о неоднородности изучаемой совокупности или о некачественном выполнении группировки. Одновершинные кривые распределения делятся на симметричные, умеренно асимметричные и крайне асимметричные. Распределение называется симметричным, если частоты любых 2-х вариантов, равноотстоящих в обе стороны от центра распределения, равны между собой. В таких распределениях Для характеристики асимметрии используют коэффициенты асимметрии. Наиболее часто используются следующие из них: • Коэффициент асимметрии Пирсона В одновершинных распределениях величина этого показателя изменяется от -1 до +1. в симметричных распределениях As=0. При As>0 наблюдается правосторонняя асимметрия (рис.5.4). В распределениях с правосторонней асимметрией Mo ≤ Me ≤
Рис. 5.4.Правосторонняя асимметрия Рис. 5.5. Левосторонняя асимметрия Чем ближе по модулю As к 1, тем асимметрия существеннее:
Коэффициент асимметрии Пирсона характеризует асимметрию только в центральной части распределения, поэтому более распространенным и более точным является коэффициент асимметрии, рассчитанный на основе центрального момента 3-его порядка:
Центральным моментом в статистике называется среднее отклонение индивидуальных значений признака от его среднеарифметической величины. Центральный момент k-ого порядка рассчитывается как:
Соответственно формулы для определения центрального момента третьего порядка имеют следующий вид:
Для оценки существенности рассчитанного вторым способом коэффициента асимметрии определяется его средняя квадратическая ошибка:
Для одновершинных распределений рассчитывается еще один показатель оценки его формы – эксцесс. Эксцесс является показателем островершинности распределения. Он рассчитывается для симметричных распределений на основе центрального момента 4-ого порядка
При симметричных распределениях Ех=0. если Ех>0, то распределение относится к островершинным, если Ех<0 – к плосковершинным. Виды и формы связи. Современная наука об обществе объясняет суть явлений через изучение взаимосвязей явлений. Объем продукции предприятия связан с численностью работников, стоимостью основных фондов и т.д. Различают два типа взаимосвязей между различными явлениями и их признаками: функциональную или жестко детерминированную и статистическую или стохастически детерминированную. Функциональная связь – это вид причинной зависимости, при которой определенному значению факторного признака соответствует одно или несколько точно заданных значений результативного признака. Например, при у = Цx – связь между у и х является строго функциональной, но значению х = 4 соответствует не одно, а два значения y1 = +2; y2= -2. Стохастическая связь – это вид причинной зависимости, проявляющейся не в каждом отдельном случае, а в общем, в среднем, при большом числе наблюдений. Например, изучается зависимость роста детей от роста родителей. В семьях, где родители более высокого роста, дети в среднем ниже, чем родители. И, наоборот, в семьях, где родители ниже ростом, дети в среднем выше, чем родители. Еще один пример: потребление продуктов питания пенсионеров зависит от душевого дохода: чем выше доход, тем больше потребление. Однако такого рода зависимости проявляются лишь при большом числе наблюдений. Корреляционная связь – это зависимость среднего значения результативного признака от изменения факторного признака; в то время как каждому отдельному значению факторного признака Х может соответствовать множество различных значений результативного (Y). Задачами корреляционного анализа являются: 1) изучение степени тесноты связи 2 и более явлений; 2) отбор факторов, оказывающих наиболее существенное влияние на результативный признак; 3) выявление неизвестных причинных связей. Исследование корреляционных зависимостей включает ряд этапов: 1) предварительный анализ свойств совокупности; 2) установление факта наличия связи, определение ее направления и формы; 3) измерение степени тесноты связи между признаками; 4) построение регрессионной модели, т.е. нахождение аналитического выражения связи; 5) оценку адекватности модели, ее экономическую интерпретацию и практическое использование. Корреляционная связь между признаками может возникать различными путями. Важнейший путь - причинная зависимость результативного признака (его вариации) от вариации факторного признака. Например, Х – балл оценки плодородия почв, Y – урожайность сельскохозяйственной культуры. Здесь ясно, какой признак выступает как независимая переменная (фактор), а какой как зависимая переменная (результат). Очень важно понимать суть изучаемой связи, поскольку корреляционная связь может возникнуть между двумя следствиями общей причины. Здесь можно привести множество примеров. Так, классическим является пример, приведенный известным статистиком начала XX в. А.А. Чупровым. Если в качестве признака Х взять число пожарных команд в городе, а за признак Y – сумму убытков в городе от пожаров, то между признаками Х и Y в городах обнаружится значительная прямая корреляция. В среднем, чем больше пожарников в городе, тем больше убытков от пожаров. В чем же дело? Данную корреляцию нельзя интерпретировать как связь причины и следствия, оба признака – следствия общей причины – размера города. В крупных городах больше пожарных частей, но больше и пожаров, и убытков от них за год, чем в мелких. Современный пример. Сразу после 17 августа 1998 г. резко возросли цена валюты и объем покупки валюты частными лицами. Здесь также нельзя рассматривать эти два явления как причину и следствие. Общая причина – обострение финансового кризиса, приведшее к росту курсовой стоимости валюты и стремлению населения сохранить свои накопления в твердой валюте. Такого рода корреляцию называют ложной корреляцией. Корреляция возникает и в случае, когда каждый из признаков и причина, и следствие. Например, при сдельной оплате труда существует корреляция между производительностью труда и заработком. С одной стороны, чем выше производительность труда, тем выше заработок. С другой – высокий заработок сам по себе является стимулирующим фактором, заставляющим работника трудиться более интенсивно. По направлению выделяют связь прямую и обратную, по аналитическому выражению – прямолинейную и нелинейную. В начальной стадии анализа статистических данных не всегда требуются количественные оценки, достаточно лишь определить направление и характер связи, выявить форму воздействия одних факторов на другие. Для этих целей применяются методы приведения параллельных данных, аналитических группировок и графический. Метод приведения параллельных данных основан на сопоставлении 2 или нескольких рядов статистических величин. Такое сопоставление позволяет установить наличие связи и получить представление о ее характере. Сравним изменения двух величин (табл. 1).
|
||
|
|
Последнее изменение этой страницы: 2016-04-20; просмотров: 1035; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.108 (0.013 с.) |

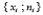 или
или  где
где  - дискретное значение признака,
- дискретное значение признака,  - частота,
- частота,  - частость.
- частость.

 , а высота - частоте
, а высота - частоте  (частости
(частости  ) равноинтервального ряда или плотности распределения неравноинтервального
) равноинтервального ряда или плотности распределения неравноинтервального  Построение диаграммы аналогично построению столбиковой диаграммы. Общий вид гистограммы приведен на рис. 5.2.
Построение диаграммы аналогично построению столбиковой диаграммы. Общий вид гистограммы приведен на рис. 5.2. для интервального ряда -
для интервального ряда -  Начальная точка графика имеет координаты
Начальная точка графика имеет координаты  самая высокая точка -
самая высокая точка -  Общий вид кумуляты приведен на рис.5.3. Использование кумуляты особенно удобно при проведении сравнений вариационных рядов.
Общий вид кумуляты приведен на рис.5.3. Использование кумуляты особенно удобно при проведении сравнений вариационных рядов.
 : положение медианы при нечетном объеме совокупности определяется ее номером
: положение медианы при нечетном объеме совокупности определяется ее номером  , где N – объем статистической совокупности. При четном объеме ряда медиана равна средней из двух вариантов, находящихся в середине ряда.
, где N – объем статистической совокупности. При четном объеме ряда медиана равна средней из двух вариантов, находящихся в середине ряда. Рассмотрим определение моды и медианы на следующем примере:имеется ряд распределения рабочих участка по уровню квалификации.
Рассмотрим определение моды и медианы на следующем примере:имеется ряд распределения рабочих участка по уровню квалификации.
 Это 25 и 26-ая единицы. По накопленным частотам определяется группа, в которую попадают эти единицы. Это 4-ая группа, в которой значение признака равно 4. Таким образом, Me = 4, это означает, что у половины рабочих разряд ниже 4-го, а у другой – выше четвертого. В интервальном ряду значения Mo и Me вычисляются более сложным путем.
Это 25 и 26-ая единицы. По накопленным частотам определяется группа, в которую попадают эти единицы. Это 4-ая группа, в которой значение признака равно 4. Таким образом, Me = 4, это означает, что у половины рабочих разряд ниже 4-го, а у другой – выше четвертого. В интервальном ряду значения Mo и Me вычисляются более сложным путем.







 – значения признака, делящие упорядоченную совокупность на 4 равные части;
– значения признака, делящие упорядоченную совокупность на 4 равные части; – значения признака, делящие совокупность на 10 равных частей;
– значения признака, делящие совокупность на 10 равных частей;


 и одновременного уменьшении интервала группировки
и одновременного уменьшении интервала группировки  полигон либо гистограмма распределения все более и более приближается к некоторой плавной кривой, являющейся для указанных графиков пределом. Эта кривая называется эмпирической кривой распределения и представляет собой графическое изображение в виде непрерывной линии изменения частот, функционально связанного с изменением вариант.
полигон либо гистограмма распределения все более и более приближается к некоторой плавной кривой, являющейся для указанных графиков пределом. Эта кривая называется эмпирической кривой распределения и представляет собой графическое изображение в виде непрерывной линии изменения частот, функционально связанного с изменением вариант.

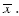 При As<0 – асимметрия отрицательная левосторонняя, Mo>Me>
При As<0 – асимметрия отрицательная левосторонняя, Mo>Me> 












