
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Интерфейс отладочного модуля ⇐ ПредыдущаяСтр 3 из 3
Интерфейс может быть построен по принципу двух окон – «входное» и «выходное». Необходимо иметь возможность вручную вводить декодируемую двоичную последовательность (неискаженное слово кода, искаженное слово, вектор ошибки) и получать в выходном окне результат декодирования (вид синдрома[4], структуру вычисленной (предполагаемой) ошибки или исправленное слово кода, в зависимости от конкретного варианта задания и Вашего решения).
5.2 Элементарный план отладки декодирующего модуля 1) Взять 3–4 вектора кода V 1, V 2, V 3, V 4 и убедиться, что они дают нулевой остаток; 2) Подействовать на эти векторы ошибками. Имея в виду, что искажение многочлена V j(х) моделируется операцией F jℓ(х)= V j(х)+ E ℓ(х), где многочлен E ℓ(х) символизирует ℓ -тую конфигурацию ошибок, результат вычисления синдрома (остатка) R jℓ(x)= F jℓ(х)/ G (x) можно представить как R ℓ(x)= E ℓ(х)/ G (x) [5] Следовательно, при правильном функционировании программы DECODER должны получиться остатки, подчиняющиеся следующей схеме (табл. 4).
Таблица 4
Если поведение DECODER`а подчиняется таблице 4, его можно принять для дальнейшей работы в соответствии с индивидуальным заданием. 5.3 Вариант DECODER`а с обнаружением ошибок
Исходя из характеристик G (x) и величины d0, предложить конфигурации ошибок, которые программа непременно должна обнаруживать и которые не обязана обнаруживать. Особое внимание следует обратить на конфигурации ошибок типа «пачка», вес которых находится в пределах (n-k) ³ w(E) > (d0-1). Найти конфигурации необнаруживаемых ошибок, сформулировать свойства (признаки) таких ошибок; Результаты исследования свести в таблицу и снабдить комментариями.
5.4 Вариант DECODER`а с исправлением ошибок
Исходя из характеристик G (x) и величины d0, предложить конфигурации ошибок, которые иллюстрируют свойства кода в отношении исправления ошибок. Подобрать конфигурации, ведущие к «неправильному исправлению», т.е. к вручению получателю кодового слова с незамеченными ошибками, которые остаются после формально выполненной процедуры исправления.
Защита результатов, отчет по лабораторной работе
Результаты работы программы DECODER должны быть продемонстрированы преподавателю. Отчет должен содержать краткое изложение постановки задачи, требуемые параметры выходного кода, граф-схему алгоритма работы основного декодирующего модуля с комментариями, объем и результаты тестового декодирования (например, в табличной форме) с подробными комментариями.
Быстрый кодер / декодер для циклических кодов
Применение быстрого алгоритма в лабораторной работе не является обязательным для всех. Он может быть использован по желанию студентов или по прямому указанию преподавателя. Выше говорилось, что при циклическом кодировании основной операцией алгоритмов кодирования входной последовательности А (х) и декодирования выходной является операция деления выражения А (х) х(n-k) на порождающий многочлен с целью нахождения остатка, который суммируется с А (х) х(n-k) по mod2. Трудность программной реализации кодирующих и декодирующих модулей для циклических кодов состоит в том, что алгоритмы, обычно, предусматривают процедуру многократно повторяемого «битового деления». Время кодирования /декодирования часто оказывается неприемлемым. Далее излагается математическая суть алгоритма деления двоичных последовательностей, позволяющего выполнять деление по частям. «Крупностью» частей в известных пределах можно варьировать, добиваясь оптимизации процедуры в конкретных условиях.
Алгоритм деления по частям
Разобьем k ‑битовую последовательность А, выраженную многочленом А (х), на ℓ‑ битовые отрезки (блоки). Так как в общем случае k не обязано быть кратным ℓ, входная последовательность будет поделена на s блоков, из которых последний имеет длину m 0 <ℓ. Выполняется условие: k =ℓ (s ‑1)+ m 0. Шаг 1 Выделим в последовательности А левые ℓ бит. Пусть в символике многочленов они выражаются многочленом А 1(х), а оставшуюся (справа) часть обозначим А `1(х). Тогда входную последовательность А (х) можно представить в форме: А (х)= А 1(х) х(k-ℓ) + А `1(х). (1)
(Здесь и далее суммирование двоичных многочленов и векторов ведется по mod2). Делимое А (х) х(n-k) в алгоритме кодирования запишем как А (х) х(n-k) =(А 1(х) х(k-ℓ) + А `1(х)) х(n-k) (2)
Векторная иллюстрация к шагу 1. При ℓ =4, k =11 (одиннадцать) пусть А =1101 1000 110. Здесь m 0 =3, А 1 =1101. А 1 (х) х(k-ℓ) в векторной форме выглядит как 1101 0000000, так как умножение на х(k-ℓ) эквивалентно приписыванию справа (k - ℓ) нулей. А `1 =1000 110. Сумма А 1(х) х(k-ℓ) + А `1 = А(х) выглядит как 1101 0000000 1000110 Å
1101 1000110 В выражении (2) первый член суммы в круглых скобках умножим и разделим на порождающий многочлен и произведем умножение обоих членов на х(n-k). Получим:
Дробь Получим: А (х) х(n-k) = Q 1 (х) G (x) х(k-ℓ) + R 1 (x) х(k-ℓ) + А `1 (х) х(n-k) (4)
Старшая степень многочлена Старшая степень остатка R 1(x) не превосходит величины (n-k‑1), а всего второго слагаемого в (4) – величины (n-ℓ-1). Такую же степень имеет и третье слагаемое А `1 (х) х(n-k). Сложим эти два последних члена, сумму обозначим F 1(х). Перепишем (4) в следующем виде: А (х) х(n-k) = Q 1 (х) G (x) х(k-ℓ) + F 1(х) (5)
Рис. 1 иллюстрирует формирование последовательности F 1 в векторной интерпретации всех участвующих величин. Обратим внимание на длину последовательности F 1, на то обстоятельство, что при суммировании векторы R 1 и A `1 «выровнены» со стороны старших разрядов, а F 1 имеет справа (n-k) нулевых бит.
Рис. 1. Формирование последовательности F 1 при векторном представлении величин На этом первый шаг алгоритма деления по частям закончен. Получен F 1(х), куда вошел первый промежуточный остаток R 1(x), контролирующий деление первого блока из ℓ левых бит входной последовательности А (х). Шаг 2 Очередной шаг алгоритма заключается в том, что в F 1(х) выделяем ℓ левых бит. Этот отрезок должен быть обозначен А 2(х). Оставшаяся правая часть F 1(х) – это А `2(х). В соответствии с (3), (4) находим выражение остатка R 2(x) и последовательности F 2(х).
Рис. 2. Формирование последовательности F 2 при векторном представлении величин
На рис. 2 проиллюстрировано получение F 2. Предпринята попытка масштабно отобразить изменение участвующих в деле векторов. Здесь показано, что после второго шага F 2 все еще имеет справа (n-k) нулей. Это эквивалентно допущению, что деление входного вектора А на отрезки длины ℓ двумя шагами не исчерпывается. Делимое (в его стартовом понимании) после второго шага имеет вид:
В общем случае, пока (k-iℓ)≥(n-k) вектор F i должен будет иметь справа (n-k) нулей. Это, как известно, место контрольных бит в словах циклического кодового слова. Они пока не сформированы. Шаг s‑1 В процессе выполнения (s ‑1) – го шага мы оперируем векторами длины (n - k + m 0) (см. рис. 3). К этому времени все отрезки длины ℓ в составе входного вектора будут исчерпаны и (если в общем случае k не делится нацело на ℓ) у нас остаётся от входной последовательности вычисленный остаток R s -1 и «правый» отрезок A `s-1 длины m0<ℓ.
В соответствии с выражениями (4) и (5) получим «выходной продукт» данного шага – многочлен F s -1 (х) = R s -1 (x) x ( k -( s -1)ℓ) + A ` s -1 (х) х( n - k ) = R s -1 (x) x ( m 0) + A ` s -1 (х) х( n - k ), т. к. k =(s ‑1)ℓ+ m 0 по определению этих величин.
Рис. 3. Формирование последовательности F s -1 при векторном представлении величин
Обозначим последние формирующиеся (n-k) бит Y (х). Как мы видели до (s‑1) – го шага Y (х)=0. Следовательно, Y (х) можно ввести в (6) как нулевое слагаемое, если пределы суммирования ограничить величиной (s-u‑1). После шага s можно записать
Здесь Алгоритм кодирования
Известно на старте: – длина выходных кодовых слов n; – длина входной последовательности k; – число контрольных бит (n-k)=r; – порождающий многочлен G (x); Назначается величина ℓ≤ r. Вычисляются параметры s и m0. В памяти машины организуется 2 ℓ строк («мест»). В каждую строку для каждой конфигурации двоичного отрезка длины ℓ пишется остаток, вычисленный заранее по изложенному выше алгоритму. В процессе кодирования процедура деления заменяется считыванием из памяти остатка для очередного ℓ -отрезка кодируемой последовательности. Это существенно повышает быстродействие программного кодера при (обычно) приемлемом расходе памяти. Желательно так писать программу, чтобы ℓ -отрезок мог выступать в роли «смещения» по адресному пространству списка остатков. Алгоритм кодирования сводится к следующему. 1. Из исходной k‑ битовой информационной последовательности со стороны левых («старших») разрядов выделяется отрезок длины ℓ и из таблицы выбирается соответствующий ему остаток. 2. Полученный остаток суммируется по mod2 с левыми разрядами оставшейся части блока длиной (k-ℓ) бит. 3. Из полученной суммы со стороны левых разрядов выделяется очередной ℓ -отрезок, для которого из таблицы считывается соответствующий остаток и т.д. 4. Через (s‑1) таких шагов из полученной суммы выделяются m0 старших разрядов ℓ-m0 и для сформированной ℓ- разрядной комбинации выбирается соответствующий остаток из таблицы.
5. Полученный остаток суммируется по mod 2 с оставшимися (после выделения m0 разрядов) битами. Эта сумма является комбинацией проверочных разрядов циклического кода.
8. Содержательный пример [3]
Методом деления по частям построить кодер для циклического (15,11) – кода, заданного порождающим многочленом G (x)=х4+х+1. Здесь n =15; k =11. Выбираем ℓ =4. Тогда s =3, m0 =3. Всего имеем 2 ℓ различных конфигураций ℓ -отрезков. Остатки, соответствующие этим отрезкам, вычисленные в соответствии с алгоритмом деления по частям, приведены в табл. 1. Пусть входная (информационная) последовательность, разделенная на отрезки, имеет вид: 1101 1000 110 Выбираем первый ℓ -отрезок 1101 и выбираем из таблицы соответствующий остаток 0100. Складываем по mod 2 со следующим отрезком 0100+1000=1100. Полученной сумме соответствует остаток 0111. Поскольку сделано уже (s‑1) шагов, прибавим этот остаток к оставшимся трем битам 0111+110=1011. На этот результат понадобится ссылка, поэтому присвоим ему наименование U s-1. Из полученной суммы выделим m0 левых бит и дополним их слева нулями до размерности ℓ (в данном случае – одним нулем). Получим 0101. Из таблицы найдем остаток – 1111. Выполняется s ‑й шаг деления. Оставшуюся «1» (справа) от U s-1, из которого выделяли m0 левых бит, сложим со стороны старших разрядов с только – что полученным остатком 1111+1=0111. Это и есть контрольные биты к информационной последовательности 1101 1000 110. Результат можно проверить традиционным делением последовательности А (х) х( n - k ) на G (x) (в нашем случае 1101 1000 110 0000 на 10011).
Табл. 1. Остатки для ℓ -отрезков информационной последовательности
Использованная литература
1. М.Н. Аршинов, Л.Е. Садовский Коды и математика (рассказы о кодировании).-М.: Наука, Главная редакция физико-математической литературы, 1983. – 144 с. 2. Блейхут Р. Теория и практика кодов, контролирующих ошибки: Пер. с англ. ‑ М.: Мир, 1986. – 576 с. 3. Гончаров Е.А, Слепаков В.Б. Об одном методе кодирования информации циклическими кодами на универсальной ЭВМ. – В кн.: Сб научных трудов ЦНИИС. М., 1970, вып. 3, с. 58–65. 4. В.С. Чернега, В.А. Василенко, В.Н. Бондарев Расчет и проектирование технических средств обмена и передачи информации: Учебное пособие для вузов. – М.: Высш. шк., 1990. –224 с. [1] Здесь и всюду далее операции суммирования выполняются по mod2. [2] Вообще говоря, такой метод тестирования большого доверия не заслуживает не только из-за малого числа проверяемых векторов, но и из-за кодирования входных векторов «порознь», а не путем их «извлечения» из файла произвольного формата. На вспомогательных операциях легко привнести ошибку в кодирование. Однако, из-за ограниченности времени таким поверхностным тестированием придется удовлетвориться. Можно написать исходный файл известной двоичной структуры и искать несложные приемы просмотра двоичной структуры выходного файла, структура которого тоже становится наперед известной.
[3] Интерфейсы основной и вспомогательной программ, разумеется, могут быть совмещены. [4] Но не значение типа «ноль/не ноль» без раскрытия структуры синдрома. [5] V (х) по определению нацело делится на G (x).
|
||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2019-10-15; просмотров: 107; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.93.210 (0.062 с.) |

 (3)
(3) представим как меньшую целую часть (частное) Q 1 (х), которое в конечном итоге нас не интересует, плюс остаток от деления R 1 (х). С учетом этого перепишем (3).
представим как меньшую целую часть (частное) Q 1 (х), которое в конечном итоге нас не интересует, плюс остаток от деления R 1 (х). С учетом этого перепишем (3). не превосходит (ℓ-1), т. к. такую степень по соглашению имеет А 1(х), а G (x) имеет фиксированную степень (n-k) по определению (вывернутые полускобки символизируют ближайшее меньшее целое от дроби, т.е. частное). Тогда получается, что первое слагаемое в (4) имеет старшую возможную степень (n‑1), что соответствует вектору длины n.
не превосходит (ℓ-1), т. к. такую степень по соглашению имеет А 1(х), а G (x) имеет фиксированную степень (n-k) по определению (вывернутые полускобки символизируют ближайшее меньшее целое от дроби, т.е. частное). Тогда получается, что первое слагаемое в (4) имеет старшую возможную степень (n‑1), что соответствует вектору длины n.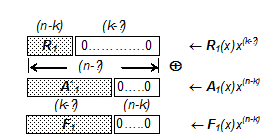

 (6)
(6)
 (7)
(7) т.е. является проверочными битами кодового слова.
т.е. является проверочными битами кодового слова.


