Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Какие виды неопределенности выделяют.Стр 1 из 8Следующая ⇒
Введение
Наиболее поразительным свойством человеческого интеллекта является способность принимать правильные решения в обстановке неполной и нечеткой информации. Построение моделей приближенных рассуждений человека и использование их в компьютерных системах будущих поколений представляет сегодня одну из важнейших проблем науки. При изучении сложных систем, где человек играет существенную роль, действует так называемый принцип несовместимости [1]: для получения существенных выводов о поведении сложной системы необходимо отказаться от высоких стандартов точности и строгости, которые характерны для сравнительно простых систем, и привлекать к ее анализу подходы, которые являются приближенными по своей природе. При попытке формализовать человеческие знания исследователи столкнулись с проблемой, затруднявшей использование традиционного математического аппарата для их описания. Существует целый класс описаний, оперирующих качественными характеристиками объектов (много, мало, сильный, очень и т. п.) Эти характеристики обычно размыты и не могут быть однозначно интерпретированы, однако содержат важную информацию (например, «Одним из возможных признаков гриппа является высокая температура»). Категория нечеткости и связанные с ней модели и методы очень важны с мировоззренческой точки зрения, поскольку с их появлением стало возможно подвергать количественному анализу те явления, которые раньше либо могли быть учтены только на качественном уровне, либо требовали использования весьма грубых моделей. Значительное продвижение в этом направлении сделано примерно 35 лет тому назад профессором Калифорнийского университета (Беркли) Лотфи А. Заде (Lotfi A. Zadeh). Его работы легли в основу моделирования интеллектуальной деятельности человека и явились начальным толчком к развитию новой математической теории. Что же предложил Заде? Во-первых, он расширил классическое понятие множества, допустив, что характеристическая функция (функция принадлежности элемента множеству) может принимать любые значения в интервале (0;1), а не только значения 0 либо 1. Такие множества были названы им нечеткими (fuzzy). Л.Заде определил также ряд операций над нечеткими множествами и предложил обобщение известных методов логического вывода modus ponens и modus tollens.
Введя затем, понятие лингвистической переменной и допустив, что в качестве ее значений (термов) выступают нечеткие множества, Л.Заде создал аппарат для описания процессов интеллектуальной деятельности, включая нечеткость и неопределенность выражений. Вот точка зрения Л.Заде: "Я считаю, что излишнее стремление к точности стало оказывать действие, сводящее на нет теорию управления и теорию систем, так как оно приводит к тому, что исследования в этой области сосредоточиваются на тех и только тех проблемах, которые поддаются точному решению. В результате многие классы важных проблем, в которых данные, цели и ограничения являются слишком сложными или плохо определенными для того, чтобы допустить точный математический анализ, оставались и остаются в стороне по той причине, что они не поддаются математической трактовке. Для того чтобы сказать что-либо существенное для проблем подобного рода, мы должны отказаться от наших требований точности и допустить результаты, которые являются несколько размытыми или неопределенными". Математическая теория нечетких множеств позволяет описывать нечеткие понятия и знания, оперировать этими знаниями и делать нечеткие выводы. Основанные на этой теории методы построения компьютерных нечетких систем существенно расширяют области применения компьютеров и выполнении задач принятия решений. Нечеткая Логика - в основном многозадачная логика, которая позволяет определять промежуточные значения между стандартными оценками подобно Да/Нет, Истина/Ложь, Черное/Белое, и т.д. Понятия подобно "довольно теплый" или "довольно холодный" могут быть сформулированы математически и обработаны компьютерами. Таким образом, сделана попытка применить человекоподобное мышление в программировании компьютера. В последнее время нечеткое управление является одной из самых активных и результативных областей исследований применения теории нечетких множеств. Нечеткое управление оказывается особенно полезным, когда технологические процессы являются слишком сложными для анализа с помощью общепринятых количественных методов, или когда доступные источники информации интерпретируются качественно, неточно или неопределенно. Экспериментально показано, что нечеткое управление дает лучшие результаты, по сравнению с результатами, получаемыми при общепринятых алгоритмах управления. Нечеткие методы помогают управлять домной и прокатным станом, автомобилем и поездом, распознавать речь и изображения, проектировать роботов, обладающих осязанием и зрением. Нечеткая логика, на которой основано нечеткое управление, ближе по духу к человеческому мышлению и естественным языкам, чем традиционные логические системы. Нечеткая логика обеспечивает эффективные средства отображения неопределенностей и неточностей реального мира. Наличие математических средств отражения нечеткости исходной информации позволяет построить модель, адекватную реальности.
Применение нечеткой логики Применение нечеткого управления эффективно... · Для очень сложных процессов, когда имеется сложная математическая модель · Для нелинейных процессов · Если должна выполняться обработка экспертных знаний Применение нечеткого управления не имеет смысла, если... · Стандартная теория управления дает удовлетворяющий результат · Легко разрешимая и адекватная математическая модель уже существует · Проблема не разрешима Рисунок 2 – Характеристическая функция множества молодежи
Из рисунка 2 видно, что в 25 лет вы все еще молоды, но не на все 100%, а всего на 50. Отсюда следует, что в решаемой задаче управления запасами для конкретного ЛПР понятию «небольшой запас деталей на складе» полностью соответствует запас объемом от 20 до 33 деталей, в меньшей степени – запасы от 11 до 19 и от 34 до 40 деталей. Запас объемом меньше 10 и больше 40 деталей понятием «небольшой» охарактеризован быть не может. Для практических приложений носители нечетких множеств всегда ограничены. Так, носителем нечеткого множества допустимых режимов для системы может служить четкое подмножество (интервал), для которого степень допустимости не равна нулю (рис.1.2).
Рис.1.2. Понятие носителя нечеткого множества (выделен жирной чертой)
Высотой d нечеткого множества А называется максимальное значение функции принадлежности этого множества Если d = 1, то нечеткое множество называется нормальным. Ниже будут рассматриваться только нормальные нечеткие множества, так как если нечеткое множество не нормально, то его всегда можно превратить в нормальное, разделив все значения функции принадлежности на ее максимальное значение.
Пусть
где Сравнивая выражения (1.3) и (1.6), можно видеть, что нечеткое отношение – это нечеткое множество с векторной базовой переменной. Примерами нечетких отношений могут служить такие, как «X примерно равен У», «X значительно больше У», «А существенно предпочтительнее, чем В».
Рисунок 2. – Взаимосвязь лингвистической и нечеткой переменных
Нечеткие числа и функции. В зависимости от характера множества U лингвистические переменные могут быть разделены на числовые и нечисловые. Числовой называется лингвистическая переменная, у которой Нечеткие переменные, соответствующие значениям числовой лингвистической переменной, будем называть нечеткими числами. Если Примером нечисловой лингвистической переменной может служить переменная СЛОЖНОСТЬ, формализующая понятие «сложность разработки», со значениями НИЗКАЯ, СРЕДНЯЯ, УМЕРЕННАЯ, ВЫСОКАЯ. К функциям принадлежности нечетких чисел обычно предъявляется ряд требований, которые обсуждаются в § 3.1, 3.2. Пусть четкая функция нечеткого аргумента
нечеткая функция четкого аргумента
нечеткая функция нечеткого аргумента
Использование основных понятий лингвистического подхода — лингвистической переменной и нечеткого множества — с целью формализации нечетких описаний элементов задач ПР, а именно критериев, предпочтений ЛПР, случайных исходов, качественных зависимостей между параметрами альтернатив и оценками исходов, приводит к необходимости рассмотрения лингвистических критериев и отношений предпочтения, лингвистических вероятностей, нечетких свидетельств. 1.5. НЕЧЕТКИЕ ВЫСКАЗЫВАНИЯ. ПРАВИЛА ПРЕОБРАЗОВАНИЯ НЕЧЕТКИХ ВЫСКАЗЫВАНИЙ Нечеткими высказываниями [19] назовем высказывания следующего вида: 1) высказывание <b есть a>, где b — наименование лингвистической переменной, отражающей некоторый объект или параметр реальной действительности, относительно которой производится утверждение a, являющееся ее нечеткой оценкой (нечеткой переменной). Например, (давление большое). В высказывании <толщина равна 14 мм> значение a = 14 мм является четкой оценкой лингвистической переменной b: <толщина>; 2) высказывания вида <b есть ma>, <b есть Qa >, <Qb есть ma>,<mb есть Qa>, при этом m назы вается модификатором (ему соответствуют такие слова, как ОЧЕНЬ, БОЛЕЕ ИЛИ МЕНЕЕ, НЕЗНАЧИТЕЛЬНЫЙ, СРЕДНИЙ и др.), Q - квантификатором (ему соответствуют слова типа БОЛЬШИНСТВО, НЕСКОЛЬКО, МНОГО, НЕМНОГО, ОЧЕНЬ МНОГО и др.). Например, <давление очень большое>, <большинство значений параметра очень мало>;
3) высказывания, образованные из высказываний 1-го и 2-го видов и союзов И; ИЛИ; ЕСЛИ..., ТО...; ЕСЛИ..., ТО... ИНАЧЕ. Например, <ЕСЛИ давление большое, ТО толщина не мала>. Необходимо отметить, что отождествление данных союзов с логическими операциями конъюнкций, дизъюнкций, отрицанием и импликацией возможно только при предварительном рассмотрении опроса коммутативности, ассоциативности и дистрибутивности высказываний, образующих предложения. Предположим, имеются некоторые высказывания C̃ и D̃ относительно ситуации A. Пусть рассматриваемые высказывания имеют вид C̃: <b есть aC> и D̃: <b есть aD>, где aC и aD - нечеткие переменные, определенные на универсальном множестве U = {u} Определение 1.15 Истинность высказывания C̃ и D̃ относительно C̃ есть значение функции T(D̃ / C̃), определяемое степенью соответствия высказываний C̃ и D̃̃̃. В формальной записи T (D̃/C̃) = {< μT(t) /t}, где ("u Î U) (t = μD̃(u)); μT(t) = max μC̃(u), U/ = {u Î U| μD(u) = t }, u Î U/ при этом μD̃ и μС̃ – функции принадлежности нечётких переменных aС̃ aD; μT(t) – функция принадлежности значения истинности; t Î [0,1] – область её определения. Иными словами, истинностью, нечеткого высказывания D относительно нечеткого высказывания С является нечеткое множество T(D/C),определенное на интервале [0,1], такое, что для любого tÎ[0,1] значение ее функции принадлежности равно наибольшему значению μC̃(u) по всем u, при которых μD̃(u) = t. Пример 1.11. Предположим, что сформулировано высказывание D:<b находится близко к 5>, в то время как С: <b имеет значение приблизительно 6>. Пусть aD̃ есть "близко к 5", aC есть "приблизительно 6" суть нечеткие переменные с нечеткими множествами: CC̃ = {<0,1/2>, <0,3/3>, <0,7/4>, <1/5>, <0,8/6>, <0,6/7>, <0,3/8>, <0,1/9>, <0,8/6>, <0,6/7>, <0,3/8>, <0,1/9> }; CD̃ = {<0,1/3>, <0,4/4>, <0,8/5>, <1/6>, <0,7/7>, <0,4/8>, <0,3/9>, <0,1/10>}. В этом случае U= { 2, 3_4, 5, 6, 7, 8, 9, 10 }. Тогда истинность высказывания D относительно С будет иметь следующий вид: Т(D̃/C̃) = {<0,1/0>, <0,3/0,1>, <0,4/0,3>, <0,7/0,6>, <0,4/0,7>, <1/0,8>, <0,8/1>}.
МЕТОДА ЭКСПЕРТНОЙ ОЦЕНКИ
С помощью функции принадлежности можно отразить мнение одного или нескольких экспертов. Это связано с неспособность человека формулировать свое количественное впечатление в виде однозначного числа. Предположим, что имеется m экспертов, часть из которых на вопрос о принадлежности элемента хÎХ нечеткому множеству А отвечает положительно. Обозначим их число n1. Другая часть экспертов n2 = m – n1 отвечает на этот вопрос отрицательно. Тогда принимаем, что функция принадлежности может быть описана выражением
Пример. Пусть имеется множество Х={1, 2, 3, 4, 5, 6} и требуется построить нечеткое множество А формализующее нечеткое понятие "намного больше двух". Решение задачи может выглядеть так. Допустим, что результаты опроса шести экспертов дали такие результаты (таблица 1). Причем если на вопрос о принадлежности элемента хÎХ нечеткому множеству А эксперт отвечает положительно, то в таблицу заносим знак "+", если отрицательно, то знак " – ". Обозначим число положительных знаков как n1, а число отрицательных знаков как n2 = m – n1.
Таблица 1 – Результат опроса экспертов
Используя формулу (1), определяем функцию принадлежности:
Тогда формальная запись нечеткого множества А будет такой:
Рисунок 8 – Функция принадлежности для примера
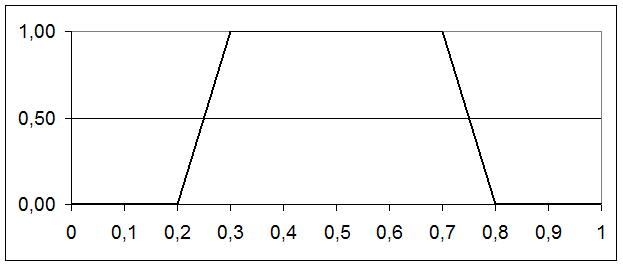
Этап. Ранжирование термов. В данном случае можно выполнить ранжирование типа "по возрастанию". Таким образом, результатом выполнения этапа будет последовательность: 1 – "Вероятность малая"; 2 – "Вероятность средняя"; 3 –"Вероятность большая". 3 этап. Определение интервалов термов (то есть назначение левой и правой границ интервала). В каждом конкретном случае эти границы будут различны. В нашем примере лингвистическая переменная "Вероятность" имеет крайнюю левую границу 0, а крайнюю правую – 1 (по своей сути вероятность меняется от 0 до 1, т.е. вероятность невозможного события равна 0, а вероятность достоверного события равна 1). Промежуточные значения выбираются на основе субъективного суждения. Предположим, что граничные пары значений термов установлены такими, как представлены в таблице 2.
Таблица 2 – Левая и правая границы интервалов термов
4 этап. Графическое изображение установленных границ интервалов термов (рисунок 9).
Рисунок 9 – Границы интервалов
5 этап. Корректировка границ интервалов термов (необязательный этап). 6 этап. Выбор метода построения ФП. В данном примере используем метод деления значений ФП пополам. 7 этап. Определение семантики терма лингвистической переменной. 7.1 Рассмотрим 1 терм: "Вероятность малая". Для него определим значения ФП в граничных точках интервала. В граничной точке 0,0 ФП равна 1, так как если вероятность равна нулю, то она естественно малая и ФП принимает максимальное значение. В граничной точке 0,4 ФП равна 0, так как ранее на основе субъективного суждения мы приняли, что при Р>0,4 вероятность не может быть малой.
Графическая иллюстрация решения задачи показана на рисунке 10 а.
а) б) Рисунок 10 – Значения ФП в граничных точках Нахождение значений ФП в данном интервале. Для этого можно использовать 3, 5, 7, 9 кратное разбиение интервала (следует помнить, что чем больше кратность разбиения, тем выше точность построения ФП). Для простоты воспользуемся 3-х кратным разбиением. Методика разбиения состоит в следующем: · назначьте значение аргумента, для которого значение ФП (0,5) лежит посередине между значениями ФП для точек 0,0 и 0,4. Графическая иллюстрация постановки задачи приведена на рисунке 2 б. Предположим, что это будет значение аргумента равное 0,35 (рисунок 3). · назначьте значение аргумента, для которого значение ФП (0,25) лежит посередине между значениями ФП для точек 0,35 и 0,4. Предположим, что это будет значение аргумента равное 0,38 (рисунок 11).
Рисунок 11 – Значения аргумента, Рисунок 12 – Значения аргумента, Значение 0,5 значение 0,25 · назначьте значение аргумента, для которого значение ФП (0,75) лежит посередине между значениями ФП для точек 0,0 и 0,35. Предположим, что это будет значение аргумента равное 0,12 (рисунок 13).
Рисунок 13 – Значения аргумента, при котором ФП принимает значение 0,75
Таким образом, результаты выполнения предыдущих действий для данного терма будут такими:
Рисунок 14 – Графическое изображение результатов для терма "Вероятность малая"
7.2 Рассмотрим 2 терм и определим семантику терма "Вероятность средняя". Для него определим значения ФП в граничных точках. В этом случае значения ФП равны 0, так как и меньше Р < 0,2 и при Р > 0,8 вероятность не может считаться средней. Граничные значения 0,2 0,8 Значения ФП 0 0 Графически решение этой задачи показано на рисунке 15.
Рисунок 15 – Значения ФП в граничных точках для терма "Вероятность средняя" Нахождение значений ФП в данном интервале. Для простоты воспользуемся 3-х кратным разбиением. Методика разбиения состоит в следующем: · назначьте значение аргумента, при котором ФП уже равна 1, и значение аргумента, при котором она еще равна 1. Предположим, это будут значения аргумента равные 0,3 и 0,7 (рисунок 16).
Рисунок 16 – Значения аргумента, при котором ФП принимает значение 1,0.
· назначьте значение аргумента, для которого значение ФП (0,5) лежит посередине между значениями ФП для точек 0,2 и 0,3. Предположим, что это будет значение аргумента равное 0,27. · назначьте значение аргумента, для которого значение ФП (0,75) лежит посередине между значениями ФП для точек 0,27 и 0,3. Предположим, что это будет значение аргумента равное 0,282. · назначьте значение аргумента, для которого значение ФП (0,25) лежит посередине между значениями ФП для точек 0,2 и 0,27. Предположим, что это будет значение аргумента равное 0,24. Рассмотрим правый полуинтервал для терма "Вероятность средняя". · назначьте значение аргумента, для которого значение ФП (0,5) лежит посередине между значениями ФП для точек 0,7 и 0,8. Предположим, что это будет значение аргумента равное 0,74. · назначьте значение аргумента, для которого значение ФП (0,75) лежит посередине между значениями ФП для точек 0,7 и 0,74. Предположим, что это будет значение аргумента равное 0,72. · назначьте значение аргумента, для которого значение ФП (0,25) лежит посередине между значениями ФП для точек 0,74 и 0,8. Предположим, что это будет значение аргумента равное 0,76. Таким образом, результаты выполнения предыдущих действий для терма "Вероятность средняя" будут такими
Графически это решение показано на рисунке 17.
Рисунок 17 – Вид ФП для терма "Вероятность средняя"
7.3 Рассмотрим 3 терм и определим семантику терма "Вероятность большая". Для него определим значения ФП в граничных точках.
Графически решение этой задачи показано на рисунке 18. Нахождение значений ФП в данном интервале. Методика выполнения данного этапа аналогична 7.1, поэтому представим только конечные результаты. · значение аргумента, для которого значение ФП (0,5) лежит посередине между значениями ФП для точек 0,6 и 1,0 равно 0,7.
Рисунок 18 – Значения ФП в граничных точках для терма "Вероятность большая" · значение аргумента, для которого значение ФП (0,25) лежит посередине между значениями ФП для точек 0,6 и 0,7 равно 0,64. · значение аргумента, для которого значение ФП (0,75) лежит посередине между значениями ФП для точек 0,7 и 1,0 равно 0,85.
Таким образом, результаты выполнения расчетов для данного терма будут такими:
Рисунок 19 – Вид ФП для терма "Вероятность большая"
Вывод. Таким образом, в результате выполнения всех этапов можно построить функцию принадлежности лингвистической переменной "Вероятность" (рисунок 12).
переменной "Вероятность"
МОДЕЛЬНЫЙ ПРИМЕР Для иллюстрации этапов получения решения задачи с помощью метода анализа иерархий рассмотрим гипотетический пример. Для уборки зерновых культур необходимо приобрести зерноуборочный комбайн. На рынке имеются машины нескольких фирм одинакового целевого назначения. Какой зернокомбайн выбрать в соответствии с потребностями покупателя? Другими словами необходимо оценить весомость критериев к машине, которыми пользуется потребитель. Рекомендуется такая последовательность этапов при решении задачи. 1. Очертите проблему и определите, что вы хотите узнать. 2. Постройте иерархию, начиная с вершины (цели - с точки зрения управления), через промежуточные уровни (критерии, по которым зависят последующие уровни) к самому нижнему уровню (который обычно является перечнем альтернатив). 3. Постройте матрицу попарных сравнений для второго уровня. 4. Проверить согласованность, используя отклонение Схема иерархии для рассматриваемой задачи приведена на рисунке. На первом (высшем) уровне находится общая цель: "Зернокомбайн". На втором уровне находятся показатели (критерии), уточняющие цель.
Рисунок 21 – Схема иерархии для решения проблемы выбора зернокомбайна
Примечание 1. В примере на втором уровне рассматриваются четыре критерия. Такое количество выбрано лишь для иллюстрации метода и не связано с сутью рассматриваемой проблемы – выбора лучшего зернокомбайна. Примечание 2. Издавна известны магические свойства числа семь. Так вот в МАИ для проведения обоснованных численных сравнений не рекомендуется сравнивать более чем 7 ± 2 элементов. Если же возникает потребность в расширении уровней 2 и 3, то следует использовать принцип иерархической декомпозиции. Другими словами если число критериев, например, превышает десятки, то необходимо элементы сгруппировать в сравниваемые классы приблизительно из семи элементов в каждом. После выполнения работ на этапе иерархического представления проблемы необходимо установить приоритеты критериев. Для количественного определения сравнительной важности факторов в проблемной ситуации необходимо составить матрицу попарных сравнений. Эта матрица представлена в таблице 1. Таблица 1 – Общий вид матрицы попарных сравнений
Здесь A1, A2, A3,..., An- множество из n элементов; w1, w2, w3,..., wn- соответственно их веса или интенсивности. Примечание 1. Цель составления подобной матрицы заключается в определении факторов с наибольшими величинами важности, чтобы затем сконцентрировать внимание на них при решении проблемы или разработке плана действий. Примечание 2. Если ожидается, что w1, w2,..., wn – неизвестны заранее (а это очень распространенная ситуация), то попарные сравнения элементов производятся с использованием субъективных суждений, численно оцениваемых по шкале (см. приложение). Примечание 3. Следует подчеркнуть, что в МАИ по соглашению сравнивается относительная важность левых элементов матрицы с элементами наверху. Поэтому если элемент слева важнее, чем элемент наверху, то в клетку заносится положительное целое (от 1 до 9); в противном случае – обратное число (дробь, например, 1/5). Относительная важность любого элемента, сравниваемого с самим собой, равна 1; поэтому диагональ матрицы (таблица 1) содержит только единицы. Наконец, обратными величинами заполняют симметричные клетки, т.е. если элемент А1 воспринимается как слегка более важный. (3 на шкале) относительно элемента А2, то считается, что элемент А2 слегка менее важен (1/3 по шкале) относительно элемента А1. Составим матрицу попарных сравнений для нашей задачи (таблица 2). Таблица 2 – Матрица попарных сравнений, построенная на основе субъективных суждений
Синтез приоритетов Одним из способов определения приоритетов является вычисление геометрического среднего. Это можно сделать, перемножая элементы в каждой строке и извлекая корень n-й степени, где n – число элементов. Полученный таким образом столбец чисел нормализуется делением каждого числа на сумму всех чисел. Последовательность расчета составляющих вектора приоритетов приведена в таблице 3. Таблица 3 – Расчет вектора приоритетов
Для нашего примера значения вектора приоритетов (функции принадлежности) приведены в таблице 4.
Таблица 4 – Функция принадлежности
Приложение А Конкретный вид функций принадлежности определяется на основе различных дополнительных предположений о свойствах этих функций (симметричность, монотонность, непрерывность первой производной и т.д.) с учетом специфики имеющейся неопределенности.
Для построения значений ФП используются функции: 1)
Рисунок 22 – ФП для выражения (1) 2)
Рисунок 23 – ФП для выражения (3)
3)
Рисунок 24 – ФП для выражения (3) 4)
Рисунок 25 – ФП для выражения (4) 5)
Рисунок 26 – ФП для выражения (5) 6) Рисунок 27 – ФП для выражения (6)
7)
Рисунок 28 – ФП для выражения (7) Подобно операциям над четкими множествами, нечеткие множества также можно пересекать, объединять и инвертировать. Л. Заде предложил оператор минимума для пересечения и оператор максимума для объединения двух нечетких множеств. Видно, что эти операторы совпадают с объединением и пересечением, если мы рассматриваем только степени принадлежности 0 и 1. ОПЕРАЦИЯ ОБЪЕДИНЕНИЯ Объединением нечетких множеств
где
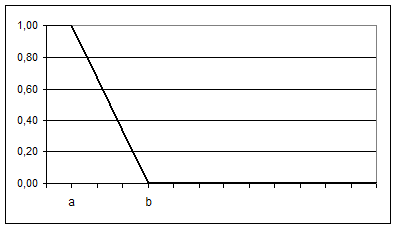
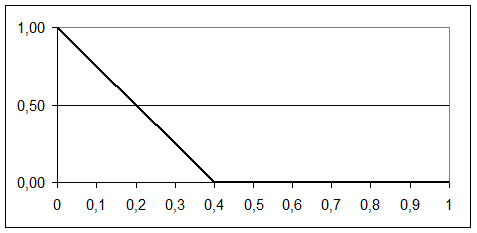
Предположим, на интервале от [0; 0,4] функция принадлежности (ФП) описывается выражением (1):
Графическое изображение функции (1) при a=0 и b=0,4 приведено на рисунке 29.
Рисунок 29 – ФП для выражения (1)
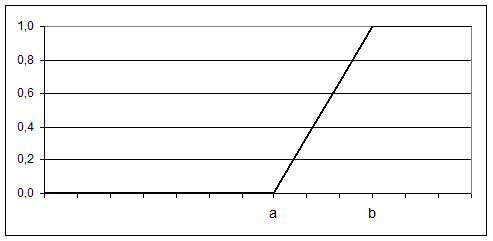
Предположим, на интервале [0,2; 0,8] функция принадлежности описывается выражением (2):
Графическое изображение функции (1) при a=0,2; c=0,3; d=0,7; b=0,8 приведено на рисунке 30.
Рисунок 30 – ФП для выражения (2)
Тогда в результате выполнения операции объединения общий вид ФП будет такой (рисунок 31).
| Поделиться:
| |

 .
. – другое универсальное множество. Нечетким отношением R на множестве
– другое универсальное множество. Нечетким отношением R на множестве  называется совокупность пар
называется совокупность пар , (1.6)
, (1.6) :
:  – функция принадлежности нечеткого отношения R, имеющая тот же смысл, что и функция принадлежности нечеткого множества. Приведенное определение легко обобщается на n-мерный случай.
– функция принадлежности нечеткого отношения R, имеющая тот же смысл, что и функция принадлежности нечеткого множества. Приведенное определение легко обобщается на n-мерный случай. , где
, где  , и которая имеет измеримую базовую переменную.
, и которая имеет измеримую базовую переменную. , то нечеткие числа будем считать дискретными, если же
, то нечеткие числа будем считать дискретными, если же  — то непрерывными. Приведенная выше лингвистическая переменная СКОРОСТЬ является числовой, а нечеткие переменные из ее терм-множества — непрерывными нечеткими числами.
— то непрерывными. Приведенная выше лингвистическая переменная СКОРОСТЬ является числовой, а нечеткие переменные из ее терм-множества — непрерывными нечеткими числами. ,
,  — два универсальных множества;
— два универсальных множества;  — система всех нечетких множеств, заданных на U. Используяданные обозначения, определяем три типа функций:
— система всех нечетких множеств, заданных на U. Используяданные обозначения, определяем три типа функций: , (1.8)
, (1.8) , (1.9)
, (1.9) , (1.10)
, (1.10) . (10)
. (10) ;
;  ;
;  ;
; ;
;  ;
;  .
.
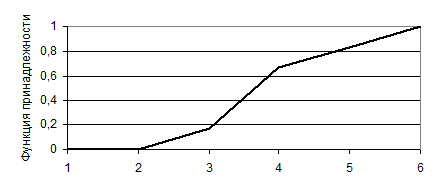
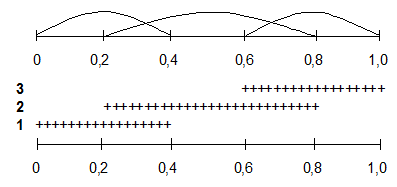
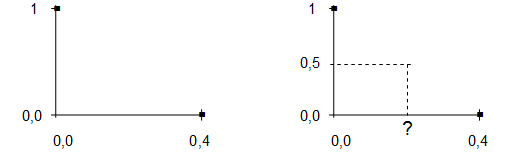

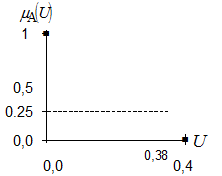







 Рисунок 20 – Общий вид функции принадлежности лингвистической
Рисунок 20 – Общий вид функции принадлежности лингвистической от n.
от n.


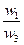





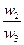



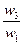








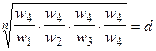

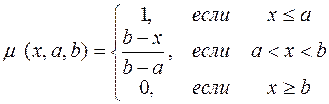 (1)
(1)
 (2)
(2)
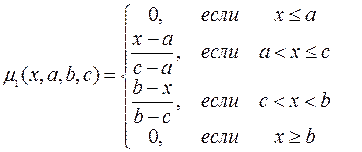 (3)
(3)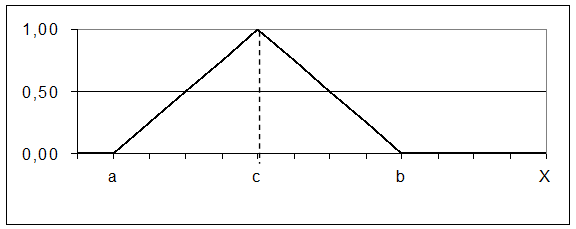
 (4)
(4)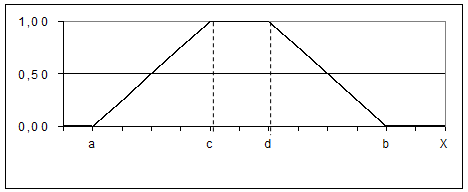
 (5)
(5)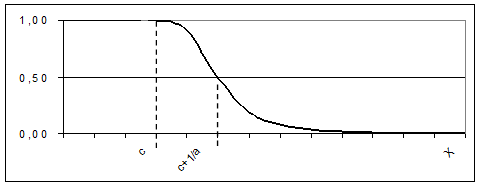
 (6)
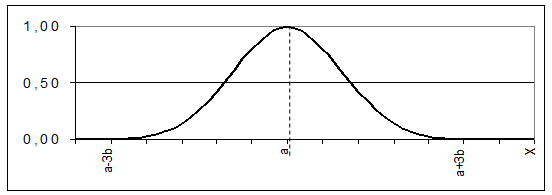
(6)
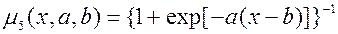 (7)
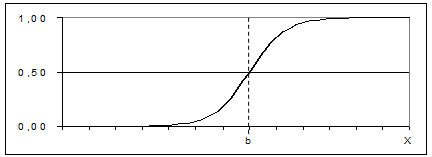
(7)
 и
и 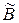 называется множество:
называется множество: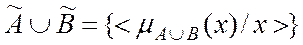 ,
,
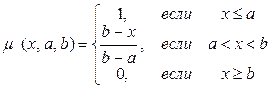 (1)
(1)
 (2)
(2)