Процедуру алгоритма К-средних часто называют «четкой» классификацией. В этом алгоритме каждый объект выборки  либо принадлежит, либо не принадлежит к определенному классу. Алгоритм К-средних может успешно применяться в случае непересекающихся классов, т.е. в случае, когда между классами можно провести четкие границы. В противоположность этому нечеткий алгоритм К-средних реализует «мягкую» или «нечеткую» классификацию и используется в тех случаях, когда не представляется возможным однозначно установить принадлежность объекта к определенному классу. В этом случае говорят, что каждый объект может иметь определенную степень принадлежности к каждому из классов. Например, объект
либо принадлежит, либо не принадлежит к определенному классу. Алгоритм К-средних может успешно применяться в случае непересекающихся классов, т.е. в случае, когда между классами можно провести четкие границы. В противоположность этому нечеткий алгоритм К-средних реализует «мягкую» или «нечеткую» классификацию и используется в тех случаях, когда не представляется возможным однозначно установить принадлежность объекта к определенному классу. В этом случае говорят, что каждый объект может иметь определенную степень принадлежности к каждому из классов. Например, объект  может принадлежать на 20% к первому классу, на 65% ко второму и на 15% к третьему классу, а объект
может принадлежать на 20% к первому классу, на 65% ко второму и на 15% к третьему классу, а объект  - на 70% к первому, на 10% ко второму и на 20% к третьему.
- на 70% к первому, на 10% ко второму и на 20% к третьему.
Нечеткий алгоритм К-средних широко применяется для распознавания и классификации объектов с «нечеткими» признаками, например, в системах компьютерной обработки и распознавания цветных изображений, географии и геодезии при классификации почв и ландшафтов, метеорологии при предсказаниях изменений климата и др.
Идея нечеткого алгоритма К-средних основана на минимизации суммарной взвешенной среднеквадратичной ошибки
 (2.24)
(2.24)
при следующих условиях:
 для любого
для любого  ;
;
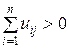 для любого
для любого  ; (2.25)
; (2.25)
 для любых
для любых 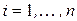 и .
и .
Здесь  – количество объектов в выборке;
– количество объектов в выборке;  – количество классов;
– количество классов;  - «функция принадлежности», т.е. функция, значение которой равно степени принадлежности
- «функция принадлежности», т.е. функция, значение которой равно степени принадлежности  -го объекта к
-го объекта к  -му классу;
-му классу;  - квадрат расстояния между -м объектом и центром -го класса в выбранной метрике (в дальнейшем эту величину будем обозначать просто
- квадрат расстояния между -м объектом и центром -го класса в выбранной метрике (в дальнейшем эту величину будем обозначать просто  ).
).
Параметр  в показателе степени в (2.24) определяет собой «степень нечеткости», «степень размытия» классов, или степень перекрытия классов в конечном решении задачи классификации. При
в показателе степени в (2.24) определяет собой «степень нечеткости», «степень размытия» классов, или степень перекрытия классов в конечном решении задачи классификации. При 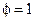 получится “четкая” классификация, а при
получится “четкая” классификация, а при  решение приближается к максимальной степени нечеткости. Выбор параметра
решение приближается к максимальной степени нечеткости. Выбор параметра 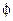 достаточно произволен и при использовании данного алгоритма обычно требуется многократно провести процедуру классификации для различных , а затем выбрать наилучший результат. Однако следует иметь ввиду, что очень большие значения приводят к тому, что каждый объект будет иметь одинаковую степень принадлежности ко всем классам и классы станут вообще неразличимы. Кроме того, при использовании различных метрик наилучшие результаты будут получаться при различных значениях параметра . Так, например, для метрики Евклида вначале рекомендуется выбирать
достаточно произволен и при использовании данного алгоритма обычно требуется многократно провести процедуру классификации для различных , а затем выбрать наилучший результат. Однако следует иметь ввиду, что очень большие значения приводят к тому, что каждый объект будет иметь одинаковую степень принадлежности ко всем классам и классы станут вообще неразличимы. Кроме того, при использовании различных метрик наилучшие результаты будут получаться при различных значениях параметра . Так, например, для метрики Евклида вначале рекомендуется выбирать  , а для метрики Махаланобиса вначале нужно взять меньшее значение .
, а для метрики Махаланобиса вначале нужно взять меньшее значение .
Минимизация функции 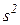 с использованием условий (2.25) приводит к следующему выражению для функции принадлежности :
с использованием условий (2.25) приводит к следующему выражению для функции принадлежности :
 для всех и . (2.26)
для всех и . (2.26)
Тогда положения центров классов вычисляются следующим образом:
 для всех . (2.27)
для всех . (2.27)
Перейдем теперь непосредственно к изложению словесного описания нечеткого алгоритма К-средних.
Шаг 1. Зададим количество классов  , значение для параметра нечеткости (
, значение для параметра нечеткости ( ) и выберем метрику для вычисления расстояний в пространстве существенных признаков.
) и выберем метрику для вычисления расстояний в пространстве существенных признаков.
Шаг 2. Задать точность вычислений  . Этот параметр используется для прекращения вычислений. Если положения центров всех классов на некоторой итерации изменились по сравнению с их положениями на предыдущей итерации на величину, меньшую , то вычисления заканчиваются.
. Этот параметр используется для прекращения вычислений. Если положения центров всех классов на некоторой итерации изменились по сравнению с их положениями на предыдущей итерации на величину, меньшую , то вычисления заканчиваются.
Шаг 3. Задать максимально допустимое число итераций  . Этот параметр также используется для прекращения вычислений. Если требуемая точность еще не достигнута, но количество проведенных итераций стало равно , то вычисления прекращаются, и выводится сообщение о невозможности достигнуть заданной точности при данном числе итераций . Зададим начальное значение счетчика итераций
. Этот параметр также используется для прекращения вычислений. Если требуемая точность еще не достигнута, но количество проведенных итераций стало равно , то вычисления прекращаются, и выводится сообщение о невозможности достигнуть заданной точности при данном числе итераций . Зададим начальное значение счетчика итераций  .
.
Шаг 4. Выбираем начальные положения центров классов 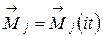 . Как и в «четком» алгоритме К-средних в качестве
. Как и в «четком» алгоритме К-средних в качестве  можно выбрать первых объектов выборки, т.е.
можно выбрать первых объектов выборки, т.е.  ,
,  и т.д., либо случайным образом выбрать произвольных объектов.
и т.д., либо случайным образом выбрать произвольных объектов.
Шаг 5. Вычисляем все компоненты функции принадлежности по формуле
 .
.
Для этого нужно предварительно вычислить в выбранной метрике квадраты расстояний между всеми объектами и всеми центрами классов, т.е. величины для всех и . Если какая-либо из величин  или
или  , где
, где  некоторое наперед заданное положительное число
некоторое наперед заданное положительное число 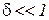 , то для данных и следует положить
, то для данных и следует положить  .
.
Шаг 6. Вычислив компоненты функции принадлежности для всех объектов, распределяем их по классам. Объект 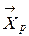 принадлежит к классу
принадлежит к классу  , если
, если  , то есть значение функции принадлежности объекта для данного класса наибольшее.
, то есть значение функции принадлежности объекта для данного класса наибольшее.
Шаг 7. Увеличим счетчик итераций на единицу 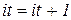 . Вычислим новые положения центров классов по формуле
. Вычислим новые положения центров классов по формуле
 для всех .
для всех .
Для вычисления центров классов используется функция принадлежности  , вычисленная на шаге 5.
, вычисленная на шаге 5.
Шаг 8. Вычислим расстояние между положением центра класса на данной и предыдущей итерации для всех центров, т.е. величины  для всех .
для всех .
Шаг 9. Если  , то вычисления закончены с выводом дополнительного сообщения о невозможности достигнуть заданной точности при данном .
, то вычисления закончены с выводом дополнительного сообщения о невозможности достигнуть заданной точности при данном .
Шаг 10. Если 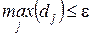
 , то вычисления закончены, иначе перейти к шагу 5.
, то вычисления закончены, иначе перейти к шагу 5.
Результатом выполнения алгоритма является функция принадлежности - матрица , которая содержит данные о степени принадлежности -го объекта к -му классу. Пусть, например, для пяти объектов  и трех классов
и трех классов  эта матрица имеет вид:
эта матрица имеет вид:
| j
i
|
|
|
|
|
| 0,78
| 0,15
| 0,07
|
|
| 0,92
| 0,08
| 0,00
|
|
| 0,15
| 0,05
| 0,8
|
|
| 0,00
| 0,05
| 0,95
|
|
| 0,09
| 0,87
| 0,04
|
Естественно считать, что объект принадлежит к тому классу  для которого функция принадлежности имеет максимальное значение. Таким образом, для данного случая первый объект принадлежит к первому классу
для которого функция принадлежности имеет максимальное значение. Таким образом, для данного случая первый объект принадлежит к первому классу 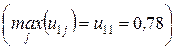 ; второй объект принадлежит к первому классу; третий объект принадлежит третьему классу и т.д.
; второй объект принадлежит к первому классу; третий объект принадлежит третьему классу и т.д.
Алгоритм ИЗОДАТА
ИЗОДАТА (по-английски ISODATA) означает «Итерационные самоорганизующиеся методы анализа данных». Это более сложный и гибкий алгоритм, чем рассмотренные ранее алгоритмы Максимина и К-средних. В частности, в отличие от алгоритма К-средних, количество классов здесь не фиксировано и может автоматически изменяться в процессе выполнения алгоритма путем объединения подобных классов и разбиения классов с большими среднеквадратичными отклонениями. Существенной особенностью алгоритма ИЗОДАТА является то, что здесь можно произвольно выбирать пороги для объединения и разбиения классов, а также ряд других параметров. Это позволяет проводить более гибкую и точную процедуру классификации, многократно выполняя вычисления и выбирая те значения параметров, которые обеспечивают наилучший результат. Отметим также, что алгоритм ИЗОДАТА предназначен для «четкой» классификации, т.е. может применяться, когда выборка объектов разделяется на сепарабельные классы в пространстве существенных признаков. В случае несепарабельных классов, т.е. в случае, когда между классами нельзя провести четкие границы, следует применять алгоритмы «нечеткой» классификации, например, нечеткий алгоритм К-средних. Область применения алгоритма ИЗОДАТА не ограничивается только распознаванием образов. Благодаря тому, что с его помощью можно легко обрабатывать большие массивы исходных данных, этот алгоритм используют для широкого класса практических задач в области метеорологии, социологии, медицины, биологии и т.д.
В алгоритме ИЗОДАТА используется ряд параметров, которые следует задать перед вычислениями:
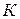 – желательное количество классов, которое определяется на основе предварительного анализа совокупности объектов. Если такой анализ провести невозможно или очень сложно ввиду большого объема выборки, то значение можно выбрать произвольно. В ходе выполнения алгоритма ИЗОДАТА количество классов будет уточняться.
– желательное количество классов, которое определяется на основе предварительного анализа совокупности объектов. Если такой анализ провести невозможно или очень сложно ввиду большого объема выборки, то значение можно выбрать произвольно. В ходе выполнения алгоритма ИЗОДАТА количество классов будет уточняться.
– максимальное количество итераций; этот параметр ограничивает количество итераций, которое может быть выполнено при работе алгоритма и позволяет ограничить время выполнения алгоритма в случае медленной сходимости, то есть когда для классификации объектов необходимо выполнить такое большое количество итераций, что затраты времени становятся неприемлемыми. Переменная  хранит текущее количество выполненных итераций. Начальное значение этой переменной
хранит текущее количество выполненных итераций. Начальное значение этой переменной 
 - максимальное количество пар классов, которые могут быть объединены; этот параметр ограничивает «сверху» процедуру объединения классов, т.е. позволяет избежать ситуации, при которой количество классов
- максимальное количество пар классов, которые могут быть объединены; этот параметр ограничивает «сверху» процедуру объединения классов, т.е. позволяет избежать ситуации, при которой количество классов  на -той итерации оказывается существенно меньше желательного количества классов .
на -той итерации оказывается существенно меньше желательного количества классов .
 - минимальное количество объектов, которое может содержаться в классе; если в процессе итерации в каком либо классе окажется меньше, чем объектов, то этот класс удаляется. Таким образом, параметр используется для предотвращения ситуации, при которой пространство существенных признаков будет разбито на слишком маленькие классы.
- минимальное количество объектов, которое может содержаться в классе; если в процессе итерации в каком либо классе окажется меньше, чем объектов, то этот класс удаляется. Таким образом, параметр используется для предотвращения ситуации, при которой пространство существенных признаков будет разбито на слишком маленькие классы.
 - пороговое значение для среднеквадратичного отклонения, которое используется для разбиения классов.
- пороговое значение для среднеквадратичного отклонения, которое используется для разбиения классов.
 - пороговое значение для расстояний между центрами классов, которое используется для объединения классов.
- пороговое значение для расстояний между центрами классов, которое используется для объединения классов.
 - весовой множитель для среднеквадратичного отклонения
- весовой множитель для среднеквадратичного отклонения  ; этот параметр используется для вычисления новых положений центров классов при разбиении класса с большим среднеквадратичным отклонением объектов от центра класса на два новых класса.
; этот параметр используется для вычисления новых положений центров классов при разбиении класса с большим среднеквадратичным отклонением объектов от центра класса на два новых класса.
 - метрика для вычисления расстояний в пространстве существенных признаков.
- метрика для вычисления расстояний в пространстве существенных признаков.
Выбор вышеперечисленных параметров в значительной степени эмпирический. Он основывается как на предварительном анализе массива исходных данных, так и на анализе самих результатов применения алгоритма. Если эти результаты оказались неудовлетворительными, следует по возможности выяснить, значение какого из параметров привело к таким результатам, изменить это значение и повторно выполнить алгоритм. Таким образом, многократно выполняя вычисления при различных значениях параметров, как правило, удается получить надежные результаты классификации объектов с помощью алгоритма ИЗОДАТА.
Словесное описание алгоритма
Шаг 1. Произвольно выбираем  начальных положений центов классов
начальных положений центов классов  , используя массив исходных данных
, используя массив исходных данных  , где
, где  – количество объектов в выборке. При этом значение не обязательно равно значению параметра . Выбор начальных положений центров классов выполняется так же, как и в алгоритме К-средних: в качестве можно выбрать первых объектов выборки, либо случайным образом выбрать произвольных объектов.
– количество объектов в выборке. При этом значение не обязательно равно значению параметра . Выбор начальных положений центров классов выполняется так же, как и в алгоритме К-средних: в качестве можно выбрать первых объектов выборки, либо случайным образом выбрать произвольных объектов.
Шаг 2. Группируем объекты вокруг центров классов. Этот шаг также аналогичен соответствующему шагу алгоритма К-средних. Вычисляем в выбранной метрике расстояние между центрами классов  и объектами выборки
и объектами выборки  . Отметим, что если некоторые объекты на данной итерации являются центрами классов, то расстояния между ними вычислять не нужно. Следовательно, как и в простом алгоритме К-средних, на каждой итерации нужно отмечать объекты, являющиеся в данный момент центрами классов, и вычислять расстояния только между центрами классов и непомеченными объектами. Затем для каждого из объектов находим минимальное расстояние и относим объект к соответствующему классу:
. Отметим, что если некоторые объекты на данной итерации являются центрами классов, то расстояния между ними вычислять не нужно. Следовательно, как и в простом алгоритме К-средних, на каждой итерации нужно отмечать объекты, являющиеся в данный момент центрами классов, и вычислять расстояния только между центрами классов и непомеченными объектами. Затем для каждого из объектов находим минимальное расстояние и относим объект к соответствующему классу: 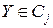 если
если  , где через
, где через  обозначен -ый класс.
обозначен -ый класс.
Шаг 3. Удаляем классы, количество объектов  в которых меньше чем , т.е. если
в которых меньше чем , т.е. если  для некоторого
для некоторого  , тоудаляем класс и уменьшаем значение на единицу
, тоудаляем класс и уменьшаем значение на единицу  .
.
Шаг 4. Вычисляем новые положения центров классов как среднее арифметическое векторов, принадлежащих одному классу:
 .
.
Здесь для каждого суммирование производится только по объектам, принадлежащих данному -му классу . Таким образом, вычисления положений центров классов в алгоритме ИЗОДАТА производится по той же формуле, что и в простом алгоритме К-средних.
Шаг 5. Для всех классов вычисляем среднее расстояние  от центра
от центра  класса
класса  до всех объектов, относящихся к данному классу:
до всех объектов, относящихся к данному классу:
 .
.
Шаг 6. Вычисляем взвешенное среднее расстояние объектов классов от их центров:

Весовым множителем в этой сумме является количество объектов в данном классе .
Шаг 7. На этом шаге алгоритм разветвляется и требуется принять решение, по какой из двух ветвей следует производить дальнейшие вычисления. Одна из ветвей – шаги с 8-го по 10-ый - реализует разбиение классов с большими среднеквадратичными отклонениями объектов от центров классов, а другая ветвь – шаги с 11-го по 13-ый - реализует объединение подобных классов, т.е. классов, расстояния между центрами которых меньше выбранного порогового значения  .
.
Критерий выбора одной из ветвей для дальнейших вычислений также является эмпирическим. Очевидно, что нужно сравнить количество имеющихся на данный момент классов с желательным количеством классов . При этом ясно, что если  , то классов слишком мало и нужно увеличивать их количество, т.е. разбивать большие классы, а если
, то классов слишком мало и нужно увеличивать их количество, т.е. разбивать большие классы, а если  , то классов слишком много и нужно объединять подобные классы. Однако, для принятия решения в алгоритме вышеназванные условия нужно конкретизировать. В общем случае выберем их следующим образом: если
, то классов слишком много и нужно объединять подобные классы. Однако, для принятия решения в алгоритме вышеназванные условия нужно конкретизировать. В общем случае выберем их следующим образом: если 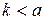 , то классы следует разбивать, а если
, то классы следует разбивать, а если  , то классы следует объединять, если же
, то классы следует объединять, если же  , то количество классов следует оставить неизменным и перейти к следующей итерации. Здесь
, то количество классов следует оставить неизменным и перейти к следующей итерации. Здесь  и
и  – некоторые параметры, удовлетворяющие условиям
– некоторые параметры, удовлетворяющие условиям 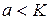 и
и  , определяющие диапазон для количества классов.
, определяющие диапазон для количества классов.
Выберем  и
и 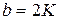 . Таким образом, разбиение классов будем производить, если их в два и более раз меньше, чем желательно, а объединение – если их в два и более раз больше.
. Таким образом, разбиение классов будем производить, если их в два и более раз меньше, чем желательно, а объединение – если их в два и более раз больше.
Итак, сформулируем окончательно решающее правило.
Если  то перейти к шагу 8., иначе
то перейти к шагу 8., иначе  перейти к шагу 11.
перейти к шагу 11.
Если  то перейти к шагу 14.
то перейти к шагу 14.
Шаг 8. Для того чтобы некоторый класс подходил для разбиения его на два класса, должны удовлетворяться одновременно три условия. Первое условие требует, чтобы максимальное среднеквадратичное отклонение объектов этого -го класса от его центра  было больше установленного порога
было больше установленного порога  :
:  . Второе условие требует, чтобы среднее расстояние
. Второе условие требует, чтобы среднее расстояние  от центра -го класса было больше взвешенного среднего расстояния
от центра -го класса было больше взвешенного среднего расстояния  :
:  . Это условие означает, что данный класс имеет в пространстве существенных признаков размер, больший среднего размера класса для данной выборки объектов. И наконец, третье условие требует, чтобы в классе было больше объектов, чем минимально допустимое количество объектов в классе
. Это условие означает, что данный класс имеет в пространстве существенных признаков размер, больший среднего размера класса для данной выборки объектов. И наконец, третье условие требует, чтобы в классе было больше объектов, чем минимально допустимое количество объектов в классе  :
: 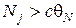 , где c – некоторая константа, большая единицы. В дальнейшем будем считать, что
, где c – некоторая константа, большая единицы. В дальнейшем будем считать, что  . Подчеркнем, что только при выполнении всех трех из вышеперечисленных условий класс подходит для разбиения на два новых класса.
. Подчеркнем, что только при выполнении всех трех из вышеперечисленных условий класс подходит для разбиения на два новых класса.
Таким образом, для принятия решения о разбиении некоторого -го класса нужно знать следующие три величины: максимальное среднеквадратичное отклонение объектов этого класса от его центра  , среднее расстояние от объектов класса до его центра и взвешенное среднее расстояние для всей выборки D (остальные величины являются задаваемыми параметрами). Величины и уже вычислены в ш. 5 и ш. 6 соответственно. Теперь нужно вычислить максимальное среднеквадратичное отклонение. Для этого находим вектор среднеквадратичного отклонения
, среднее расстояние от объектов класса до его центра и взвешенное среднее расстояние для всей выборки D (остальные величины являются задаваемыми параметрами). Величины и уже вычислены в ш. 5 и ш. 6 соответственно. Теперь нужно вычислить максимальное среднеквадратичное отклонение. Для этого находим вектор среднеквадратичного отклонения  для каждого класса (
для каждого класса ( ). Нижний индекс в
). Нижний индекс в  – это номер существенного признака, n – их количество, а верхний индекс – это номер класса. Таким образом, размерность (количество компонент) вектора
– это номер существенного признака, n – их количество, а верхний индекс – это номер класса. Таким образом, размерность (количество компонент) вектора  равно количеству существенных признаков объектов и совпадает с размерностью вектора
равно количеству существенных признаков объектов и совпадает с размерностью вектора 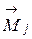 – положения центра класса. Среднеквадратическое отклонение вычисляется следующим образом: -я компонента для -го класса (среднеквадратичное отклонение объектов класса по -ой координатной оси) вычисляется по формуле:
– положения центра класса. Среднеквадратическое отклонение вычисляется следующим образом: -я компонента для -го класса (среднеквадратичное отклонение объектов класса по -ой координатной оси) вычисляется по формуле:
 ,
,  .
.
Здесь  - -ая компонента вектора - центра класса;
- -ая компонента вектора - центра класса;  - -ая компонента объекта
- -ая компонента объекта  ; для каждого класса суммирование производится только по объектам, принадлежащим данному классу .
; для каждого класса суммирование производится только по объектам, принадлежащим данному классу .
Шаг 9. Находим максимальный из компонентов вектора и обозначаем его  . Таким образом, из совокупности среднеквадратичных отклонений для разных существенных признаков выбирается максимальное. Эту операцию следует выполнить для всех классов
. Таким образом, из совокупности среднеквадратичных отклонений для разных существенных признаков выбирается максимальное. Эту операцию следует выполнить для всех классов  .
.
Шаг 10. Теперь все величины, необходимые для принятия решения о разбиении классов, вычислены.
Если для какого-либо истинны все следующие условия:
 ,
,
,
 ,
,
тогда разбиваем класс на два новых класса. Центры этих двух классов вычисляются по формулам:
 ,
,
 ,
,
где - некоторый заранее заданный параметр. После этого удаляем старый центр класса (после разбиения класса на два новых старый класс больше не существует) и увеличиваем значение на единицу:  . После того как все пригодные для разбиения классы будут разделены на два новых, полагаем
. После того как все пригодные для разбиения классы будут разделены на два новых, полагаем  (увеличиваем количество итераций на единицу) и переходим к шагу 2.
(увеличиваем количество итераций на единицу) и переходим к шагу 2.
Если не существует такого , для которого все три вышеперечисленных условия истинны, то переходим к шагу 14.
Шаг 11. С этого шага начинается процедура объединения подобных классов. Под подобными здесь понимаются классы, находящиеся ближе всего друг к другу в пространстве существенных признаков. Чтобы найти такие классы, следует вычислить расстояния между всеми центрами классов, а затем выбрать из найденных расстояний некоторое количество наименьших. Количество классов с наименьшими расстояниями регулируется двумя параметрами: пороговым значением и максимальном количеством объединяемых пар классов . Первый из этих параметров определяет степень близости объединяемых классов, т.е. объединяются попарно только те классы, расстояние между центрами которых меньше . Второй параметр ограничивает «сверху» количество объединяемых классов. Такое ограничение необходимо для того чтобы предотвратить ситуацию, при которой количество классов на данной итерации оказывается существенно меньше желательного количества классов . Эта ситуация может возникнуть в случае, если для параметра выбрано слишком большое значение и количество классов подлежащих объединению будет больше чем это необходимо (то есть в эту категорию попадут классы, которые не следует объединять).
Вычисляем расстояния между всеми центрами классов:
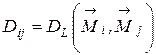 для всех
для всех  ,
,
а затем упорядочиваем эти найденные  расстояний в порядке возрастания.
расстояний в порядке возрастания.
Шаг 12. После того, как расстояния  между центрами классов упорядочены, выбираем из них те, которые меньше порога . Далее, из этих расстояний нужно выбрать те, которые соответствуют неповторяющимся классам и определить их количество
между центрами классов упорядочены, выбираем из них те, которые меньше порога . Далее, из этих расстояний нужно выбрать те, которые соответствуют неповторяющимся классам и определить их количество  . Этот этап необходим потому, что классы объединяются попарно, т.е. некоторый класс можно объединить только с другим классом, а именно с тем, расстояние до центра которого минимально. Если
. Этот этап необходим потому, что классы объединяются попарно, т.е. некоторый класс можно объединить только с другим классом, а именно с тем, расстояние до центра которого минимально. Если  , то объединению подлежат все неповторяющиеся пары классов, для которых
, то объединению подлежат все неповторяющиеся пары классов, для которых  . Если же
. Если же  , то из найденных
, то из найденных  соответствующих неповторяющимся классам, следует отобрать наименьших.
соответствующих неповторяющимся классам, следует отобрать наименьших.
Проиллюстрируем сказанное примером. Пусть количество классов  , а расстояния между центрами классов в выбранной метрике:
, а расстояния между центрами классов в выбранной метрике:  ,
,  ,
,  ,
,  ,
, 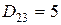 ,
, 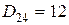 ,
,  ,
, 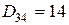 ,
,  ,
,  . Параметры и имеют следующие значения:
. Параметры и имеют следующие значения:  ,
, 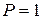 . Упорядочим в порядке возрастания: , , , , , , ,
. Упорядочим в порядке возрастания: , , , , , , ,  , , .
, , .
Условию удовлетворяют первые восемь расстояний. Отберем из них те, которые соответствуют неповторяющимся классам, просматривая список слева направо, т.е. в порядке возрастания расстояний. Первым в списке стоит  . Далее идет
. Далее идет 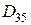 , но 3-ий класс уже использован, он будет объединяться с 1-ым классом, значит пропускаем. Рассуждая далее аналогичным образом, находим, что из списка следует выбрать еще расстояние
, но 3-ий класс уже использован, он будет объединяться с 1-ым классом, значит пропускаем. Рассуждая далее аналогичным образом, находим, что из списка следует выбрать еще расстояние  . Таким образом
. Таким образом 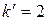 , а соответствующие расстояния и .
, а соответствующие расстояния и .
Сравним  с параметром . При ,
с параметром . При ,  , следовательно из двух подходящих для объединения пар классов – 1-ый с 3-им и 4-ый с 5-ым – нужно выбрать только одну пару, а именно ту, для которой расстояние между центрами классов минимально. Таким образом, объединить нужно 1-ый 3-ий классы.
, следовательно из двух подходящих для объединения пар классов – 1-ый с 3-им и 4-ый с 5-ым – нужно выбрать только одну пару, а именно ту, для которой расстояние между центрами классов минимально. Таким образом, объединить нужно 1-ый 3-ий классы.
Шаг 13. Объединяем классы попарно. Для  вычисляем положения новых центров по формуле:
вычисляем положения новых центров по формуле:
 .
.
Здесь индекс  указывает на номер объединяемой пары классов, а индексы и номера объединяемых классов.
указывает на номер объединяемой пары классов, а индексы и номера объединяемых классов.  и
и  - количества объектов в -ом и -ом классе соответственно, которые образуют -ую объединяемую пару;
- количества объектов в -ом и -ом классе соответственно, которые образуют -ую объединяемую пару;  и
и  - центры классов.
- центры классов.
Так, для вышеприведенного примера, где объединяется только одна пара классов,  ,
,  ,
,  , положение нового центра будет вычисляться по формуле:
, положение нового центра будет вычисляться по формуле:
 ,
,
где  и
и  - количества объектов в 1-ом и 3-ем классе соответственно, а
- количества объектов в 1-ом и 3-ем классе соответственно, а 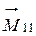 и
и  - их центры.
- их центры.
Затем следует удалить все старые центры объединенных классов (после объединения эти классы больше не существуют), т.е. удалить все и 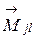 для . Уменьшить количество классов на :
для . Уменьшить количество классов на :  . После этого полагаем (увеличиваем количество итераций на единицу) и переходим к шагу 2.
. После этого полагаем (увеличиваем количество итераций на единицу) и переходим к шагу 2.
Шаг 14. Заканчиваем вычисления, если достигнуто максимальное число итераций . Иначе увеличиваем на единицу счетчик итераций и выполняем следующую итерацию, т.е. полагаем и переходим к шагу 2.
Дополнить разделами
1. Вероятностный подход определения существенных признаков.
- Распознавание сигналов. Оконные функции.
Литература
Р1. Bow S.T. Pattern recognition, Marcel Dekker Edit, Electrical Engineering and Elektronic series, 23, 1984, p. 30-32.





