
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Определение эконометрики. Взаимосвязь с другими науками. Эконометрика и экономическая теория. Эконометрика и статистика. Эконометрика и экономико-математические методы.Стр 1 из 18Следующая ⇒
Предмет и задачи курса. Эконометрия – это искусство предвидения экономических нормативов, прогнозов и гипотез. Деятельность в любой области экономики (управлении, финансово-кредитной сфере, маркетинге, учете и аудите) требует от специалистов применения современных методов работы, знания достижений мировой экономической мысли, понимание научного языка. Большинство новых методов основано на эконометрических моделях, концепциях, приёмах. Без глубоких знаний эконометрики научиться их использовать невозможно. Чтение современной литературы также предполагает хорошую эконометрическую подготовку. Специфической особенностью деятельности экономиста является работа в условиях недостатка информации и неполноты исходных данных. Анализ такой информации требует знания специальных методов, которые составляют один из аспектов эконометрики. Центральной проблемой эконометрики является построение экономической модели и определение возможностей её использования для описания, анализа и прогнозирования реальных экономических процессов. Известный экономист Цви Гриллихес (1929–1999г.) писал: «эконометрика является одновременно нашим телескопом и нашим микроскопом для изучения окружающего экономического мира». В этом случае можно говорить о микро- и макро-эконометрике. Свидетельством всемирного признания эконометрики является присуждение пяти Нобелевских премий по экономике за разработку в этой области: 1969г. Р. Фришу и Я. Тинбергену за разработку математических методов анализа экономических процессов; 1980г. Л. Клейну за создание эконометрических моделей и их применение к анализу экономических колебаний и экономической политики; 1989г. Т. Хаавельмо за пояснение вероятностных основ эконометрики; 2000г. Дж. Хекману за развитие теории и методов анализа селективных выборок и Д. Макфаддену за развитие теории и методов анализа моделей дискретных выборок. 2003г. Р.Энгел и К.Грэнджер за анализ экономических временных рядов (ARCH) с общими трендами. Процесс перехода экономического ВО в России на мировые стандарты характеризуется введением в учебные планы курсов микро- и макроэкономики, а также эконометрики.
Спецификация переменных в уравнениях регрессии.
Парная и множественная регрессия.
Свойства остатков Теперь установим почти очевидные соотношения, которые следуют из условии минимума критерия наименьших квадратов. Определим величину ŷi=a +bx,
— оценку переменной у при оптимальных значениях коэффициентов регрессии и фиксированном значении х в i-ом наблюдении. Такую оценку называют прогнозом зависимой переменной. Тогда, очевидно, ошибка модели в i-ом наблюдении будет равна e i=yi- ŷi и из условия следует, что
т. е сумма квадратов ошибок оценок переменной у (остатков модели) при оптимальных параметрах регрессии а и b равна нулю. Далее, вытекает, что т. е., при оптимальных параметрах регрессии ошибки ортогональны наблюдениям независимой переменной.
Несмещенность МНК-оценок Статистическая оценка некоторого параметра называется несмещенной, если ее математическое ожидание равно истинному значению этого параметра. Для случая парной линейной регрессии это означает, что опенки а и b будут несмещенными, если М{а} = α, M{b}=β.
Применив формулу для коэффициента,а также полученное выше соотношение, составим выражение:
Далее, поскольку х — неслучайная величина, будем иметь:
и, таким образом, оценка b является несмещенной. Несмещенность оценки а следует из цепочки равенств:
Замечание. Свойство несмещенности оценок можно доказать и при более слабой форме 4-го условия Гаусса-Маркова, когда х—случайная, но некоррелированная со случайной переменной u, величина.
Состоятельность оценок Свойство состоятельности оценок заключается в том, что при неограниченном возрастании объема выборки, значение оценки должно стремиться (по вероятности) к истинному значению параметра, а дисперсии оценок должны уменьшаться и в пределе стремиться к нулю. Дисперсии оценок коэффициентов регрессии определяются выражениями:
Или. используя равенство
Вывод: чем больше число наблюдений n, тем меньше будут дисперсии ошибок.
Несмещённость. Поскольку оценки являются случайными переменными, их значения лишь по случайному совпадению могут в точности равняться характеристикам генеральной совокупности. Обычно будет присутствовать определённая ошибка, которая может быть большой, или малой, положительной или отрицательной, в зависимости от чисто случайных составляющих величин х в выборке.
Желательно, чтобы оценка в среднем за достаточно длительный период была аккуратной. То есть М. О. оценки =соответствующей характеристике генеральной совокупности. Так оценка называется несмещённой. Если это не так, то оценка называется смещённой и разница, между её М. О. и соответствующей теоретической характеристикой генеральной совокупности называется смещением.
Эффективность.
Несмещённость – желательное свойство оценок, но не единственное свойство. Ещё одна их важная сторона – это надёжность. Конечно, немаловажно, чтобы оценка была точной в среднем за длительный период. Пусть имеем две оценки теоретического среднего, рассчитанных на основе одной и той же информации. Поскольку функция плотности вероятности для В более «сжата», чем для А, с её помощью мы скорее получим более точное значение. Таким образом оценка В более эффективна. Эффективна та оценка, дисперсия которой min.
Состоятельность. Если предел по вероятности равен истинному значению характеристики генеральной совокупности, то эта оценка называется состоятельной. Таким образом, состоятельной называется такая оценка, которая даёт точное значение для большой выборки независимо от входящих в неё конкретных наблюдений.
Необходимо иметь в виду, что состоятельная оценка в принципе может на малых выборках работать хуже, чем состоятельная (иметь большую ско) и поэтому требуется осторожность.
Дисперсионный анализ. Сначала проанализируем дисперсию, он предшествует F-критерию. Центральное место занимает разложение общей суммы квадратов отклонений переменной у от среднего значения
Общая сумма Объясненную Необъясненную квадратов регрессию (остаточную) отклонений регрессию Общая сумма квадратов отклонений у от Если фактор не оказывает влияние на результат, то линия регрессии на графике параллельна оси ОХ и Т.к. не все точки поля корреляции лежат на линии регрессии, то всегда имеет место их разброс, как обусловленный влиянием фактора х, т. е. регрессией у по х, так и вызванный действием прочих причин (необъясненная вариация). Пригодность линейной регрессии для прогноза зависит от того, какая часть общей вариации признака у приходится на долю объясненную вариацией. Если сумма квадратных отклонений, обусловленных регрессией, будет больше остаточной суммы квадратов, то уравнение регрессии статистически значимо и фактор х оказывает существенное воздействие на у. Это равносильно тому, что
Любая сумма квадратных отклонений связана с числом степеней свободы ( Например,
При расчёте объясненной или факторной суммы квадратов В линейной регрессии
Поскольку при заданном объёме наблюдений по х и у факторная сумма квадратов при ЛР зависит только от одной константы (коэффициента регрессии b), то данная сумма квадратов имеет одну степень свободы. К этому же выводу можно прийти по другому.
Отсюда следует, что при заданном наборе переменных у и х расчетное значение Существует равенство между числом степеней свободы общей, факторной и остаточной суммами квадратов. Число степеней свободы остаточной суммы квадратов при ЛР составляет
Разделив каждую переменную сумму квадратов на соответствующее ей число степеней свободы, получим средний квадрат отклонений, или дисперсию на 1 степень свободы.
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчёте на одну степень свободы, получим величину F-критерия.
F-критерий для проверки нулевой гипотезы. Н0 :
Английский статистик Снедекор разработал таблицу критических значений F-критерия – это максимальная величина отношения дисперсий, которая может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы. Вычисленное значение F-отношений признаётся достоверным (отличным от единицы), если оно больше табличного. В этом случае Н0 (отсутствие связи) отклоняется и делается вывод о существенности этой связи: Если же Н0 не отклоняется, а уравнение регрессии становится незначимым. Величина F-критерия связана с коэффициентом детерминации Оценка значимости уравнения регрессии даётся в виде таблицы дисперсионного анализа.
В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных параметров. Поэтому по каждому из параметров определяется его стандартная ошибка: Стандартная ошибка коэффициента регрессии определяется по формуле:
Величина стандартной ошибки совместно с t-распределением Стьюдента при n-2 степенях свободы применяется для проверки существенности коэффициента регрессии и для расчёта его доверительных интервалов. Для оценки существенности коэффициента регрессии его величина сравнивается со стандартной ошибкой, т.е. определяется фактическое значение t-критерия Стьюдента.
Если фактическое значение больше табличного, то гипотезу о несущественности коэффициентов отвергаем. Доверительный интервал для коэффициента регрессии b определим по формуле
Так как коэффициент регрессии носит в эконометрических исследованиях чётко экономическую интерпретацию, то доверительные интервалы не должны содержать противоречивых результатов, например, Стандартная ошибка параметра a определяется:
Процедура оценивания не отличается от рассмотренной выше для b.
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитывается t-критерий Стьюдента и доверительные интервалы для каждого из показателей. Выдвигается гипотеза Н0 о случайной природе показателей, то есть о незначительном отличии их от нуля. Оценки значимости коэффициентов регрессии и корреляции с помощью t-критерия Стьюдента проводится путём сопоставления их значений с величиной случайной ошибки (S2 остаточная дисперсия на 1 степень свободы,
Сравниваем фактические и критические (табл.) значения и принимаем или отвергаем Н0
Для расчёта доверительного интервала определяем предельную ошибку
Формулы для расчёта доверительных интервалов имеют вид:
Если в границы доверительного интервала попадает нуль, то есть нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается равный 0, так как не может одновременно принимать положительное и отрицательное значения степенями свободы. Значимость линейного коэффициента корреляции проверяется на основе величины коэффициента корреляции mr
Фактическое значение t-критерия Стьюдента определяется
Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения. Если Рассмотренная формула оценки коэффициента корреляции рекомендуется к применению при большом числе наблюдений и если r не близко к +1 или -1. Если
При r = 0,991 Z можно взять в таблице для соответствующего r. Выдвигаем гипотезу H0 –т.е. корреляция отсутствует:
В виду того, что r и z связаны между собой приведённым выше отношением, можно вычислить критические значения r, соответствующие каждому из значений z. Таблицы критических значений r разработаны для уровней значимости 0,05 и 0,01 и соответствующего числа степеней свободы. Критические значения Если же
Стандартизированные коэффициенты регрессии, их интерпретация. Парные и частные коэффициенты корреляции. Множественный коэффициент корреляции. Множественный коэффициент корреляции и множественный коэффициент детерминации. Оценка надежности показателей корреляции. Параметры уравнения множественной регрессии оцениваются, как и в парной регрессии, методом наименьших квадратов (МНК). При его применении строится система нормальных уравнений, решение которой и позволяет получить оценки параметров регрессии.
Ее решение может быть осуществлено методом Крамера:
где D – главный определитель системы; Dа, Db1, …, Dbp – частные определители. При этом
а Dа, Db1, …, Dbp получаются путем замены соответствующего столбца матрицы определителя системы данными левой части системы. Возможен и иной подход к определении параметров множественной регрессии, когда на основе матрицы парных коэффициентов корреляции строится уравнение регрессии в стандартизованном масштабе:
где Применяя МНК к уравнению множественной регрессии в стандартизованном масштабе, после соответствующих преобразований получим систему нормальных вида
Решая ее методом определителей, найдем параметры – стандартизованные коэффициенты регрессии (b-коэффициенты). Стандартизованные коэффициенты регрессии показывают, на сколько сигм изменится в среднем результат, если соответствующий фактор хi изменится на одну сигму при неизменном среднем уровне других факторов. В силу того, что все переменные заданы как центрированные и нормированные, стандартизованные коэффициенты регрессии bI сравнимы между собой. Сравнивая их друг с другом, можно ранжировать факторы по силе их воздействия на результат. В этом основное достоинство стандартизованных коэффициентов регрессии в отличие от коэффициентов «чистой» регрессии, которые несравнимы между собой. Пример. Пусть функция издержек производства у (тыс. руб.) характеризуется уравнением вида
где х1 – основные производственные фонды; х2 – численность занятых в производстве. Анализируя его, мы видим, что при той же занятости дополнительный рост стоимости основных производственных фондов на 1 тыс. руб. влечет за собой увеличение затрат в среднем на 1,2 тыс. руб., а увеличение численности занятых на одного человека способствует при той же технической оснащенности предприятий росту затрат в среднем на 1,1 тыс. руб. Однако это не означает, что фактор х1 оказывает более сильное влияние на издержки производства по сравнению с фактором х2. Такое сравнение возможно, если обратиться к уравнению регрессии в стандартизованном масштабе. Предположим, оно выглядит так:
Это означает, что с ростом фактора х1 на одну сигму при неизменной численности занятых затрат на продукцию увеличиваются в среднем на 0,5 сигмы. Так как b1 < b2 (0,5 < 0,8), то можно заключить, что большее влияние оказывает на производство продукции фактор х2, а не х1, как кажется из уравнения регрессии в натуральном масштабе. В парной зависимости стандартизованный коэффициент регрессии есть не что иное, как линейный коэффициент корреляции rxy. Подобно тому, как в парной зависимости коэффициент регрессии и корреляции связаны между собой, так и в множественной регрессии коэффициенты «чистой» регрессии bi связаны со стандартизованными коэффициентами регрессии bi, а именно:
Это позволяет от уравнения регрессии в стандартизованном масштабе
переход к уравнению регрессии в натуральном масштабе переменных:
Параметр а определяется как
Рассмотренный смысл стандартизованных коэффициентов регрессии позволяет их использовать при отсеве факторов – из модели исключаются факторы с наименьшим значением bj. Компьютерные программы построения уравнения множественной регрессии в зависимости от использованного в них алгоритма решения позволяют получить либо только уравнение регрессии для исходных данных, либо, кроме того, уравнение регрессии в стандартизованном масштабе. При нелинейной зависимости признаков, приводимой к линейному виду, параметры множественной регрессии также определяются МНК с той лишь разницей, что он используется не к исходной информации, а к преобразованным данным. Так, рассматривая степенную функцию
мы преобразовываем ее в линейный вид:
где переменные выражены в логарифмах. Далее обработка МНК та же, что и описана выше: строится система нормальных уравнений и определяются параметры lga, b1, b2, … bp. Потенцируя значение lga, найдем параметр а и соответственно общий вид уравнения степенной функции. Поскольку параметры степенной функции представляют собой коэффициенты эластичности, то они сравнимы по разным факторам. Пример. При исследовании спроса на масло получено следующее уравнение:
у – количество масла на душу населения (кг); х1 – цена (руб.) х2 – доход на душу населения (тыс. руб.). Анализируя уравнение, видим, что с ростом цены на 1% при том же доходе спрос снижается в среднем на 0,858%, а рост дохода на 1% при неизменных ценах вызывает увеличение спроса в среднем на 1,126%. В виде степенной функции данное уравнение примет вид:
При других нелинейных функциях методика оценки параметров МНК осуществляется так же. В отличие от предыдущих функций параметры более сложных моделей не имеют четкой экономической интерпретации: они не являются показателями силы связи и ее эластичности. Это не исключает возможности их применения, но делает их менее привлекательными в практических расчетах. Частные уравнения регрессии На основе линейного уравнения множественной регрессии
могут быть найдены частные уравнения регрессии:
т.е. уравнения регрессии, которые связывают результативный признак с соответствующими факторами х при закреплении других учитываемых во множественной регрессии факторов на среднем уровне. Частные уравнения имеют следующий вид:
При подстановке в эти уравнения средних значений соответствующих факторов они принимают вид парных уравнений линейной регрессии, т.е. имеем:
где В отличие от парной регрессии частные уравнения регрессии характеризуют изолированное влияние фактора на результат, ибо другие факторы закреплены на неизменном уровне. Эффекты влияния других факторов присоединены в них к свободному члену уравнения множественной регрессии. Это позволяет на основе частных уравнений регрессии определять частные коэффициенты эластичности:
где bi – коэффициенты регрессии для фактора хi в уравнении множественной регрессии;
Пример. Предположим, что по ряду регионов множественная регрессия величины импорта на определенный товар у относительно отечественного его производства х1, изменения запасов х2 и потребления на внутреннем рынке х3 оказалась следующей:
При этом средние значения для рассматриваемых признаков составили:
На основе данной информации могут быть найдены средние по совокупности показатели эластичности:
Для данного примера они окажутся равными:
т.е. с ростом величины отечественного производства на 1% размер импорта в среднем по совокупности регионов возрастает на 1,053% при неизменных запасах и потреблении семей. Для второй переменной коэффициент эластичности составляет:
т.е. с ростом изменения запасов на 1% при неизменном производстве и внутреннем потреблении величина импорта увеличивается в среднем на 0,056%. Для второй переменной коэффициент эластичности составляет:
т.е. при неизменном объеме производства и величины запасов с увеличением внутреннего потребления на 1% импорт товар возрастает в среднем по совокупности регионов на 1,987%. Средние показатели эластичности можно сравнивать друг с другом и соответственно ранжировать факторы по силе их воздействия на результат. В рассматриваемом примере наибольшее воздействие на величину импорта оказывает размер внутреннего потребления товара х3, а наименьшее – изменение запасов х2. Наряду со средними показателями эластичности в целом по совокупности регионов на основе частных уравнений регрессии могут быть определены частные коэффициенты эластичности для каждого региона. Частные уравнения регрессии в нашем случае составят:
т.е.
т.е.
т.е.
Подставляя в данные уравнения фактические значения по отдельным регионам соответствующих факторов, получим значения моделируемого показателями
Как видим, частные коэффициенты эластичности для региона несколько отличаются от аналогичных средних показателей по совокупности регионов. Они могут быть использованы при принятии решений относительно развития конкретных регионов. Множественная корреляция Практическая значимость уравнения множественной регрессии оценивается с помощью показателя множественной корреляции и его квадрата – коэффициента детерминации. Показатель множественной корреляции характеризует тесноту рассматриваемого набора факторов с исследуемым признаком, или, иначе, оценивает тесноту совместного влияния факторов на результат. Независимо от формы связи показатель множественной корреляции может быть найден как индекс множественной корреляции:
где s2y – общая дисперсия результативного признака; sост2 – остаточная дисперсия для уравнения у = ¦(х1,х2,….,xp). Методика построения индекса множественной корреляции аналогична построению индекса корреляции для парной зависимости. Границы его изменения те же: от 0 до 1. Чем ближе его значение к 1, тем теснее связь результативного признака со всем набором исследуемых факторов. Величина индекса множественной корреляции должна быть больше или равна максимальному парному индексу корреляции:
|
||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 216; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.191.216.163 (0.151 с.) |
 ;
; 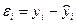




 ;
; 
 , можно записать в виде:
, можно записать в виде: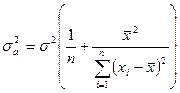




 на две части.
на две части.
 . Тогда вся дисперсия результативного признака обусловлена воздействием прочих факторов и общая сумма квадратов отклонений совпадает с остаточной Если же прочие факторы не влияют на результат, то у связан с х функционально и остаточная сумма квадратов равна 0, и сумма квадратов отклонений, объясняющей регрессией совпадает с общей суммой квадратов.
. Тогда вся дисперсия результативного признака обусловлена воздействием прочих факторов и общая сумма квадратов отклонений совпадает с остаточной Если же прочие факторы не влияют на результат, то у связан с х функционально и остаточная сумма квадратов равна 0, и сумма квадратов отклонений, объясняющей регрессией совпадает с общей суммой квадратов. .
. ), т. е. с числом свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности n и с числом, определяемым по ней константы. Т. о. число степеней свободы должно показать, сколько независимых х отклонений из n возможных
), т. е. с числом свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности n и с числом, определяемым по ней константы. Т. о. число степеней свободы должно показать, сколько независимых х отклонений из n возможных  требуется для образования данной суммы квадратов. Так, для общей суммы квадратов
требуется для образования данной суммы квадратов. Так, для общей суммы квадратов  требуется
требуется  независимых отклонений, т. к. по совокупности из n единиц после расчёта среднего уровня свободно варьируется лишь
независимых отклонений, т. к. по совокупности из n единиц после расчёта среднего уровня свободно варьируется лишь 

 , тогда
, тогда  т. к.
т. к.  , то свободно варьируются только 4 отклонения, а пятое отклонение может быть определено, если предыдущие четыре известны.
, то свободно варьируются только 4 отклонения, а пятое отклонение может быть определено, если предыдущие четыре известны. используются теоретические (расчётные) значения результативного признака
используются теоретические (расчётные) значения результативного признака  , найденные из уравнения
, найденные из уравнения  .
.
 , а
, а 
 - общая дисперсия признака у;
- общая дисперсия признака у; - дисперсия признака у, обусловленная фактором х.
- дисперсия признака у, обусловленная фактором х.
 является в ЛР функцией только одного параметра - коэффициента регрессии, поэтому факторная сумма квадратов отклонений имеет число степеней свободы, равное 1.
является в ЛР функцией только одного параметра - коэффициента регрессии, поэтому факторная сумма квадратов отклонений имеет число степеней свободы, равное 1. . Число степеней свободы для общей суммы квадратов определяется числом единиц, и т. к. мы используем среднюю вычисленную по данным выборки, то теряем одну степень свободы, то есть
. Число степеней свободы для общей суммы квадратов определяется числом единиц, и т. к. мы используем среднюю вычисленную по данным выборки, то теряем одну степень свободы, то есть  .
.

 ;
;  ;
;  .
.
 .Если Н0 справедлива, то фактическая и остаточная дисперсии не отличаются друг от друга. Для Н0 необходимо опровержение, чтобы Д факт превышала Д ост в несколько раз.
.Если Н0 справедлива, то фактическая и остаточная дисперсии не отличаются друг от друга. Для Н0 необходимо опровержение, чтобы Д факт превышала Д ост в несколько раз. ,
,  отклоняется.
отклоняется. , то вероятность Н0 выше заданного уровня (например 0,05) и она не может быть отклонена без серьёзного риска сделать неправильный вывод о наличии связи.
, то вероятность Н0 выше заданного уровня (например 0,05) и она не может быть отклонена без серьёзного риска сделать неправильный вывод о наличии связи. . Факторную
. Факторную  квадратов отклонений можно представить как
квадратов отклонений можно представить как  , (
, ( - общая дисперсия y;
- общая дисперсия y;  - дисперсия y обусловлена фактором x (факторная)), а остаточную сумму
- дисперсия y обусловлена фактором x (факторная)), а остаточную сумму  (
( ,
,  ). Тогда
). Тогда  .
. квадратов отклонений
квадратов отклонений

 и
и  ,
,  .
. ;
; - остаточная дисперсия на одну степень свободы ошибки.
- остаточная дисперсия на одну степень свободы ошибки. , который сравнивается с табличным значением при определённом уровне значимости
, который сравнивается с табличным значением при определённом уровне значимости  и числе степеней свободы
и числе степеней свободы  .
.
 предельная ошибка (
предельная ошибка ( границы).
границы).
 . То есть, что истинное значение коэффициента одновременно содержит положительные, отрицательные величины и даже 0, чего не может быть.
. То есть, что истинное значение коэффициента одновременно содержит положительные, отрицательные величины и даже 0, чего не может быть.
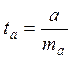 , его величина сравнивается с табличным, при
, его величина сравнивается с табличным, при  .
. ).
). ;
;  ;
;  ;
; ;
;  ;
;  .
.
 , то Н0 отклоняется, и считается, что
, то Н0 отклоняется, и считается, что  и
и  сформировались под влиянием систем фактора x.
сформировались под влиянием систем фактора x. для каждого показателя.
для каждого показателя.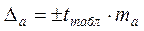 ;
;  .
.
 .
. , данная формула свидетельствует, что в парной линейной регрессии
, данная формула свидетельствует, что в парной линейной регрессии  , ибо
, ибо  , а также
, а также  , следовательно
, следовательно  .
. при
при  . То есть коэффициент а существенно отличен от нуля – является правильной, а зависимость достоверной.
. То есть коэффициент а существенно отличен от нуля – является правильной, а зависимость достоверной. , то распределение его оценок отличается от нормального или распределения Стьюдента, так как величина
, то распределение его оценок отличается от нормального или распределения Стьюдента, так как величина  ограничена значениями (-1+1). Чтобы обойти это затруднение Р. Фишером было предложено для оценки существенности
ограничена значениями (-1+1). Чтобы обойти это затруднение Р. Фишером было предложено для оценки существенности 
 изменяется
изменяется  , что соответствует нормальному распределению. Стандартная ошибка величины
, что соответствует нормальному распределению. Стандартная ошибка величины  , где n – число наблюдений.
, где n – число наблюдений.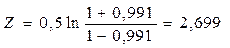
 .
. .
. , то есть фактическое значение
, то есть фактическое значение  превышает его табличное значение на уровне значимости
превышает его табличное значение на уровне значимости  и
и  .
.
 предполагают справедливость нулевой гипотезы, то есть
предполагают справедливость нулевой гипотезы, то есть 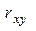 мало отличается от нуля. Если фактическое значение коэффициента по абсолютной величине превышает табличное, то данное значение
мало отличается от нуля. Если фактическое значение коэффициента по абсолютной величине превышает табличное, то данное значение  считается существенным.
считается существенным. , то фактическое значение r несущественно.
, то фактическое значение r несущественно. Так, для уравнения
Так, для уравнения 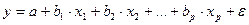 система нормальных уравнений составит:
система нормальных уравнений составит:
 ,
, 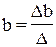 ,…,
,…,  ,
,

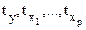 - стандартизованные переменные
- стандартизованные переменные 
 , для которых среднее значение равно нулю
, для которых среднее значение равно нулю 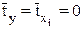 , а среднеквадратическое отклонение равно единице:
, а среднеквадратическое отклонение равно единице:  ;
;  - стандартизованные коэффициенты регрессии.
- стандартизованные коэффициенты регрессии.
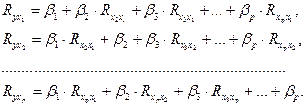
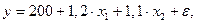
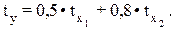
 (3.1)
(3.1)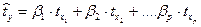 (3.2)
(3.2)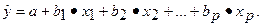
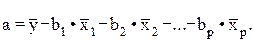 (3.3)
(3.3)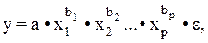

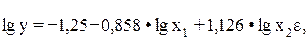 где
где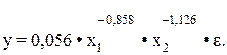







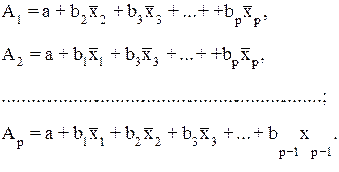
 (3.4)
(3.4) – частное уравнение регрессии.
– частное уравнение регрессии.

 (3.5)
(3.5)
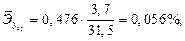

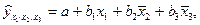



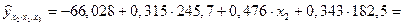


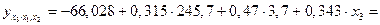
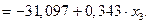
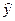 при заданном уровне одного значения и средних значениях других факторов. Эти расчетные значения результативного признака используются для определения частных коэффициентов по приведенной выше формуле. Так, если, например, в регионе х1=160,2; х2=4,0; х3=190,5, то частные коэффициенты эластичности составят:
при заданном уровне одного значения и средних значениях других факторов. Эти расчетные значения результативного признака используются для определения частных коэффициентов по приведенной выше формуле. Так, если, например, в регионе х1=160,2; х2=4,0; х3=190,5, то частные коэффициенты эластичности составят: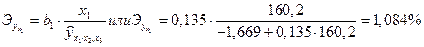

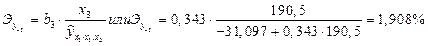
 , (3.6)
, (3.6)



