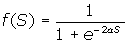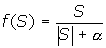Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Мінімаксна стратегія прийняття рішеньСтр 1 из 11Следующая ⇒
Мінімаксна стратегія прийняття рішень Модель прийняття рішень містить у собі: - множину можливих станів природи S{Si}, що породжує невизначеність ситуації, так як в момент прийнятя рішення істинний стан природи не відомо. Ця ситуація може бути задана апріорним розподілом на множині S (статистично визначена), або може бути цілком невизначеною статистично; - множину можливих дій D{dj}, причому правильний вибір кожної з дій dj залежить від істинного стану природи; - функцію втрат U(d,S), за допомогою якої можна оцінити результати застосування будь-якої з можливих дій d j Î D, якщо істинний стан природи Si. Вона може бути задана або у вигляді деякої аналітичної залежності, або у вигляді матриці || Uij ||= ||U(dj, Si)||; - експеримент, проведений для одержання інформації про стан природи. Однак можливі його результати xі Î Х залежать не тільки від стану природи, але і від точності самого експерименту. У зв'язку з цим повинна бути відома характеристика експерименту - розподіл F(x/Si) на множині X для всіх si Î S; - множина стратегій A{аν},кожна з який є сукупністю правил, що визначають визначену дію dj Î D при результаті експерименту xi Î X. Задача полягає в тому, щоб із усієї множини можливих стратегій вибрати оптимальну в змісті якого-небудь критерію. У випадку статистично невизначеної ситуації оптимальною буде мінімаксна стратегія аν*, для якої r(аν*)= min max r(аν, sі) (1.6) Мінімаксний підхід до вибору оптимальної стратегії гарантує мінімальні умовні середні втрати при найгіршому стані природи. Мінімаксну стратегію можна знайти графічно. Для цього на рис. 1.1 будується допоміжна множина точок, що має вигляд клина зі сторонами, паралельними координатним осям з вершиною в точці (с,с). Потім, збільшуючи с, зрушують клин вправо і нагору. Точка, у якій цей клин у перший раз торкнеться множини A, відповідає мінімаксній стратегії. Якщо клин торкається множини A своєю вершиною, то умовні середні втрати при мінімаксній стратегії однакові для обох станів природи. Якщо торкання відбувається по лінії, то оптимальною буде припустима стратегія. Основні параметри людського мозку у порівняні з параметрами засобів комп’ютерної техніки Аналогія з мозком Точна робота мозку людини - все ще таємниця. Проте деякі аспекти цього дивовижного процесора відомі. Базовим елементом мозку людини є специфічні клітини, відомі як нейрони, що здатні запам'ятовувати, думати і застосовувати попередній досвід до кожної дії, що коренево відрізняє їх від решта клітин тіла.
Кора головного мозку людини є протяжною, утвореною нейронами поверхнею товщиною від 2 до 3 мм із площею близько 2200 см2, що вдвічі перевищує площу поверхні стандартної клавіатури. Кора головного мозку містить близько 1011 нейронів, що приблизно дорівнює числу зірок Чумацького шляху. Кожен нейрон зв'язаний з 103 - 104 іншими нейронами. У цілому мозок людини містить приблизно від 1014 до 1015 взаємозв'язків. Сила людського розуму залежить від числа базових компонент, різноманіття з'єднань між ними, а також від генетичного програмування й навчання. Індивідуальний нейрон є складним, має свої складові, підсистеми та механізми керування і передає інформацію через велику кількість електрохімічних зв'язків. Налічують біля сотні різних класів нейронів. Разом нейрони та з'єднання між ними формують недвійковий, нестійкий та несинхронний процес, що різниться від процесу обчислень традиційних комп'ютерів. Штучні нейромережі моделюють лише найголовніші елементи складного мозку, що надихає науковців та розробників до нових шляхів розв'язування проблеми.
Біологічний нейрон Нейрон (нервова клітка) складається з тіла клітини - соми (soma), і двох типів зовнішніх деревоподібних відгалужень: аксона (axon) і дендритів (dendrites). Тіло клітини вміщує ядро (nucleus), що містить інформацію про властивості нейрона, і плазму, яка продукує необхідні для нейрона матеріали. Нейрон отримує сигнали (імпульси) від інших нейронів через дендрити (приймачі) і передає сигнали, згенеровані тілом клітки, вздовж аксона (передавач), що наприкінці розгалужується на волокна (strands). На закінченнях волокон знаходяться синапси (synapses).
Рис. 1. Схема біологічного нейрона Синапс є функціональним вузлом між двома нейронами (волокно аксона одного нейрона і дендрит іншого). Коли імпульс досягає синаптичного закінчення, продукуються хімічні речовини, названі нейротрансмітерами. Нейротрансмітери проходять через синаптичну щілину, збуджуючи або гальмуючи, у залежності від типу синапсу, здатність нейрона-приймача генерувати електричні імпульси. Результативність синапсу налаштовується минаючими через нього сигналами, тому синапси навчаються в залежності від активності процесів, у яких вони приймають участь. Нейрони взаємодіють за допомогою короткої серії імпульсів. Повідомлення передається за допомогою частотно-імпульсної модуляції. Останні експериментальні дослідження доводять, що біологічні нейрони структурно складніші, ніж спрощене пояснення, наведене вище і значно складніші, ніж існуючі штучні нейрони, які є елементами сучасних штучних нейронних мереж. Оскільки нейрофізіологія надає науковцям розширене розуміння дії нейронів, а технологія обчислень постійно вдосконалюється, розробники мереж мають необмежений простір для вдосконалення моделей біологічного мозку. Штучний нейрон Базовий модуль нейронних мереж штучний нейрон моделює основні функції природного нейрона (рис. 2).
Рис. 2. Базовий штучний нейрон Вхідні сигнали xn зважені ваговими коефіцієнтами з'єднання wn додаються, проходять через передатну функцію, генерують результат і виводяться. У наявних на цей час пакетах програм штучні нейрони називаються "елементами обробки" і мають набагато більше можливостей, ніж простий штучний нейрон, описаний вище. На рис. 3 зображена детальна схема спрощеного штучного нейрону.
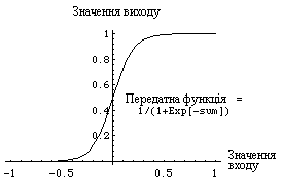
Рис. 3. Модель "елементу обробки" Модифіковані входи передаються на функцію сумування, яка переважно тільки сумує добутки. Проте можна обрати багато різних операцій, такі як середнє, найбільше, найменше, OR, AND, тощо, які могли б виробляти деяку кількість різних значень. Окрім того, більшість комерційних програм дозволяють інженерам-програмістам створювати власні функції суматора за допомогою підпрограм, закодованих на мові високого рівня (C, С++, TurboPascal). Інколи функція сумування ускладнюється додаванням функції активації, яка дозволяє функції сумування оперувати в часі. В любому з цих випадків, вихід функції сумування надсилається у передатну функцію і скеровує весь ряд на дійсний вихід (0 або 1, -1 або 1, або яке-небудь інше число) за допомогою певного алгоритму. В існуючих нейромережах в якості передатних функцій можуть бути використані сигмоїда, синус, гіперболічний тангенс та ін. Приклад того, як працює передатна функція показаний на рис. 4.
Рис. 4. Сигмоїдна передаточна функція Після обробки сигналу, нейрон на виході має результат передатної функції, який надходить на входи інших нейронів або до зовнішнього з'єднання, як це передбачається структурою нейромережі. Всі штучні нейромережі конструюються з базового формуючого блоку - штучного нейрону. Існуючі різноманітності і фундаментальні відмінності, є підставою мистецтва талановитих розробників для реалізації ефективних нейромереж. Формальний нейрон Формальный нейрон (далее нейрон), представляет собой математическую модель биологической нервной клетки. Насколько эта модель адекватна, сказать трудно, тем более для нас это неважно. Схематически нейрон (рис. 1) состоит из двух элементарных составляющих: адаптивного сумматора (другие названия-суммирующий элемент, сумматор) и нелинейного преобразователя (активационного элемента).
Рис.1.1. Схема нейрона Суммирующий элемент вычисляет скалярное произведение вектора входного сигнала Х на вектор подстраиваемых параметров W при T=0. Выделяют также неоднородный суммирующий элемент, для которого Т = 0. Т при этом называют порогом или пороговым значением нейрона. Выход сумматора S часто называют текущим состоянием нейрона, по которому можно судить, насколько нейрон возбужден или заторможен. Огромное значение имеет активационный элемент(другое название-нелинейный преобразователь), преобразующий текущее состояние нейрона в выходной сигнал согласно некоторому нелинейному закону. Из дальнейшего станет ясно, что без нелинейного преобразователя многослойная нейронная сеть приводима к однослойной, то есть теряет смысл. Закон функционирования активационного элемента называют активационной функцией. Наибольшее распространение в качестве активационной получила сигмоидная функция (рис. 2), формула 1.
где S – выход сумматора; а – коэффициент, определяющий крутизну сигмоида.
Рис 2. График сигмоидной функции Кроме сигмоидной функции, довольно часто используются единичный скачок и линейный порог (гистерезис). В отличие от единичного скачка и гистерезиса сигмоид имеет производную на всей области определения, причем производная очень просто выражается через саму функцию: f`(S)=af(S)(1-f(S)). Это свойство имеет большое значение и используется при построении алгоритмов обучения. Можно отметить, что при увеличении а сигмоид приближается к функции единичного скачка, а при а=0 вырождается в горизонтальную линию f(S)=0,5.
Кратко, не вдаваясь в детали, нейрон можно представить как некий элемент, обладающий группой однонаправленных входных связей, называемых синапсами, и один выход, называемый аксоном – выходную связь. Каждый синапс характеризуется величиной синаптической связи или ее весом wi, который по физическому смыслу эквивалентен электрической проводимости. Компактно закон функционирования нейрона можно записать следующим образом: y=f((x,w)+T), (2) где f – функция активации; x – вектор входных сигналов; w – вектор весов синаптических связей; Т – пороговое значение; (x,w)– скалярное произведение. От порога Т можно освободиться, добавив нейрону еще один фиктивный вход х0 = 1 и соответственно w0 = Т. Функції активації нейрона Функція активації може бути лінійною з насиченням, релейного(порогової), релейного із зоною нечутливості, квадратичної,сигмоїдальної і т.п. Параметри функцій активацій можуть бути як фіксованими, так і настроюються. [2]
Жорстка порогова ф-я Лінійна порогова ф-я Сигмоїдальна ф-я
Нелинейная функция f называется активационной и может иметь различный вид, как показано на рисунке 2. Одной из наиболее распространеных является нелинейная функция с насыщением, так называемая логистическая функция или сигмоид (т.е. функция S-образного вида)[2]:
При уменьшении a сигмоид становится более пологим, в пределе при a=0 вырождаясь в горизонтальную линию на уровне 0.5, при увеличении a сигмоид приближается по внешнему виду к функции единичного скачка с порогом T в точке x=0. Из выражения для сигмоида очевидно, что выходное значение нейрона лежит в диапазоне [0,1]. Одно из ценных свойств сигмоидной функции – простое выражение для ее производной, применение которого будет рассмотрено в дальнейшем.
Следует отметить, что сигмоидная функция дифференцируема на всей оси абсцисс, что используется в некоторых алгоритмах обучения. Кроме того она обладает свойством усиливать слабые сигналы лучше, чем большие, и предотвращает насыщение от больших сигналов, так как они соответствуют областям аргументов, где сигмоид имеет пологий наклон.
Багатошаровий персептрон Багатошаровий перцептрон Румельхарта — окремий випадок перцептрона Розенблатта, в якому один алгоритмзворотного поширення помилки навчає всі шари. На жаль, назва з історичних причин не відображає особливості даного виду перцептрона, тобто не пов'язана з тим, що в ньому кілька шарів (тому що кілька шарів було і у перцептрона Розенблатта). Особливістю є наявність більш ніж одного учня шару (як правило — два чи три, для застосування більшої кількості наразі немає обґрунтування — втрачається швидкість без придбання якості). Необхідність у великій кількості шарів-учнів відпадає, оскільки теоретично єдиного прихованого шару достатньо, щоб перекодувати вхідний сигнал таким чином, щоб отримати лінійну карту для вихідного сигналу. Але є припущення, що, використовуючи більше число шарів, можна зменшити число елементів у них, тобто сумарне число елементів у шарах буде менше, ніж при використанні одного прихованого шару.
OUTjl – вихідний сигнал j-нейрону в l-шарі, знаходиться як функція активації
де n – кількість нейронів у попередньому шарі
Всі входи нейрона = к-сті нейронів у попередньому шарі Всі входи можна представити у вигляді вектора ( Матмодель багатошарового персептрона має вигляд:
Вибір кількості шарів у БШП Сьогодні існують формули для оцінки кількості нейронів у прихованому шарі БШП [3], але при цьому остаточна кількість нейронів уточнюється експериментально. Нейрони вихідного шару БШП мають лінійну функцію активації, що підсумовує вхідні зважені величини і поділяє результат на константу. Функції активації нейронів схованого шару БШП можуть мати найрізноманітніший вид, але, як правило, функція активації належить до класу сигмоїдальних функцій, до яких належать, наприклад, логистична і тангенціальна функція, що стискають вхідні значення в діапазон [0 1] і [-1 1] відповідно. Для БШП, що розглядаєтся в якості активаційної функції нейронів прихованого шару, обрано тангенціальну функцію, застосування якої в цьому випадку дозволяє зменшити середньоквадратичну похибку навчання мережі при меншій кількості нейронів у шарі і підвищити швидкість обчислень. Середньоквадратична похибка навчання БШП E розраховується як різниця між еталонним і вихідним вектором за формулою E = Σ (yi – y*i) 2 /n, (1) де yi – значення вектора цілей; y*i – значення виходу БШП; n – кількість поданих прикладів навчання. Для навчання БШП використовується алгоритм ЗПП на основі методу Левенберга-Маркара, що полягає в поширенні сигналів похибки від виходів ШНМ до її входів, у напрямку, зворотному прямому поширенню сигналів у звичайному режимі роботи. Алгоритм знаходить компроміс між різними навчальними прикладами і змінює ваги зв’язків нейронів так, щоб зменшити сумарну похибку Е [9, 14]. Метод Левенберга-Маркара для навчання ШНМ [10, 12], є одним з найрозповсюдженіших алгоритмів і дозволяє значно скоротити час навчання, а також зменшити середньоквадратичну похибку навчання мережі. При цьому властиві алгоритмові обмеження, такі як, наприклад, можливість застосування алгоритму для навчання БШП невеликого розміру з одним виходом, є цілком припустимими для розв’язання задачі визначення місця КЗ на ЛЕП. Одним з факторів, що впливають на середньоквадратичну похибку навчання є кількість епох навчання, при цьому одна епоха відповідає часу, за який на вхід мережі подається вся навчальна вибірка один раз. На рис. 3 показано залежність похибки навчання Е БШП на основі методу Левенберга-Маркара від кількості епох навчання для навчальної вибірки при зміні перехідного опору від 0 до 15 Ом із кроком дискретизації 3 Ом. Контрольоване навчання Величезна більшість рішень отримана від нейромереж з контрольованим навчанням, де біжучий вихід постійно порівнюється з бажаним виходом. Ваги на початку встановлюються випадково, але під час наступних ітерації коректуються для досягнення близької відповідності між бажаним та біжучим виходом. Створені методи навчання націлені на мінімізації біжучих похибок всіх елементів обробки, яке створюється за якийсь час неперервною зміною синаптичних ваг до досягнення прийнятної точності мережі. Перед використанням, нейромережа з контрольованим навчанням повинна бути навченою. Фаза навчання може тривати багато часу, зокрема, у прототипах систем, з невідповідною процесорною потужністю навчання може займати декілька годин. Навчання вважається закінченим при досягненні нейромережею визначеного користувачем рівня ефективності. Цей рівень означає, що мережа досягла бажаної статистичної точності, оскільки вона видає бажані виходи для заданої послідовності входів. Після навчання ваги з'єднань фіксуються для подальшого застосування. Деякі типи мереж дозволяють під час використання неперервне навчання, з набагато повільнішою оцінкою навчання, що допомагає мережі адаптуватись до повільно змінюючихся умов. Навчальні множини повинні бути досить великими, щоб містити всю необхідну інформацію для виявлення важливих особливостей і зв'язків. Але і навчальні приклади повинні містити широке різноманіття даних. Якщо мережа навчається лише для одного прикладу, ваги старанно встановлені для цього прикладу, радикально змінюються у навчанні для наступного прикладу. Попередні приклади при навчанні наступних просто забуваються. В результаті система повинна навчатись всьому разом, знаходячи найкращі вагові коефіцієнти для загальної множини прикладів. Наприклад, у навчанні системи розпізнавання піксельних образів для десяти цифр, які представлені двадцятьма прикладами кожної цифри, всі приклади цифри "сім" не доцільно представляти послідовно. Краще надати мережі спочатку один тип представлення всіх цифр, потім другий тип і так далі. Головною компонентою для успішної роботи мережі є представлення і кодування вхідних і вихідних даних. Штучні мережі працюють лише з числовими вхідними даними, отже, необроблені дані, що надходять із зовнішнього середовища повинні перетворюватись. Додатково необхідне масштабування, тобто нормалізація даних відповідно до діапазону всіх значень. Попередня обробка зовнішніх даних, отриманих за допомогою сенсорів, у машинний формат спільна для стандартних комп'ютерів і є легко доступною. Якщо після контрольованого навчання нейромережа ефективно опрацьовує дані навчальної множини, важливим стає її ефективність при роботі з даними, які не використовувались для навчання. У випадку отримання незадовільних результатів для тестової множини, навчання продовжується. Тестування використовується для забезпечення запам'ятовування не лише даних заданої навчальної множини, але і створення загальних образів, що можуть міститись в даних. Неконтрольоване навчання Неконтрольоване навчання може бути великим надбанням в майбутньому. Воно проголошує, що комп'ютери можуть самонавчатись у справжньому роботизованому сенсі. На даний час, неконтрольоване навчання використовується мережах відомих, як самоорганізовані карти (self organizing maps), що знаходяться в досить обмеженому користуванні, але доводячи перспективність самоконтрольованого навчання. Мережі не використовують зовнішніх впливів для коректування своїх ваг і внутрішньо контролюють свою ефективність, шукаючи регулярність або тенденції у вхідних сигналах та роблять адаптацію згідно навчальної функції. Навіть без повідомлення правильності чи неправильності дій, мережа повинна мати інформацію відносно власної організації, яка закладена у топологію мережі та навчальні правила. Алгоритм неконтрольованого навчання скерований на знаходження близькості між групами нейронів, які працюють разом. Якщо зовнішній сигнал активує будь-який вузол в групі нейронів, дія всієї групи в цілому збільшується. Аналогічно, якщо зовнішній сигнал в групі зменшується, це приводить до гальмуючого ефекту на всю групу. Конкуренція між нейронами формує основу для навчання. Навчання конкуруючих нейронів підсилює відгуки певних груп на певні сигнали. Це пов'язує групи між собою та відгуком. При конкуренції змінюються ваги лише нейрона-переможця. Оцінки навчання Оцінка ефективності навчання нейромережі залежить від декількох керованих факторів. Теорія навчання розглядає три фундаментальні властивості, пов'язані з навчанням: ємність, складність зразків і обчислювальна складність. Під ємністю розуміють, скільки зразків може запам'ятати мережа, і які межі прийняття рішень можуть бути на ній сформовані. Складність зразків визначає число навчальних прикладів, необхідних для досягнення здатності мережі до узагальнення. Обчислювальна складність напряму пов'язана з потужністю процесора ЕОМ. Правила навчання У загальному використанні є багато правил навчання, але більшість з цих правил є деякою зміною відомого та найстаршого правила навчання, правила Хеба. Дослідження різних правил навчання триває, і нові ідеї регулярно публікуються в наукових та комерційних виданнях. Представимо декілька основних правил навчання. Правило Хеба. Опис правила з'явився у його книзі "Організація поведінки" у 1949 р. "Якщо нейрон отримує вхідний сигнал від іншого нейрону і обидва є високо активними (математично мають такий самий знак), вага між нейронами повинна бути підсилена". При збудженні одночасно двох нейронів з виходами (хj, уі) на k -тому кроці навчання вага синаптичного з'єднання між ними зростає, в інакшому випадку - зменшується, тобто D Wij (k)= r xj (k) yi (k), де r - коефіцієнт швидкості навчання. Може застосовуватись при навчанні "з вчителем" і "без вчителя". Правило Хопфілда. Є подібним до правила Хеба за винятком того, що воно визначає величину підсилення або послаблення. "Якщо одночасно вихідний та вхідний сигнал нейрона є активними або неактивними, збільшуємо вагу з'єднання оцінкою навчання, інакше зменшуємо вагу оцінкою навчання". Правило "дельта". Це правило є подальшою зміною правила Хеба і є одним із найбільш загально використовуваних. Це правило базується на простій ідеї неперервної зміни синаптичних ваг для зменшення різниці ("дельта") між значенням бажаного та біжучого вихідного сигналу нейрона. D Wij = xj (di - yi). За цим правилом мінімізується середньоквадратична похибка мережі. Це правило також згадується як правило навчання Відрова-Хофа та правило навчання найменших середніх квадратів. У правилі "дельта" похибка отримана у вихідному прошарку перетворюється похідною передатної функції і послідовно пошарово поширюється назад на попередні прошарки для корекції синаптичних ваг. Процес зворотного поширення похибок мережі триває до досягнення першого прошарку. Від цього методу обчислення похибки успадкувала своє ім'я відома парадигма FeedForward BackPropagation. При використанні правила "дельта" важливим є невпорядкованість множини вхідних даних. При добре впорядкованому або структурованому представленні навчальної множини результат мережі може не збігтися до бажаної точності і мережа буде вважатись нездатною до навчання. Правило градієнтного спуску. Це правило подібне до правила "дельта" використанням похідної від передатної функції для змінювання похибки "дельта" перед тим, як застосувати її до ваг з'єднань. До кінцевого коефіцієнта зміни, що діє на вагу, додається пропорційна константа, яка пов'язана з оцінкою навчання. І хоча процес навчання збігається до точки стабільності дуже повільно, це правило поширене і є загально використовуване. Доведено, що різні оцінки навчання для різних прошарків мережі допомагає процесу навчання збігатись швидше. Оцінки навчання для прошарків, близьких до виходу встановлюються меншими, ніж для рівнів, ближчих до входу. Навчання методом змагання. На відміну від навчання Хеба, у якому множина вихідних нейронів може збуджуватись одночасно, при навчанні методом змагання вихідні нейрони змагаються між собою за активізацію. Це явище відоме як правило "переможець отримує все". Подібне навчання має місце в біологічних нейронних мережах. Навчання за допомогою змагання дозволяє кластеризувати вхідні дані: подібні приклади групуються мережею відповідно до кореляцій і представляються одним елементом. При навчанні модифікуються синаптичні ваги нейрона-переможця. Ефект цього правила досягається за рахунок такої зміни збереженого в мережі зразка (вектора синаптичних ваг нейрона-переможця), при якому він стає подібним до вхідного приклада. Нейрон з найбільшим вихідним сигналом оголошується переможцем і має можливість гальмувати своїх конкурентів і збуджувати сусідів. Використовується вихідний сигнал нейрона-переможця і тільки йому та його сусідам дозволяється коректувати свої ваги з'єднань. D Wij (k +1)= Wij (k)+ r [ xj - Wij (k)]. Розмір області сусідства може змінюватись під час періоду навчання. Звичайна парадигма повинна починатись з великої області визначення сусідства і зменшуватись під час процесу навчання. Оскільки елемент-переможець визначається по найвищій відповідності до вхідного зразку, мережі Коxонена моделюють розподіл входів. Це правило використовується в самоорганізованих картах.
Алгоритм навчання мережі
yim = f (Sjm) im =1, 2,..., Nm, m =1, 2,..., L де S - вихід суматора, w - вага зв'язку, y - вихід нейрона, b - зсув, i - номер нейрона, N - число нейронів у прошарку, m - номер прошарку, L - число прошарків, f - передатна функція.
wij (t +1)= wij (t)+ rgjx'і де wij - вага від нейрона i або від елемента вхідного сигналу i до нейрона j у момент часу t, xi ' - вихід нейрона i, r - швидкість навчання, gj - значення похибки для нейрона j. Якщо нейрон з номером j належить останньому прошарку, тоді gj = yj (1- yj)(dj - yj) де dj - бажаний вихід нейрона j, yj - поточний вихід нейрона j. Якщо нейрон з номером j належить одному з прошарків з першого по передостанній, тоді
де k пробігає всі нейрони прошарку з номером на одиницю більше, ніж у того, котрому належить нейрон j. Зовнішні зсуви нейронів b налаштовуються аналогічним образом. Тип вхідних сигналів: цілі чи дійсні. Тип вихідних сигналів: дійсні з інтервалу, заданого передатною функцією нейронів. Тип передатної функції: сигмоїдальна. В нейронних мережах застосовуються кілька варіантів сигмоїдальних передатних функцій. Функція Ферми (експонентна сигмоїда):
де s - вихід суматора нейрона, a - деякий параметр. Раціональна сигмоїда:
Гіперболічний тангенс:
Згадані функції відносяться до однопараметричних. Значення функції залежить від аргументу й одного параметра. Також використовуються багатопараметричні передатні функції, наприклад:
Сигмоїдальні функції є монотонно зростаючими і мають відмінні від нуля похідні по всій області визначення. Ці характеристики забезпечують правильне функціонування і навчання мережі. Області застосування. Розпізнавання образів, класифікація, прогнозування. Недоліки. Багатокритеріальна задача оптимізації в методі зворотного поширення розглядається як набір однокритеріальних задач - на кожній ітерації відбуваються зміни значень параметрів мережі, що покращують роботу лише з одним прикладом навчальної вибірки. Такий підхід істотно зменшує швидкість навчання. Переваги. Зворотне поширення - ефективний та популярний алгоритм навчання багатошарових нейронних мереж, з його допомогою вирішуються численні практичні задачі. Модифікації. Модифікації алгоритму зворотного поширення зв'язані з використанням різних функцій похибки, різних процедур визначення напрямку і величини кроку 49. Алгоритм навчання одношарового перцептрона
wi (t +1)= wi (t)+ r [ d (t)- y (t)] xi (t), i =1,..., N
де wі (t) - вага зв'язку від і -го елемента вхідного сигналу до нейрона в момент часу t, r - швидкість навчання (менше 1); d (t) - бажаний вихідний сигнал. Якщо мережа приймає правильне рішення, синаптичні ваги не модифікуються.
Тип вхідних сигналів: бінарні чи аналогові (дійсні). Розмірності входу і виходу обмежені при програмній реалізації тільки можливостями обчислювальної системи, на якій моделюється нейронна мережа, при апаратній реалізації - технологічними можливостями. Області застосування: розпізнавання образів, класифікація. Недоліки. Примітивні поділяючі поверхні (гіперплощини) дають можливість вирішувати лише найпростіші задачі розпізнавання. Переваги. Програмні та апаратні реалізації моделі дуже прості. Простий і швидкий алгоритм навчання. Модифікації. Багатошарові перцептрони дають можливість будувати більш складні поділяючі поверхні і тому більш поширені. Рефрактерність рефрактерність – відсутність чутливості нейрона до вхідних збуджень під час формування потенціалу дії. В момент виникнення високовольтної частини – спайка –нервова клітина не може відповісти на збудження новим потенціалом дії, тобто є абсолютно незбудливою (абсолютна рефрактерна фаза). Потім збудливість нейрона поступово відновлюється до початкового рівня (відносна рефрактерна фаза) і навіть якийсь час може його перевищувати (екзальтаційна фаза). Рефрактерність (абсолютна та відносна рефрактерні фази, екзальтаційна фаза). Абсолютна рефрактерність запропонованого нейронного елемента спостерігається з моменту досягнення потенціалом на конденсаторі (нижній імпульс на рис. 5) порогового значення і до моменту повного витікання заряду через відкритий контакт логічної цифрової інтегральної мікросхеми КР-1561-ТЛ на загальну шину. Крос-перевірка Одним з природних підходів до вирішення цієї задачі являється наступний: дані розбиваються на дві частини, по одній з який будується оцінка функції, зібраної з нейронів, на другій частині перевіряється, наскільки побудована функція близька до шуканої (така процедура називається крос-перевіркою). Відмітимо, що програма STATISTICA Neural Networks 4.0 пропонує різні способи перевірки якості побудованої мережі (звернемо увагу, що в модулі „Нейронні мережі” системи STATISTICA є Радник, що підказує вибір архітектури мережі). 57. Поверхня помилок Для контролю навчання мережі корисною є поверхня помилок, до якої ми зараз переходимо. Кожному з ваг та порогів мережі (тобто вільних параметрів моделі; їх загальне число ми позначимо через N) відповідає один вимір в багатомірному просторі. (N+1) – мірний вимір відповідає помилці мережі. Для даного набору ваг відповідну помилку мережі можна відобразити точкою в (N+1) – мірному просторі. В результаті всі такі точки утворюють деяку поверхню – поверхню помилок. Вибір алгоритму навчання
|
||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-06; просмотров: 899; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.147.104.248 (0.134 с.) |




 , (1)
, (1)

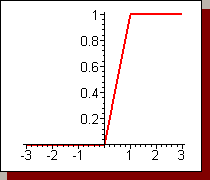

 Рис.2 а) функция единичного скачка; б) линейный порог (гистерезис); в) сигмоид – гиперболический тангенс; г) сигмоид – формула (3)
Рис.2 а) функция единичного скачка; б) линейный порог (гистерезис); в) сигмоид – гиперболический тангенс; г) сигмоид – формула (3)
 (3)
(3) (4)
(4)

 – сума зважених входів
– сума зважених входів
 – для наступних шарів
– для наступних шарів – вектор стовпець,
– вектор стовпець,  – матриця ваг всіх нейронів у шарі L,
– матриця ваг всіх нейронів у шарі L, 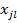 – вектор-стовпець входів j-нейрона в шарі L)
– вектор-стовпець входів j-нейрона в шарі L)
 1-й шар
1-й шар 2-й шар
2-й шар L – шар
L – шар