
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Измерения и оценка качества программного обеспечения
54. Динамическая модель Шумана Исходные данные для этой модели собираются в процессе тестирования программной системы в течение фиксированного времени или в течение случайных временных интервалов. Интервал – стадия, на которой выполняется последовательность тестов и фиксируется некоторое количество ошибок. Основные условия: · общее число команд в программе на машинном языке постоянно; · в начале компоновочных испытаний число ошибок равно некоторой постоянной величине, и по мере исправления ошибок их становится меньше. В ходе испытаний программы новые ошибки не вносятся; · ошибки изначально различимы, по суммарному числу исправленных ошибок можно судить об оставшихся; · интенсивность отказов программы пропорциональна числу остаточных ошибок. Использование модели Шумана предполагает, что тестирование проводится в несколько этапов, каждый из которых представляет собой выполнение программы на полном комплекте разработанных тестов. Ошибки выявляются, регистрируются, но не исправляются. По завершении этапа на основе собранных данных о поведении ПС на очередном этапе тестирования может быть использована модель Шумана для расчета количественных показателей надежности. После этого исправляются ошибки, обнаруженные на предыдущем этапе, при необходимости корректируются тестовые наборы, затем происходит повторное тестирование.
Статические модели надежности Статические модели принципиально отличаются от динамических прежде всего тем, что в них не учитывается время появления ошибок в процессе тестирования и не используется никаких предположений о поведении функции риска. Эти модели строятся на твердом статическом фундаменте. Модель Миллса. Использование этой модели предполагает необходимость перед началом тестирования искусственно вносить в программу некоторое количество известных ошибок. Ошибки вносятся случайным образом и фиксируются в протоколе искусственных ошибок. Специалист, проводящий тестирование, не знает ни количества, ни характера внесенных ошибок до момента оценки показателей надежности по модели миллса. Предполагается, что все ошибки (как естественные, так и искусственно внесенные) имеют равную вероятность быть найденными в процессе тестирования.
Тестируя программу в течение некоторого времени, собирают статистику об ошибках. В момент оценки надежности по протоколу искусственных ошибок все ошибки делятся на собственные и искусственные. Соотношение Дает возможность оценить N – первоначальное число ошибок в программе. В данном соотношении, которое называется формулой Миллса, S – количество искусственно внесенных ошибок, n – число найденных собственных ошибок, V – число обнаруженных к моменту оценки искусственных ошибок. Вторая часть модели связана с проверкой гипотезы выражения и тестирования N. Рассмотрим случай, когда программа содержит К собственных ошибок и внесем S рассеянных ошибок. Будем тестировать программу до тех пор, пока не обнаружим все рассеянные ошибки. В то же время количество обнаруженных исходных ошибок накапливается и запоминается n. Предполагаем, что изначально было N=n ошибок. Далее вычисляется оценка надежности модели:
как вероятность того, что в программе содержится K ошибок. Величина С является мерой доверия к модели и показывает вероятность того, насколько правильно найдено значение N. Эти два связанных между собой по смыслу соотношения образуют полезную модель ошибок: первое предсказывает возможное число первоначально имевшихся в программе ошибок, а второе используется для установления доверительного уровня прогноза. Формула для расчета С в случае, когда обнаружены не все искусственно рассеянные ошибки, модифицирована таким образом, что оценка может быть выполнена после обнаружения v (v£S) рассеянных ошибок: где числитель и знаменатель формулы при n £ К являются биноминальными коэффициентами. Простая интуитивная модель. Использование этой модели предполагает проведение тестирования двумя группами программистов (или двумя программистами в зависимости от величины программы) независимо друг от друга, использующими независимые тестовые наборы. В процессе тестирования каждая из групп фиксирует все найденные ею ошибки. Пусть первая группа обнаружила n1 ошибок, вторая n2, n12 - это число ошибок, обнаруженных как первой, так и второй группой.
Обозначим через N неизвестное количество ошибок, присутствующих в программе до начала тестирования. Тогда можно эффективность тестирования каждой из групп определить как . Эффективность тестирования можно интерпретировать как вероятность того, что ошибка будет обнаружена. Таким образом, можно считать, что первая группа обнаруживает ошибку в программе с вероятностью Отсюда получаем оценку первоначального числа ошибок программы:
Модель Миллса Использование этой модели предполагает необходимость перед началом тестирования искусственно вносить в программу некоторое количество известных ошибок. Ошибки вносятся случайным образом и фиксируются в протоколе искусственных ошибок. Специалист, проводящий тестирование, не знает ни количества, ни характера внесенных ошибок до момента оценки показателей надежности по модели миллса. Предполагается, что все ошибки (как естественные, так и искусственно внесенные) имеют равную вероятность быть найденными в процессе тестирования. Тестируя программу в течение некоторого времени, собирают статистику об ошибках. В момент оценки надежности по протоколу искусственных ошибок все ошибки делятся на собственные и искусственные. Соотношение Дает возможность оценить N – первоначальное число ошибок в программе. В данном соотношении, которое называется формулой Миллса, S – количество искусственно внесенных ошибок, n – число найденных собственных ошибок, V – число обнаруженных к моменту оценки искусственных ошибок. Вторая часть модели связана с проверкой гипотезы выражения и тестирования N. Рассмотрим случай, когда программа содержит К собственных ошибок и внесем S рассеянных ошибок. Будем тестировать программу до тех пор, пока не обнаружим все рассеянные ошибки. В то же время количество обнаруженных исходных ошибок накапливается и запоминается n. Предполагаем, что изначально было N=n ошибок. Далее вычисляется оценка надежности модели:
Величина С является мерой доверия к модели и показывает вероятность того, насколько правильно найдено значение N. Эти два связанных между собой по смыслу соотношения образуют полезную модель ошибок: первое предсказывает возможное число первоначально имевшихся в программе ошибок, а второе используется для установления доверительного уровня прогноза. Формула для расчета С в случае, когда обнаружены не все искусственно рассеянные ошибки, модифицирована таким образом, что оценка может быть выполнена после обнаружения v (v£S) рассеянных ошибок: Простая интуитивная модель Использование этой модели предполагает проведение тестирования двумя группами программистов (или двумя программистами в зависимости от величины программы) независимо друг от друга, использующими независимые тестовые наборы. В процессе тестирования каждая из групп фиксирует все найденные ею ошибки.
Пусть первая группа обнаружила n1 ошибок, вторая n2, n12 - это число ошибок, обнаруженных как первой, так и второй группой. Обозначим через N неизвестное количество ошибок, присутствующих в программе до начала тестирования. Тогда можно эффективность тестирования каждой из групп определить как . Эффективность тестирования можно интерпретировать как вероятность того, что ошибка будет обнаружена. Таким образом, можно считать, что первая группа обнаруживает ошибку в программе с вероятностью Отсюда получаем оценку первоначального числа ошибок программы:
Модель Коркорэна Модель Коркорэна относится к статическим моделям надежности ПС, так как в ней не используются параметры времени тестирования и учитывается только результат N испытаний, в которых выявлено N1 ошибок i-го типа. Модель использует изменяющиеся вероятности отказов для различных типов ошибок. Применение модели предполагает знание следующих ее показателей: · модель содержит изменяющуюся вероятность отказов для различных источников ошибок и соответственно разную вероятность их исправления; · в модели используются такие параметры, как результат только N испытаний, в которых наблюдается Ni ошибок i-го типа; · выявление в ходе N испытаний ошибки i-го типа появляется с вероятностью аi. Показатель уровня надежности R вычисляют по следующей формуле:
где N0 - число безотказных (или безуспешных) испытаний, выполненных в серии из N испытаний, k - известное число типов ошибок, ai — вероятность выявления при тестировании ошибки i-го типа, Yi - вероятность появления ошибок, при Ni > 0, Yi = ai, при Ni = 0, Yi = 0.
|
|||||||
|
|
Последнее изменение этой страницы: 2017-02-06; просмотров: 538; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.136.26.20 (0.011 с.) |



 (11)
(11)
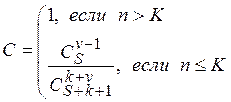 (12)
(12)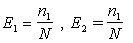
 , вторая - с вероятностью
, вторая - с вероятностью  . Тогда вероятность p12 того, что ошибка будет обнаружена обеими группами, можно принять равной
. Тогда вероятность p12 того, что ошибка будет обнаружена обеими группами, можно принять равной 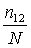 . С другой стороны, так как группы действуют независимо друг от друга, то р12 = р1р2. Получаем:
. С другой стороны, так как группы действуют независимо друг от друга, то р12 = р1р2. Получаем: 
 .
.



