Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Понятие типов и структур данных. Оперативные и внешние структуры.Стр 1 из 15Следующая ⇒
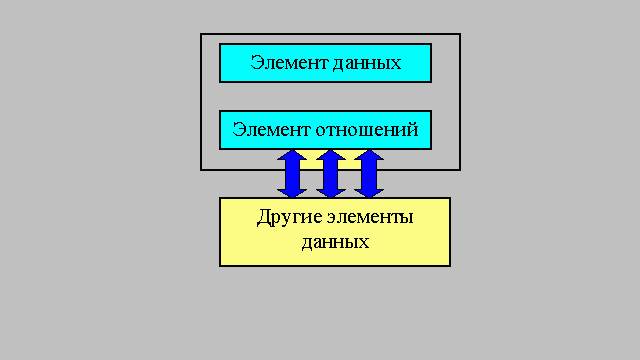
Понятие типов и структур данных. Оперативные и внешние структуры. Структуры данных - это совокупность элементов данных и отношений между ними. При этом под элементами данных может подразумеваться как простое данное так и структура данных. Под отношениями между данными понимают функциональные связи между ними и указатели на то, где находятся эти данные. Графическое представление элемента структуры данных.
Элемент отношений - это совокупность всех связей элемента с другими элементами данных, рассматриваемой структуры. S:=(D,R) Где S - структура данных, D - данные и R - отношения. Как бы сложна ни была структура данных, в конечном итоге она состоит из простых данных (смотрите рисунки ниже).
Память машины состоит из миллионов триггеров, которые обрабатывают поступающую информацию. Мы, занося информацию в компьютер, представляем ее в каком-то виде, который на наш взгляд упорядочивает данные и придает им смысл. Машина отводит поле для поступающей информации и задает ей какой-то адрес. Таким образом получается, что мы обрабатываем данные на логическом уровне, как бы абстрактно, а машина делает это на физическом уровне. Последовательность переходов от логической организации к физической показана на рисунке ниже
Стандартные и пользовательские типы данных. ТИПЫ ДАННЫХ Вматематике принято классифицировать переменные в соответствие с некоторыми важными характеристиками. Мы различаем вещественные, комплексные и логические переменные, переменные, представляющие собой отдельные значения, множества значений или множества множеств. В обработке данных понятие классификации играет такую же, если не большую роль. Мы будем придерживаться того принципа, что любая константа, переменная, выражение или функция относятся к некоторому типу. Фактически тип характеризует множество значений, которые может принимать некоторая переменная или выражение и которые может формировать функция. Вбольшинстве языков программирования различают стандартные типы данных и типы, заданные пользователем. К стандартным относят 5 типов: a) целый (INTEGER); b) вещественный (REAL); c) логический (BOOLEAN); d) символьный (CHAR); E) указательный (POINTER). К пользовательским относят 2 типа: a) перечисляемый;
b) диапазонный. Любой тип данных должен быть охарактеризован областью значений и допустимыми операциями над этим типом Данных. Целый тип - INTEGER Этот тип включает некоторое подмножество целых, размер которого варьируется от машины к машине. Если для представления целых чисел в машине используется n разрядов, причем используется дополнительный код, то допустимые числа должны удовлетворять условию -2 '<= х< 2. Считается, что все операции над данными этого типа выполняются точно и соответствуют обычным правилам арифметики. Если результат выходит за пределы представимого множества, то вычисления будут прерваны. Такое событие называется переполнением. Числа делятся на знаковые и беззнаковые. Для каждого из них имеется свой диапазон значений: а)(0..2n-1)для без знаковых чисел Рис. 1.1 При обработке машиной чисел, используется формат со знаком. Если же машинное слово используется для записи и обработки команд и указателей, то в этом случае используется формат без знака. Операции над целым типом: a)Сложение. b)Вычитание. c)Умножение. d)Целочисленное деление. e)Нахождение остатка по модулю. f) Нахождение экстремума числа (минимума и максимума) g) Реляционные операции (операции сравнения) (<,>,<=,>=, =,<>) Примеры: Adiv В = С Amod В = D С* B + D = A 7 div 3 = 2 7 mod 3 = 1 Во всех операциях, кроме реляционных, в результате получается целое число. Вещественный тип - REAL Вещественные типы образуют ряд подмножеств вещественных чисел, которые представлены в машинных форматах с плавающей точкой. Числа в формате с плавающей точкой характеризуются целочисленными значениями мантиссы и порядка, которые определяют диапазон изменения и количество верных знаков в представ- лении чисел вещественного типа. X = +/- М * q(+/-P) - полулогарифмическая форма представления числа, показана на рисунке 2. 937,56 = 93756 * 10-2 = 0,93756 * 103 Рис. 1.2 Удвоенная точность необходима для того, чтобы увеличить точность мантиссы. Логический тип - BOOLEAN Стандартный логический тип Boolean (размер-1байт) представляет собой тип данных, любой элемент которого может принимать лишь 2 значения: True и False.
Над логическими элементами данных выполняются логические операции. Основные из них: a) Отрицание (NOT) b) Конъюнкция (AND) c) Дизъюнкция (OR) Логические значения получаются также при реляционных операциях с целыми числами. Символьный тип – CHAR Тип CHAR содержит 26 прописных латинских букв и 26 строчных, 10 арабских цифр и некоторое число других графических символов, например, знаки пунктуации. Подмножества, букв и цифр упорядочены и "соприкасаются", т.е. ("А"<= х)&(х <= "Z") - х представляет собой прописную букву ("0"<= х)&(х <= "9") - х представляет собой цифру Тип CHAR содержит некоторый непечатаемый символ, пробел, его можно использовать как разделитель. Операции: a)Присваивания b)Сравнения c)Определения номера данной литеры в системе кодирования. ORD(Wi) d)Нахождение литеры по номеру. CHR(i) e)Вызов следующей литеры. SUCC(Wi) f)Вызов предыдущей литеры. PRED(Wi) Указательный тип -POINTER Переменная типа указатель является физическим носителем адреса величины базового типа. Стандартный типуказатель Pointer дает указатель, не связанный ни с каким конкретным базовым типом. Этот тип совместим с любым другим типом-указателем.Операции: a)Присваивания b)Операции с беззнаковыми целыми числами. При помощи этих операций можно вычислить адрес данных. В машинном виде эти типы занимают максимально возможную длину. Например: ABCD:1234 - значение указателя в шестнадцатеричной системе счисления - относительный адрес. Первое число (ABCD) - адрес сегмента Второе число .(1234) - адрес внутри сегмента. Получение абсолютного адреса из относительного: Для получения абсолютного адреса необходимо произвести сдвиг адреса сегмента влево, и к полученному числу прибавить адрес внутреннего сегмента. Например: 1) Сдвигаем ABCD на один разряд влево. Получаем ABCD0. 2) Прибавляем 1234. Полученный результат и является абсолютным адресом. ABCD0 1234 --------- ACF04 – абсолютный адрес данного числа. Наиболее важной характеристикой является изменчивость структуры во времени. По признаку физического размещения структуры данных различают оперативные и файловые структуры. Структуры данных, размещаемые в оперативной памяти, называют оперативными структурами. Файловые структуры соответствуют структурам данных внешней памяти. Оперативная память является быстрой, а внешняя — медленной. 2. СТАНДАРТНЫЕ и пользовательские типы Все типы данных можно разделить на две группы: скалярные и структурированные (составные). Скалярные типы, в свою очередь, делятся на стандартные и пользовательские. Стандартные типы данных предлагаются пользователям разработчиками системы. К ним относятся целочисленные, вещественные, литерные, булевские типы данных и указатели. Пользовательские типы данных разрабатываются пользователями системы программирования.
СТРУКТУРЫ ДАННЫХ Структуры данных - это совокупность элементов данных и отношений между ними. При этом под элементами данных может подразумеваться как простое данное так и структура данных. Под отношениями между данными понимают функциональные связи между ними и указатели на то, где находятся эти данные. Графическое представление элемента структуры данных. Элемент отношений - это совокупность всех связей элемента с другими элементами данных, рассматриваемой структуры.
S:=(D,R) Где S - структура данных, D - данные и R - отношения. Как бы сложна ни была структура данных, в конечном итоге она состоит из простых данных. Внутренний мир ЭВМ далеко не так прост, как мы думаем. Память машины состоит из миллионов триггеров, которые обрабатывают поступающую информацию. Мы, занося инф-циюв компьютер, представляем еѐ вкаком-товиде, который на наш взгляд упорядочивает данные и придаѐт им смысл. Машина отводит поле для поступающейинф-циии задаѐт ейкакой-тоадрес. Т.о. получается, что мы обрабатываем данные на логическом уровне, как бы абстрактно, а машина делает это на физическом уровне.
Векторы Самая простая статическая структура - это вектор. Вектор - это чисто линейная упорядоченная структура, где отношение между ее элементами есть строго выраженная последовательность элементов структуры (рисункок ниже).
Каждый элемент вектора имеет свой индекс, определяющий положение данного элемента в векторе. Поскольку индексы являются целыми числами, над ними можно производить операции и, таким образом, вычислять положение элемента в структуре на логическом уровне доступа. Для доступа к элементу вектора, достаточно просто указать имя вектора (элемента) и его индекс. Для доступа к этому элементу используется функция адресации, которая формирует из значения индекса адрес слота, где находится значение исходного элемента. Для объявления в программе вектора необходимо указать его имя, количество элементов и их тип (тип данных). Пример: var M1: Array [1..100] of integer; M2: Array [1..10] of real; Вектор состоит из совершенно однотипных данных и количество их строго определено. Массивы В общем случае элемент массива - это есть элемент вектора, который сам по себе тоже является элементом структуры (рисунок ниже).
Для доступа к элементу двумерного массива необходимы значения пары индексов (номер строки и номер столбца, на пересечении которых находится элемент). На физическом уровне двумерный массив выглядит также, как и одномерный (вектор), причем трансляторы представляют массивы либо в виде строк, либо в виде столбцов.
Записи Запись представляет из себя структуру данных последовательного типа, где элементы структуры расположены один за другим как в логическом, так и в физическом представлении. Запись предполагаетмножество элементов разного типа. Элементы данных в записи часто называют полями записи.
Пример:
Логическая структура записи может быть представлена как в графическом виде, так и в табличном.
Элемент записи может включать в себя записи. В этом случае возникает сложная иерархическая структура данных. Пример: Необходимо заполнить запись о студенте, содержащую следующую информацию: N - порядковый номер студента; Имя студента, в составе которого должны быть: Фамилия, Имя, Отчество; Анкетные данные студента: год рождения, место рождения, родители: мать, отец; Факультет; Группа; Оценки, полученные в сессию: по английскому языку и микропроцессорам. Ниже приведены два логических представления структуры этой записи.
Получена четырехуровневая иерархическая структура данных. Информация содержится в листьях, остальные узлы служат для указания пути к листьям. 1-ый уровень Студент = запись 2-ой уровень Номер 2-ой уровень Имя = запись 3-ий уровень Фамилия 3-ий уровень Имя 3-ий уровень Отчество 2-ой уровень Анкетные данные = запись 3-ий уровень Место рождения 3-ий уровень Год рождения 3-ий уровень Родители = запись 4-ый уровень Мать 4-ый уровень Отец 2-ой уровень Факультет 2-ой уровень Группа 2-ой уровень Оценки = запись 3-ий уровень Английский 3-ий уровень Физика Эта структура называется вложенной записью. Операции над записями: 1. Прочтение содержимого поля записи. 2. Занесение информации в поле записи. 3. Все операции, которые разрешаются над полем записи, соответствующего типа.
Таблицы Таблица - это конечный набор записей (рисунок ниже).
При задании таблицы указывается количество содержащихся в ней записей. Пример:
Type ST = Record Num: Integer; Name: String[15]; Fak: String[5]; Group: String[10]; Angl: Integer; Physic: Integer; var Table: Array [1..19] of St;
Элементом данных таблицы является запись. Поэтому операции, которые производятся с таблицей - это операции, производимые с записью.
Операции с таблицами: 1. Поиск записи по заданному ключу. 2. Занесение новой записи в таблицу.
Ключ - это идентификатор записи. Для хранения этого идентификатора отводится специальное поле. Составной ключ - ключ, содержащий более двух полей.
Списки Списки - это набор связанных элементов данных, которые в общем случае могут быть разного типа. Пример списка: E1, E2,........, En,... n > 1 и не зафиксировано. Количество элементов списка может меняться в процессе выполнения программы. Различают 2 вида списков: 1) Несвязные 2) Связные В несвязных списках связь между элементами данных выражена неявно. В связных списках в элемент данных заносится указатель связи с последующим или предыдущим элементом списка. Стеки, деки и очереди - это несвязные списки. Кроме того они относятся к последовательным спискам, в которых неявная связь отображается их последовательностью. Стеки Очередь вида LIFO (Last In First Out - Последним пришел, первым ушел), при которой на обслуживание первым выбирается тот элемент очереди, который поступил в нее последним, называется стеком. Это одна из наиболее употребляемых структур данных, которая оказывается весьма удобной при решении различных задач.
В силу указанной дисциплины обслуживания, в стеке доступна единственая его позиция, которая называется вершиной стека- это позиция, в которой находится последний по времени поступления в стек элемент. Когда мы заносим новый элемент в стек, то он помещается поверх прежней вершины и теперь уже сам находится в вершине стека. Выбрать элемент можно только из вершины стека; при этом выбранный элемент исключается из стека, а в его вершине оказывается элемент, который был занесен в стек перед выбранным из него элементом (структура с ограниченным доступом к данным). Графически стек можно представить следующим образом:
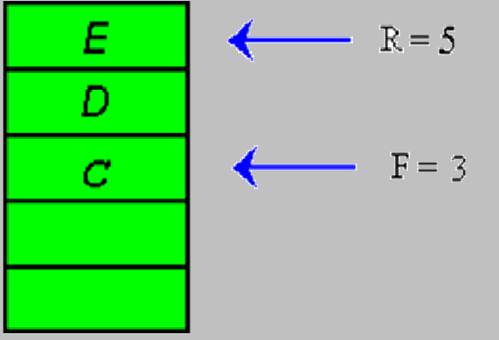
Первый элемент заносится вниз стека. Выборка из стека осуществляется с вершины, поэтому стек является структурой с ограниченным доступом. Операции, производимые над стеками: 1. Занесение элемента в стек. Push(S,I), где S - идентификатор стека, I - заносимый элемент. 2. Выборка элемента из стека. Pop(S) 3. Определение пустоты стека. Empty(S) 4. Прочтение элемента без его выборки из стека. StackTop(S) 5. Определение переполнения стека (для полустатических структур) Full(S) Очередь Понятие очереди всем хорошо известно из повседневной жизни. Элементами очереди в общем случае являются заказы на то или иное обслуживание. В программировании имеется структура данных, которая называется очередью. Эта структура данных используется, например, для моделирования реальных очередей с целью определения их характеристик при данном законе поступления заказов и дисциплине их обслуживания. По своему существу очередь, реализованная на массиве, является полустатической структурой - с течением времени и длина очереди, и состав могут изменяться. На рисунке ниже приведена очередь, содержащая четыре элемента — А, В, С и D. Элемент А расположен в начале очереди, а элемент D — в ее конце. Элементы могут удаляться только из начала очереди, то есть первый помещаемый в очередь элемент удаляется первым. По этой причине очередь часто называют списком, организованным по принципу «первый размещенный первым удаляется» в противоположность принципу стековой организации — «последний размещенный первым удаляется».
Дисциплину обслуживания, в которой заказ, поступивший в очередь первым, выбирается первым для обслуживания (и удаляется из очереди), называется FIFO (First In First Out - Первым пришел, первым ушел). Очередь открыта с обеих сторон. Таким образом, изъятие компонент происходит из начала очереди, а запись- в конец. В этом случае вводят два указателя: один - на начало очереди, второй- на ее конец. Реальная очередь создается в памяти ЭВМ в виде одномерного массива с конечным числом элементов, при этом необходимо указать тип элементов очереди, а также необходима переменная в работе с очередью. Физически такая очередь занимает сплошную область памяти и элементы следуют друг за другом, как в последовательном списке. Операции, производимые над очередью: Для очереди определены три операции. Операция insert (q,x) помещает элемент х в конец очереди q. Операция remove(q) удаляет элемент из начала очереди q и присваивает его значение переменной х. Третья операция, empty (q), возвращает значение true или false в зависимости от того, является ли данная очередь пустой или нет. Кроме того. Учитывая то, что полустатическая очередь реализуется на одномерном массиве, необходимо следить за возможностью его переполнения. С этой целью вводится четвертая операция full(q). Операция insert теоретически может быть выполнена всегда, поскольку на количество элементов, которые может содержать очередь, никаких ограничений не накладывается. На практике для полустатической очереди, конечно же, накладываются ограничения, так как количество элементов в массиве всегда конечное. Операция remove применима только к непустой очереди, поскольку невозможно удалить элемент из очереди, не содержащей элементов. Результатом попытки удалить элемент из пустой очереди является возникновение исключительной ситуации потеря значимости. Операция empty, разумеется, выполнима всегда. Для очереди вводят два указателя: один - на начало очереди (F), второй- на ее конец (R). Если очередь пуста, то F = 1, а R = 0. Данные значения являются начальными. R < F – условие пустоты очереди. Рассмотрим алгоритмы основных операций над очередью при таких условиях Full (q) if R = maxQ then full = true else full = false endif return
Empty (q) if R < F then empty = true else empty = false endif return
Insert (q, x) Full (q) if full = true then ‘переполнение’ stop return endif R = R + 1 q(R) = x return
Remove (q) Empty (q) if empty = true then ‘пусто’ stop return endif x = q(F) F = F + 1 return Рассмотрим теперь примеры работы с очередью с использованием стандартных функций. Для реализации очереди будем использовать небольшой массив из 5 элементов. maxQ = 5 R = 0, F = 1 Условие пустоты очереди R < F (0 < 1)
Произведем вставку элементов A, B и C в очередь: Insert (q, A); Insert (q, B); Insert (q, C);
Убираем элементы A и B из очереди: Remove (q); Remove (q);
Добавляем элементы D и E: Insert (q, D); Insert (q, E);
Убираем элементы С,D и E из очереди: Remove (q); Remove (q); Remove (q).
Возникла абсурдная ситуация, при которой очередь является пустой (R < F), однако новый элемент разместить в ней нельзя, так как R = maxQ. Одним из решений возникшей проблемы может быть модификация операции Remove (q) таким образом, что при удалении очередного элемента вся очередь смещается к началу массива. Переменная F больше не требуется, поскольку первый элемент массива всегда является началом очереди. Пустая очередь представлена очередью, для которой значение R равно нулю.
Произведем вставку элементов A, B и C в очередь: Insert (q, A); Insert (q, B); Insert (q, C);
Убираем элемент A из очереди: Remove (q)
Операция remove (q) может быть в этом случае реализована следующим образом: Remove (q) x = q(1) for i =1 to R-1 q(i) = q(i+1) next i R =R-1 return
Однако этот метод весьма непроизводителен. Каждое удаление требует перемещения всех оставшихся в очереди элементов. Кроме того, операция удаления элемента из очереди логически предполагает манипулирование только с одним элементом, т. е. с тем, который расположен в начале очереди. Другой способ предполагает рассматривать массив, который содержит очередь в виде замкнутого кольца. Это означает, что даже в том случае, если последний элемент занят, новое значение может быть размещено сразу же за ним на месте первого элемента, если этот первый элемент пуст. Предположим, что очередь содержит три элемента - в позициях 3, 4 и 5 пятиэлементного массива. Хотя массив и не заполнен, последний элемент очереди занят.
Если теперь делается попытка поместить в очередь элемент G, то он будет записан в первую позицию массива. Первый элемент очереди есть q(3), за которым следуют элементы q (4), q(5) и q(1).
К сожалению, условие R<F больше не годится для проверки очереди на пустоту. Одним из способов решения этой проблемы является введение соглашения, при котором значение F есть индекс элемента массива, немедленно предшествующего первому элементу очереди, а не индекс самого первого элемента. В этом случае, поскольку R содержит индекс последнего элемента очереди, условие F = R подразумевает, что очередь пуста. Перед началом работы с кольцевой очередью в F и R устанавливается значение последнего индекса массива maxQ, а не 1 и 0. Поскольку R = F, то очередь изначально пуста.
Основные операции с кольцевой очередью: 1. Вставка элемента q в очередь x 2. Извлечение элемента из очереди x 3. Проверка очереди на пустоту 4. Проверка очереди на переполнение Операция Empty(q) if F = R then empty = true else empty = false endif return
Операция Remove(q) empty (q) if empty = true then “пусто” stop endif if F = maxQ then F =1 else F = F+1 endif x = q(F) return Значение F должно быть модифицировано до момента извлечения элемента. Переполнение очереди происходит в том случае, если весь массив уже занят элементами очереди, и при этом делается попытка разместить в ней еще один элемент. Исходное состояние очереди
Поместим в очередь элемент G.
Если произвести следующую вставку, то массив становится целиком заполненным, и попытка произвести еще одну вставку приводит к переполнению. Это регистрируется тем фактом, что F = R, то есть это соотношение как раз и указывает на переполнение. Очевидно, что при такой реализации нет возможности сделать различие между пустой и заполненной очередью. Одно из решений состоит в том, чтобы пожертвовать одним элементом массива и позволить очереди расти до объема, на единицу меньшего максимального. Предыдущий рисунок иллюстрирует именно это соглашение. Попытка разместить в очереди еще один элемент приведет к переполнению. Проверка на переполнение в функции insert производится после установления нового значения для R, в то время как проверка на потерю значимости в функции remove производится сразу же после входа в подпрограмму до момента обновления значения F. Функция Insert(q,x) может быть записана следующим образом: if R = maxQ then R = 1 else R = R+1 endif ‘проверка на переполнение’ if R = F then print «переполнение очереди» stop endif q (R) =x return
Связные списки С точки зрения логического представления различают линейные и нелинейные списки. К линейным спискам относятся односвязные и двусвязные списки. К нелинейным - многосвязные. Элемент списка в общем случае представляет собой информационное поле и одно или несколько полей указателей. Данные динамические структуры наиболее распростанены. Односвязные списки Элемент односвязного списка содержит, как минимум, два поля: информационное поле (info) и поле указателя (ptr).
Особенностью указателя является то, что он дает только адрес последующего элемента списка. Поле указателя последнего элемента в списке является пустым (NIL). LST - указатель на начало списка. Список может быть пустым, тогда LST будет равен NIL. Доступ к элементу списка осуществляется только от его начала, то есть обратной связи в этом списке нет. При дальнейшем изучении односвязных списков мы будем использовать следующую терминологию: p - указатель node(p) – узел, на который ссылается указатель p (при этом неважно в какое место изображения элемента (узла) списка он направлен на рисунке) ptr(p) – ссылка на последующий элемент узла node(p) ptr(ptr(p)) – ссылка последующего для node(p) узла на последующий для него элемент.
Двусвязный список Использование однонаправленных списков при решении ряда задач может вызвать определенные трудности. Дело в том, что по однонаправленному списку можно двигаться только в одном направлении, от заглавного звена к последнему звену списка. Между тем нередко возникает необходимость произвести какую-либо обработку элементов, предшествующих элементу с заданным свойством. Однако после нахождения элемента с этим свойством в односвязном списке у нас нет возможности получить достаточно удобный и быстрый доступ к предыдущим элементам. Для достижения этой цели придется усложнить алгоритм, что неудобно и нерационально. Для устранения этого неудобства добавим в каждое звено списка еще одно поле, значением которого будет ссылка на предыдущее звено списка. Динамическая структура, состоящая из элементов такого типа, называется двунаправленным или двусвязным списком. Двусвязный список характеризуется тем, что у любого элемента есть два указателя. Один указывает на предыдущий (левый) элемент (L), другой указывает на последующий (правый) элемент (R). Фактически двусвязный список это два односвязных списка с одинаковыми элементами, записанные в противоположной последовательности.
Кольцевой двусвязный список Кольцевые двусвязные списки получают следующим образом: в качестве значения поля R последнего элемента принимают ссылку на первый элемент, а в качестве значения поля L первого элемента - ссылку на последний элемент.
Операция FreeNode (P) При освобождении элемента из функционального списка, он заносится в свободный список. FreeNode(P) Ptr(P) = Avail Avail = P return
Метод счетчиков В каждый элемент многосвязного списка вставляется поле счетчика, который считает количество ссылок на данный элемент. Когда счетчик элемента оказывается в нулевом состоянии, а поля указателей элемента находятся в состоянии nil, этот элемент может быть возвращен в пул свободных элементов. Второй способ утилизации - метод маркера (сборки мусора, то есть неиспользуемых элементов) Метод маркера Если с каким-то элементом установлена связь, то однобитовое поле элемента (маркер) устанавливается в “1”, иначе - в “0”. По сигналу переполнения отыскиваются элементы, у которых маркер установлен в ноль, т. е. включается программа сборки мусора, которая просматривает всю отведенную память и возвращает в список свободных элементов все элементы, не помеченные маркером.
Проверка очереди на пустоту Empty(Q) If F = nil then print “Очередь пуста” Stop endif return Операция удаления из очереди Операция удаления из очереди должна происходить из ее начала. Remove(Q) If F = nil then print “Очередь пуста” Stop endif P = F F = Ptr(P) X = Info(P) FreeNode(P) return
Операция вставки в очередь Insert(Q, x) Операция вставки в очередь должна осуществляться к ее концу. Insert(Q, x) P = GetNode Info(P) = x Ptr(P) = Nil Ptr(R)= P R = P return
Пример алгоритма решения задачи извлечения элементов из списка по заданному признаку. Требуется просмотреть список и удалить элементы, у которых информационные поля равны 4. Обозначим P - рабочий указатель; в начале процедуры P = Lst.
Алгоритм x = 4 Q = nil P = Lst while P <> nil do if info(P) = x then if Q = nil then Pop(Lst) P = Lst else DelAfter(Q) endif else Q = P P = Ptr(P) endif endwhile return
Пример алгоритма решения задачи вставки заданного элемента в упорядоченный список. Дан упорядоченный по возрастанию info - полей список. Необходимо вставить в этот список элемент со значением X, не нарушив упорядоченности списка. Пусть X = 16 Начальные условия: Q = Nil, P = Lst
Алгоритм X = 16 Q =Nil P = Lst while (P <> nil) and (X > info(P)) do Q = P P = Ptr(P) endwhile if Q = nil then Push(Lst, X) endif InsAfter(Q, X) return
Пример моделирования с помощью нелинейного списка Пусть имеется дискретная система, в графе состояния которой узлы - это состояния, а ребра - переходы из состояния в состояние.
Входной сигнал в систему это X. Реакцией на входной сигнал является выработка выходного сигнала Y и переход в соответствующее состояние. Граф состояния дискретной системы можно представить в виде двусвязного нелинейного списка. При этом в информационных полях должна записываться информация о состояниях системы и ребрах. Указатели элементов должны формировать логические ребра системы Для реализации вышесказанного: 1) должен быть создан список, отображающий состояния системы (1, 2, 3); 2) должны быть созданы списки, отображающие переходы по ребрам из соответствующих состояний. Реализация графа в виде нелинейного списка можно представить рисунка ниже:
В общем случае при реализации многосвязной структуры получается сеть.
Деревья Дерево - нелинейная связанная структура данных Дерево характеризуется следующими признаками: - дерево имеет один элемент, на который нет ссылок от других элементов. Этот элемент называется корнем дерева; - в дереве можно обратиться к любому элементу путем прохождения конечного числа ссылок (указателей); - каждый элемент дерева связан только с одним предыдущим элементом. Любой узел дерева может быть промежуточным либо терминальным (листом). На рисунке промежуточными являются элементы M1, M2; листьями - A, B, C, D, E. Характерной особенностью терминального узла является отсутствие ветвей.
Высота дерева - это количество уровней дерева. У дерева на рисунке высота равна двум.
Количество ветвей, растущих из узла дерева, называется степенью исхода узла (на рисунке для M1 степень исхода 2, для М2 - 3).
Для описания связей между узлами дерева применяют также следующую терминологию: М1 - “отец” для элементов А и В. А и В - “сыновья” узла М1. Деревья могут классифицироваться по степени исхода: 1) если максимальная степень исхода равна m, то это - m-арное дерево; 2) если степень исхода равна либо 0, либо m, то это - полное m-арное дерево; 3) если максимальная степень исхода равна 2, то это - бинарное дерево; 4) если степень исхода равна либо 0, либо 2, то это - полное бинарное дерево. Представление деревьев
Наиболее удобно деревья представлять в памяти ЭВМ в виде связанных списков. Элемент списка должен содержать информационные поля, в которых могут содержаться значение ключа узла и другая хранимая информация, а также поля-указатели, число которых равно степени исхода.
Бинарные деревья Согласно представлению деревьев в памяти ЭВМ каждый элемент бинарного дерева является записью, содержащей четыре поля. Значения этих полей - соответственно ключ записи, текст записи, ссылка на элемент влево – вниз и ссылка на элемент вправо – вниз. Бинарные деревья являются наиболее используемой разновидностью деревьев. Формат элемента бинарного дерева представлен на рисунке ниже
Функция создания элемента бинарного дерева V = MakeTree (key, rec) V - указатель на создаваемый элемент динамической структуры Алгоритм функции Maketree(key,rec) p = getnode r (p) = rec k (p) = key v = p left (v)= nil right (v) = nil return Операция V = MakeTree(Key, Rec) - создает элемент (узел дерева) с двумя указателями и двумя полями (ключевым и информационным).
Упорядочное бинарное дерево В упорядоченном бинарном дереве левый сын имеет ключ меньший, чем у отца, а значение ключа правого сына больше значения ключа отца. Построим бинарное дерево из следующих элементов: 50, 46, 61, 48, 29, 55, 79.
Получено идеально сбалансированное дерево - дерево, в котором левое и правое поддеревья имеют уровни, отличающиеся не более чем на единицу.
Операция удаления поддерева Необходимо указать узел, к которому подсоединяется удаляемое поддерево и указатель корня этого поддерева. Исключение поддерева состоит в том, что разрывается связь с удаляемым поддеревом, т. е. указатель элемента, связанного с узлом-корнем удаляемого поддерева, устанавливается в nil. Cтепень исхода данного узла уменьшается на единицу. Операция вставки поддерева Необходимо знать указатель корня вставляемого поддерева и узел, к которому подвешивается поддерево. Установить указатель этого узла на корень поддерева, а степень исхода данного узла увеличить на единицу. При этом, в общем случае, необходимо произвести перенумерацию сыновей узла, к которому подвешивается поддерево. Алгоритмы вставки и удаления будут рассмотрены позднее. Алгоритм поиска в списке q = nil p = table while (p <> nil) do if k(p) = key then search = p return endif q = p p = nxt(p) endwhile s = getnode k(s) = key r(s) = rec nxt(s) = nil if q = nil then table = s else nxt(q) = s endif search = s return
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-02-05; просмотров: 1517; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.217.144.32 (1.203 с.) |