
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Двумерные выборки и парная регрессия
При исследовании по выборке зависимости между двумя СВ X и Y методами корреляционного анализа изучается усредненный закон поведения каждой из величин в соответствии со значениями другой величины, а также мера зависимости между ними. Пусть мы имеем выборку n парных значений СВ X и У(х1, у1), (х2, у2),..., (хn, уn), представленных соответствующей таблицей, причем некоторые значения могут повторятся, или благодаря естественному разбросу экспериментальных данных одному значению переменной соответствует несколько значений другой. Для изучения по выборке общей картины корреляционной зависимости случайных величин X и У их парные значения наносятся соответствующими точками на координатной плоскости. Такое изображение называется корреляционным полем. По нему делается вывод о том, линейную или нелинейную функциональные зависимости (эмпирические уравнения регрессии) следует искать между X и У (см. рис, 4а и 46), или она не существует (рис. 4в).

Рис. 4 При большом числе наблюдений (n ³50) для дальнейшего анализа корреляционной зависимости между СВХ и У обычно используют корреляционные таблицы. С этой целью варианты одной СВ, например X, записываются в первую строку таблицы, а варианты другой У в первый столбец. В соответствующую клетку на пересечении значений хi, и yi заносят частоты nху. Сумма nv по строкам и столбцам определяег соответствующие частоты nх и nу. Объем выборки Если в корреляционной таблице остались пустые клетки, то это означает, что в выборке отсутствуют соответствующие сочетания значений СВ и X и У. Ниже представлена подобная корреляционная таблица 3 системы двух случайных величин (X, У), используемая в дальнейшем при расчете типового примера. Таблица 3
Зафиксируем конкретное значение одной случайной величины, например X = х (рис. 4а), тогда совокупность соответствующих значений другой СВ У можно рассматривать как отдельную случайную величину со своим законом распределения вероятностей и своими числовыми характеристиками, которые называют условными. В качестве оценок условных математических ожиданий таких величин принимают средние
Рассматривая эти средние значения СВ У при всех остальных значениях СВ X, можно получить эмпирическую (выборочную) функцию регрессии У на X вида Аналогично, зафиксировав конкретные значения У = у и определяя по данным выборки или корреляционной таблицы условные средние Задаваясь на основании построенного корреляционного поля видом линейной или нелинейной функции эмпирической регрессии, окончательные параметры уравнения устанавливают обычно методом наименьших квадратов. С этой целью проводится минимизация суммы квадратов отклонений от выбранной линии теоретической функции по вертикали, если ищутся параметры уравнения Полученный график эмпирической функции регрессии на корреляционном поле будет наилучшим приближением ко всем экспериментальным точкам.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 164; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.143.9.115 (0.005 с.) |
 .
.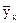 , представляющие средние арифметические наблюдавшихся значений СВ У, соответствующих фиксированным значениями х.
, представляющие средние арифметические наблюдавшихся значений СВ У, соответствующих фиксированным значениями х. , можно получить эмпирическую функцию регрессии X на У вида
, можно получить эмпирическую функцию регрессии X на У вида 


