
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Дайте определение имитации. Назовите характерные особенности имитации. В каких случаях рекомендуется проводить имитационное моделирование?Стр 1 из 11Следующая ⇒
10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. Дайте определение основным понятиям дисциплины «Моделирование систем»: системе, аналитической модели, имитационной модели, регрессионной модели. Назовите характерные особенности информационных систем, позволяющие их представлять в формализованном виде системами массового обслуживания. Система – это совокупность элементов, связанных между собой так, Системы можно исследовать с различных точек зрения. Большой класс систем, в том числе и информационных, формально представляются системами массового обслуживания (СМО) и сетями СМО. Информационные системы имеют все характерные черты СМО. В них присутствуют: 1. Потоки однородных событий. 2. Обслуживающие аппараты (ОА), которые выполняют запросы, поступающие от внешних источников. 3. Ограничения на ресурсы, заключающиеся в том, что не все запросы можно начинать выполнять сразу в момент их поступления в СМО. 4. Очереди на выполнение запросов. Для исследования (моделирования) СМО используют аналитические, имитационные и регрессионные модели. Введем их определения. Аналитическая модель – это совокупность математических зависимостей, построенных на принципах формального подобия процессов, происходящих в объекте моделирования и его модели. Имитационная модель – это совокупность операторов алгоритма (программы), в которую можно подставить значения технических характеристик объекта моделирования, параметров внешней среды, времени, начальных условий, имеющихся ограничений и при выполнении имитационной программы в качестве результатов получать значения результативных показателей эффективности. Регрессионная модель – представляет совокупность математических зависимостей, построенных на основании выявленных статистических зависимостей между переменными методом наименьших квадратов, который требует, чтобы сумма квадратов отклонений экспериментальных значений от вычисленных была минимальной.
Дайте определение имитации. Назовите характерные особенности имитации. В каких случаях рекомендуется проводить имитационное моделирование?
Имитация. Под имитацией будем понимать численный метод проведения экспериментов над математическими моделями сложных систем, подверженных случайным воздействиям. Из определения выделим характерные особенности имитации: 1. Имитация относится к численным методам, а любой численный метод характеризуется наличием методической ошибки, поэтому предпочтительнее использовать аналитические методы моделирования, не имеющие методической ошибки (если это возможно). 2. Имитация – это эксперимент, и, хотя он производится над математической моделью, при его проведении целесообразно применять теорию планирования экспериментов и обработки результатов моделирования. 3. Имитируемые объекты моделирования подвержены случайным воздействиям и поэтому для получения достоверных результатов особое внимание требуется уделить качеству случайных чисел, используемых при моделировании. 4. ЭВМ не является обязательным инструментом имитации, и в принципиальном плане имитацию можно выполнить графическим методом без применения ЭВМ. Однако ввиду того, что для получения достоверных результатов требуется проимитировать сравнительно большое количество состояний, в которых может находиться объект моделирования (ОМ), то применение ЭВМ становится весьма целесообразным.
Какие задачи решаются на этапе анализа моделируемой системы и постановки задач? Какие работы надо выполнить для составления содержательного описания? Какое альтернативное решение приходится принимать при выделении в моделируемой системе подсистем и элементов? 1 ЭТАП МОДЕЛИРОВАНИЯ. АНАЛИЗ МОДЕЛИРУЕМОЙ СИСТЕМЫ И ПОСТАНОВКА ЗАДАЧ На первом этапе решаются следующие задачи. 1. Составляется содержательное описание ОИ. 2. Выбираются результативные показатели эффективности функционирования ОИ и устанавливается перечень влияющих на них факторов. 3. Проводится постановка задач. Дайте определение результативным показателям эффективности системы. Какие характеристики исследуемого объекта выбираются в качестве результативных показателей? Приведите постановки задач по построению математической модели объекта и оптимизации.
Под результативными показателями эффективности понимаются количественные характеристики, которые показывают, насколько эффективно ОИ решает поставленные перед ним задачи. В основном – это экономические показатели: прибыль, объем реализации, затраты на получение прибыли и т.п. Кроме экономических показателей часто используют и технические, такие, как количество решенных задач за единицу времени, среднее время решения задач и его стандартное отклонение, вероятность решения задачи за заданный интервал времени, коэффициент готовности (отношение времени, в течение которого система была в работоспособном состоянии к общему времени моделирования. Общее время моделирования включает в себя и время на профилактику и ремонт). 1. Главная задача – это получение математической модели объекта, которая на данном этапе записывается в функциональном виде: где yj – j -й результативный показатель эффективности (отклик); К – общее количество результативных показателей эффективности; хi – i -й фактор, влияющий на отклики; М – общее количество факторов. Совокупность уравнений регрессии По математической модели производят о ценку степени влияния факторов на результативные показатели эффективности по их удельным весам в изменении откликов и по коэффициентам эластичности, которые показывают, на сколько процентов изменится отклик при изменении конкретного фактора на 1%. Такая оценка может быть проведена, если все факторы влияют на отклики независимо друг от друга. Факторный анализ – раздел многомерного статистического анализа, объединяющий методы оценки размерности множества наблюдаемых переменных посредством исследования структуры корреляционных (ковариационных) матриц. Основное предположение факторного анализа заключается в том, что корреляционные связи между большим числом исходных факторов определяются существованием меньшего числа гипотетических ненаблюдаемых переменных или факторов, названных общими скрытыми, или проще просто общими факторами Ординарность. Заключается в том, что если в ОМ действует несколько экспоненциальных законов, то в любой момент времени в такой системе не может произойти Отсутствие последействия. Заключается в том, что вероятность любого события в будущем не зависит Назовите особенности гиперэкспоненциального и специального эрланговского законов. В каких случаях рекомендуется использовать гиперэкспоненциальный закон распределения случайных чисел, и в каких случаях специальный эрланговский? Экспоненциальный закон является основным законом для создания моделей систем. Недостаток экспоненциального закона – сравнительно небольшая область существования, что ограничивает его использование. Зависимость среднего квадратического отклонения от математического ожидания представляется прямой линией. Этот недостаток особенно существенен для разработки аналитических моделей.
σ
Рис. Область существования экспоненциального закона распределения случайных чисел Реальные экспериментальные распределения могут иметь самые различные значения m1 и σ и для их представления с возможностью создания аналитических моделей применяют так называемые составные экспоненциальные распределения, которые представляют собой параллельные или последовательные совокупности различных экспоненциальных распределений. Для случая, когда Структурная схема гиперэкспоненциального закона распределения, состоящего из n ветвей, представлена на рис.
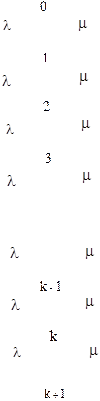
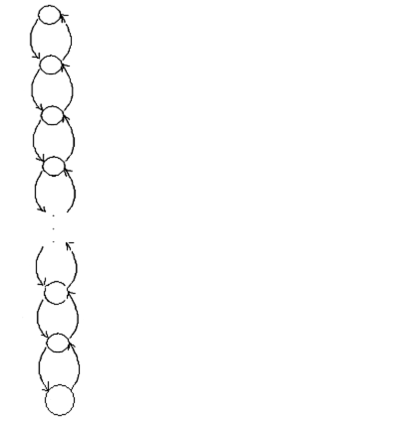
Достоинством представления случайных процессов гиперэкспоненциальными законами является возможность создания аналитических моделей систем, а явный недостаток по сравнению с представлением экспоненциальным законом заключается в сравнительно большом количестве параметров, которое требуется определить, т.е. при количестве ветвей n количество определяемых параметров 2 n. Таким образом, требуется вычислить по МПФ не только 2 n – 1 производных, но и решить систему, состоящую из 2 n уравнений. Первое уравнение записывается из условия, что сумма вероятностей выбора ветвей должна равняться 1. a1 + a2 + … + a n = 1 Для упрощения аппроксимации на практике широко используется частный случай гиперэкспоненциального распределения, состоящего из двух ветвей, Специальное эрланговское распределение (СЭР) состоит из k последовательно соединенных фаз, в каждой из которых распределение случайных величин подчиняется экспоненциальному закону с одинаковой интенсивностью m k. Структурная схема специального эрланговского закона распределения:
Дайте определение блокам и командам в моделирующей системе GPSS W. В каком формате записываются операторы языка GPSS W? Какие три оператора языка являются обязательными и почему для любых программ на языке GPSS W? Для разработки имитационных программ рекомендуется использовать язык GPSS World (General Purpose Simulation System World – Всемирная общая целевая моделирующая система). GPSS World является реализацией GPSS, общецелевой системы моделирования, улучшенной встроенным языком программирования PLUS – языком программирования низкого уровня моделирования. Эта версия GPSS включает в себя 53 типа блоков и 25 команд, а также более чем 35 системных числовых атрибутов, которые обеспечивают чтение текущих переменных, отображающих состояние моделируемой системы, в любой момент времени в любом месте модели. PLUS – это небольшой, но эффективный процедурный язык программирования, включающий в себя 12 типов операторов. Его эффективность во многом обеспечивается большой библиотекой процедур, содержащей математические функции и функции манипуляции со строками, и большим набором вероятностных распределений. Операторы GPSS W имеют единый формат записи, состоящий из следующих полей:
1. Поля метки, в котором указывается либо имя объекта, либо натуральная метка для организации перехода транзакта. 2. Поля операции, в которое записывается либо тип объекта, либо вид выполняемой операции. 3. Поля операндов, в которое записываются параметры объекта. В некоторых операторах записывается вычисляемое математическое выражение. В зависимости от типа оператора, изменяется количество операндов и их назначение. Любая запись после поля операндов, сделанная с пробелом не менее, чем в одну позицию считается комментарием. Кроме того, комментарий можно записать с новой строки после символа Ú. Объекты GPSS делятся на 7 категорий и 14 типов: Категория Тип 1. Динамическая 1. Транзакты 2. Операционная 2. Блоки 3. Аппаратная 3. Устройства 4. Памяти 5. Логические ключи 4. Статистическая 6. Очереди 7. Таблицы 5. Запоминающая 8. Ячейки Х 9. Матрицы МХ 6. Вычислительная 10. Арифметические переменные 11. Логические переменные 12. Функции 7. Группирующая 13. Группы 14. Списки пользователя. Память в GPSS подразделяется на общую и специализированную. Переменным общей памяти можно задавать начальные значения и менять их в процессе моделирования. Значения этих переменных остаются до окончания моделирования и выдаются в стандартном отчете. Это ячейки Х и матрицы ячеек МХ. Специализированная память – параметры транзактов. Любой оператор модели может использовать параметры только активного (движущегося в данный момент) транзакта.
В GPSS World модель определяется как последовательность оперторов. Это операторы GPSS, операторы PLUS-процедур или операторы PLUS-экспериментов.
Что указывается в операндах классификатора систем массового обслуживания (СМО)? Какая количественная характеристика понимается под состоянием СМО? Что такое процессы рождения и гибели в СМО? Какие формулы составляют математическую модель СМО. По какому правилу записываются формулы для вычисления временных характеристик СМО и в чём заключается это правило? Для классификации однофазных моделей систем массового обслуживания (СМО) принята запись, введенная Клейнроком, состоящая
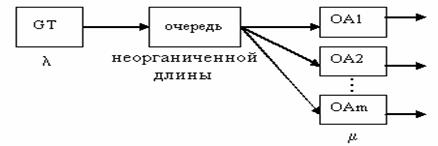
Модель М/М/1 Простейшая система массового обслуживания. Структурная схема системы
параметры: l – интенсивность поступления транзактов; m – интенсивность обслуживания. В данной СМО может существовать стационарный режим, если ρ = λ/μ £ 1, что соответствует режиму, в котором интенсивность обслуживания не меньше интенсивности поступления транзактов в систему. Модель М/М/1/3 В данной СМО ограничено количество транзактов в системе вследствие ограниченного количества мест в очереди k. Важнейшей характеристикой системы является вероятность отказа Р отк = Рk +1 (в СМО находится k + 1=3+1=4 транзакт). Кроме того, вычисляется относительная пропускная способность, которая является вероятностью, что поступающие транзакты будут обслужены q = 1 – P отк. А также абсолютная пропускная способность, которая определяет количество обслуженных транзактов за единицу времени А = l* q. Структурная схема данной СМО
Для систем с отказами стационарный режим реализуется при любых значениях l и m, так как все «мешающие» этому транзакты будут удаляться из СМО без обслуживания. Модель М/М/3 Структурная схема системы массового обслуживания с экспоненциальным входным потоком и обслуживанием и с количеством обслуживающих аппаратов, равным m.

Стационарный режим в данной системе может существовать, если
Какие методы генерации равномерно распределённых случайных чисел Вы знаете? Чем отличаются псевдослучайные числа от случайных? Какие виды тестов используются для оценки качества равномерно распределённых случайных чисел? Для генерации случайных чисел по заданному закону используют аналитические, табличные и специальные методы, основанные на функциональных особенностях генерируемых законов. В качестве задающих генераторов для реализации любых законов применяют генераторы равномерно распределенных случайных чисел. На практике наиболее часто применяют следующие четыре метода генерации случайных чисел: 1. Метод квадратов:
При возведении в квадрат n -разрядного числа в общем случае максимально в произведении будет 2 n разряда. В качестве i -го случайного числа берется 2. Метод произведений:
Берется n средних разрядов произведения двух предыдущих чисел. 3. Конгруэнтный метод:
Символ º обозначает сравнимость по модулю. l и m – целые положительные числа. Для получения очередного случайного числа предыдущее умножается на l и затем делится на m, а остаток от деления берется в качестве i -го случайного числа. 4. Смешанный конгруэнтный метод. Улучшает качество случайных чисел и отличается от предыдущего добавлением к произведению целого положительного числаm
Генераторы псевдослучайных чисел современных ЭВМ, как правило, строятся на основании смешанного конгруэнтного метода. Качество случайных чисел, в том числе длина периода, которая является существенным показателем качества, во многом зависит от выбранных значений l, m, m. Равномерный закон является самым простым для реализации. Как правило, для генерации случайных чисел по всем другим статистическим законам равномерный закон используется в качестве задающего генератора. В вычислительных машинах большее распространение получили программные методы генерации случайных чисел, которые вычисляются по формуле, и поэтому в принципиальном плане не могут являться случайными. Они называются псевдослучайными. Отличие псевдослучайных чисел от случайных заключается в том, что, начиная с некоторого времени, в них наблюдается периодичность, т.е. повторение одних и тех же случайных чисел, и это естественно, так как они вычисляются по формуле. В чисто случайных числах этого быть не может, так как является исключительно маловероятным событием. Это существенный недостаток псевдослучайных чисел, а их достоинством является возможность повторения одних и тех же последовательностей случайных чисел, т.е. если задавать одно и то же исходное число для генератора, то генератор каждый раз будет выдавать одни и те же последовательности чисел, что очень важно при проведении имитационного моделирования. Тест частот Функция распределения равномерно распределенных случайных чисел в диапазоне от 0 до 1 представлена на рис.14.1, а функция плотности на рис.14.2.
Рис. 14.1. Функция распределения Рис. 14.2. Функция плотности равномерного закона равномерного закона Тест разрядов Для равномерного закона вероятность появления любого символа в любом разряде числа одинакова. Для десятичных чисел она равна 0,1; для двоичных – 0,5. Для проведения тестирования подсчитывается количество каждых символов в каждом разряде числа, то есть их частоты. И аналогично предыдущему вычисляется критерий c2 и количество степеней свободы R. А далее проверяем попадание коэффициента доверия гипотезе в 10%-ный доверительный интервал. При отрицательном результате гипотеза отвергается. Тест оценки случайности Два предыдущих случаев дадут отличный результат, если вместо генератора случайных чисел взять обычный счетчик и он будет являться идеально равномерным. Для того чтобы устранить случайность вычисляют коэффициент линейной автокорреляции, показывающий зависимость случайных чисел от ранее сгенерированных. Коэффициент автокорреляции вычисляется для последовательности случайных чисел берущихся с некоторым шагом между собой h. Тест периодичности Тест периодичности заключается в вычислении длины периода и длины отрезка апериодичности. Период – это количество повторяющихся чисел, а отрезок апериодичности – это такая последовательность случайных чисел, в которой нет ни одной пары одинаковых чисел, но следующее число за отрезком апериодичности имеет в нем «свою» пару. Как генерируются случайные числа методом обратной функции? Почему этот метод получил такое название? Чем отличается табличный метод генерации случайных чисел от метода обратной функции? Назовите достоинства и недостатки методов обратной функции и табличного метода. Для генерации случайных чисел по заданному закону используют аналитические, табличные и специальные методы, основанные на функциональных особенностях генерируемых законов. В качестве задающих генераторов для реализации любых законов применяют генераторы равномерно распределенных случайных чисел. Аналитический метод
Применение метода обратной функции основано на теореме, что если случайная величина Х имеет функцию плотности f(x), то случайная величина
Табличный метод Табличный метод основан на том же принципе, что и аналитический, только вместо функции распределения в нем берется ее кусочно-линейное представление, т.е. весь диапазон существования распределения случайных чисел разбивается на ряд интервалов, в которых дуги заменяются стягивающими их хордами. Применение метода представлено на рис. 3.9.
Интервал, в который попало случайное число, определяется по выполнению неравенства ai-1 £rj £ai. На основании подобия треугольников:
Оценка адекватности модели Оценка адекватности результатов имитационного моделирования естественно может быть проведена только в случаях, когда имеются либо результаты аналитического моделирования, либо результаты, полученные на натурном объекте. Наиболее часто проводят сравнение средних значений методом построения доверительных интервалов. Так как средние значения при имитационном моделировании находятся сложением достаточно большого количества случайных чисел, то для их представления можно использовать нормальный
Оценка устойчивости модели Для оценки устойчивости результатов имитационного моделирования 1. Задаемся доверительной вероятностью 2. Задаемся количеством проводимых экспериментов – k. Рекомендуемое значение k = 15, 3. Задаемся количеством реализаций в каждом эксперименте n. Рекомендуемое значение n = 100. 4. Проводим k экспериментов, в каждом из которых проводится по n реализаций. По результатам моделирования находятся оценки математического ожидания 5. Подсчитываем количество случаев выполнения условия сравнения 6. Если количество случаев выполнения условия (4.2) не меньше План полного факторного эксперимента
Вершины квадрата – план полного факторного эксперимента (ПФЭ). Обычно к этим точкам добавляется центральная точка, и пять проводимых экспериментов позволяют вычислить четыре коэффициента двухфакторной математической зависимости: y = b 0 x 0 + b 1 x 1 + b 2 x 2 + b 12 x 1 x 2. План полного факторного эксперимента (ПФЭ) позволяет вычислить все коэффициенты степенного полинома, включая коэффициенты как при самих факторах, так и при всех сочетаниях факторов между собой в виде их произведений Цель планирования экспериментов – получение результатов с требуемой достоверностью при наименьших затратах. Планирование подразделяется 1. Стратегическое планирование - определяет количество проводимых экспериментов, порядок их выполнения и значения изменяемых факторов в каждом эксперименте. Для стратегического планирования будем использовать концепцию «черного ящика». 2. Тактическое планирование - определяет количество реализаций состояния моделируемой системы в проводимых экспериментах для получения результатов моделирования с заданной достоверностью. Концепция «черного ящика», суть которого – абстрагирование от физической сущности процессов, происходящих в моделируемой системе и выдаче заключений о ее функционировании только на основании значений входных и выходных переменных. Входные, независимые переменные называются факторами. Выходные – откликами, их величина зависит от значений факторов и параметров ОИ. Структурная схема «черного ящика» представлена на рис. 5.1.
Рис. 5.1. Структурная схема концепции черного ящика
При использовании концепции черного ящика должны выполняться следующие условия. 1. Рандомизация – случайность. Только при наличии случайности возможно корректное использование математического аппарата теории вероятностей и статистики. 2. Одновременное изменение всех факторов. Обеспечивает уменьшение стандартной ошибки при проведении экспериментов. 3. Последовательность планирования. Проведение экспериментов подразделяется на ряд последовательных этапов, и планирование каждого последующего этапа проводится с учетом результатов, полученных на предыдущих этапах. 4. Кодирование. Необязательно. Кодирование значительно упрощает расчеты и делает анализ результатов более наглядным, что весьма существенно при «ручной» обработке результатов. При применении ЭВМ кодирование также предоставляет некоторые преимущества в анализе результатов. К факторам предъявляют следующие требования. 1. Факторы должны иметь легкую управляемость, что позволяет повторять проводимые эксперименты. 2. Факторы не должны являться функциями каких-то аргументов. 3. Факторы должны быть хотя бы линейно независимыми между собой, что позволяет упростить математическую модель, не вводя в нее произведения факторов между собой. 4. Любое сочетание факторов в стратегических планах не должно выводить объект из допустимого режима функционирования.
50. Назовите три замечательных свойства плана полного факторного эксперимента (ПФЭ); его достоинства и недостатки. При каком условии можно применять план дробного факторного эксперимента (ДФЭ)? В чём его суть? Три замечательных свойства плана ПФЭ: 1. Симметричность. Каждая точка плана имеет симметричные точки относительно осей координат. В математическом плане симметричность сводится 2. Нормированность, которая в математическом плане сводится к тому, что построчная сумма квадратов элементов всех столбцов плана, кроме левого, равна 3. Ортогональность, которая заключается в независимости всех факторов друг от друга. Достоинства: План полного факторного эксперимента (ПФЭ) позволяет вычислить все коэффициенты степенного полинома, включая коэффициенты как при самих факторах, так и при всех сочетаниях факторов между собой в виде их произведений. Кроме того, следует отметить сравнительную простоту составления плана ПФЭ, который представляет собой полный перебор совокупностей всех факторов по двум уровням. Таким образом, количество точек плана ПФЭ N = План ПФЭ имеет существенный недостаток, проявляющийся при сравнительно большом количестве факторов, так при m = 3, N = 8; при m = 7, N = 128, а при m = 10, N = 1024, что является неприемлемым. План дробного факторного эксперимента В некоторых случаях, если факторы независимы друг от друга, можно значительно уменьшить количество проводимых экспериметов, применяя план дробных факторных экспериментов (ДФЭ). В ДФЭ факторы разделяются на основные и дополнительные. Для основных факторов составляется план ПФЭ, а дополнительные меняются по законам изменения произведений основных факторов. Таким образом, если в эксперименте используется семь факторов, то по плану ПФЭ понадобилось бы провести 128 экспериментов. Если же они независимы друг от друга, то, выделив из них три основных фактора и составив для них план ПФЭ, можно ограничиться всего 9 экспериментами с учетом центральной точки. Планы ДФЭ сохраняют все названные достоинства планов ПФЭ.
51. Назовите особенности ортогонального центрального композиционного плана (ОЦКП) и ротатабельного центрального композиционного плана (РЦКП). Для вычисления коэффициентов математической зависимости (5.3) можно использовать ортогональный центральный композиционный план (ОЦКП) и ОЦКП ОЦКП сохраняет свойство симметричности плана из-за того, что на каждый фактор вводят по две симметричные звездные точки. Количество проводимых экспериментов: Вычисляется вспомогательный коэффициент: РЦКП РЦКП обеспечивают несущественную величину ошибки в точках, равноотстоящих от центров проведения экспериментов, поэтому они широко применяются Композиционные планы ОЦКП и РЦКП имеют существенный недостаток, который начинает сказываться с увеличением количества факторов в проводимых экспериментах: чем больше факторов, тем больше расстояние звездных точек от центра осей координат, которое все больше и больше удаляется от заданных границ диапазонов изменения факторов, что является нежелательным. 52. Назовите особенности построения D-оптимальных планов. Чем планы Коно отличаются от планов Кифера? В D -оптимальных планах значения факторов не выходят за установленные границы диапазонов их изменения. Кроме того, они обладают еще одним существенным достоинством, обеспечивая минимальную ошибку во всем принятом диапазоне изменения факторов. На практике наиболее часто применяются планы Коно и планы Кифера Характерной особенностью D- оптимальных планов является разница в количестве проводимых экспериментов для точек плана различного вида. Планы Коно Для многофакторных экспериментов в геометрической интерпретации диапазон изменения факторов представляется многомерным кубом, который далее будем называть просто куб. Для двух факторов этот куб вырождается в квадрат. Эксперименты по плану Коно проводятся в вершинах куба, серединах ребер и центре куба. Расположение точек стратегического плана Коно на квадрате и кубе.
Количество точек для двухфакторного эксперимента (m = 2) и трехфакторного эксперимента (m = 3)
Планы Кифера
|
||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 320; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.23.123 (0.147 с.) |
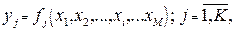

 σ=m1
σ=m1 m1
m1 используют гиперэкспоненциальные распределения. Для случая когда
используют гиперэкспоненциальные распределения. Для случая когда  используют эрланговские распределения.
используют эрланговские распределения.




 .
.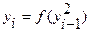 . (3.1)
. (3.1)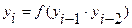 . (3.2)
. (3.2)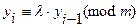 . (3.3)
. (3.3)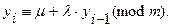 (3.4)
(3.4)
 Аналитические методы, как правило, используют метод обратной функции, названный так ввиду того, что аргумент при его применении откладывают
Аналитические методы, как правило, используют метод обратной функции, названный так ввиду того, что аргумент при его применении откладывают 
 распределена равномерно в диапазоне от 0 до 1 и для вычисления j-го случайного числа используется формула:
распределена равномерно в диапазоне от 0 до 1 и для вычисления j-го случайного числа используется формула: ,
, 
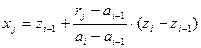 .
.  , а
, а  . Поэтому для оценок математических ожиданий, вычисляемых на основе суммирования случайных чисел, можно построить доверительный интервал на основании нормального закона
. Поэтому для оценок математических ожиданий, вычисляемых на основе суммирования случайных чисел, можно построить доверительный интервал на основании нормального закона
 . Рекомендуемое значение
. Рекомендуемое значение  ,
, 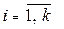 и стандартного отклонения
и стандартного отклонения  ;
; 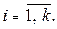
 ,
,  В графическом виде план по проведению эксперимента представляет собой вершины квадрата,
В графическом виде план по проведению эксперимента представляет собой вершины квадрата,















 , где m – количество факторов.
, где m – количество факторов. , для m = 2 N = 9. ОЦКП сравнительно несложно построить. ОЦКП в значительной мере упрощает вычисления, что особенно существенно для «ручных» вычислений. Свойство нормированности в ОЦКП сохранить не удается, но это и не так важно. Для обеспечения ортогональности столбцов матрицы планирования вводят некоторые сравнительно несложные преобразования. Расстояние звездной точки от середины осей координат вычисляется
, для m = 2 N = 9. ОЦКП сравнительно несложно построить. ОЦКП в значительной мере упрощает вычисления, что особенно существенно для «ручных» вычислений. Свойство нормированности в ОЦКП сохранить не удается, но это и не так важно. Для обеспечения ортогональности столбцов матрицы планирования вводят некоторые сравнительно несложные преобразования. Расстояние звездной точки от середины осей координат вычисляется
 = 4
= 4
 = 4
= 4
 = 1
= 1



