
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Загальні уявлення про критерії перевірки вибірки на нормальний розподіл даних
Для визначення закону розподілу певної величини, перш за все, потрібно віднести її або до дискретної, або неперервної. Більшість величин, які вимірюються у експериментальній біології, вважаються неперервними. Дослідники на практиці найчастіше зустрічаються з малою вибіркою (4≤n≤30) і міркувати про нормальність розподілу даних є досить важко. За міжнародним стандартом ISO 5479-97 ( The I nternational O rganization for S tandardization) вважається, що при кількості вимірювань n <10 перевірити гіпотезу про вид розподілу результатів вимірювань неможливо. При числі даних 10< n <30 також важко судити про вид розподілу, тому для перевірки відповідності даних нормальному розподілу використовують певний статистичний критерій (складовий критерій d, критерій Шапіро-Уілка, критерій Колмогорова, критерій Пірсона χ2 та інші). За міжнародним стандартом ISO 5479-97 для перевірки даних на нормальний розподіл слід використовувати складовий критерій d, W -критерій Шапіро-Уілка, критерії перевірки на симетричність і на значення ексцесу (див. пункт 5.4), критерій Еппса-Паллі. Цей стандарт не рекомендує критерію χ2 і подібних до нього, оскільки вони підходять тільки для згрупованих даних. Проте критерій χ2 може бути використаний для великих вибірок (n>100). Перш, ніж перевіряти нормальність розподілу даних за наведеними вище критеріями можна також перевірити чи виконується наступна умова:
Якщо між ними різниця 10-20%, то розподіл даних є відмінним від нормального. Проте якщо медіана і середнє арифметичне значення подібні – це все одно ще не свідчитиме про нормальний розподіл даних. 5.2. Складовий критерій d При перевірці даних на нормальний розподіл часто застосовують складовий критерій d. При цьому задаються рівні значущості qI α I (для критерію I) і qII α II (для критерію II). Рівні значущості складового критерію повинні задовільняти умову: q ≤ qI + qII (α ≤α I +α II) (30). Значення критерію I обчислюють за формулою:
де s * – зміщене середнє квадратичне відхилення:
Гіпотеза про нормальність підтверджується, якщо
де Таблиця 7. Значення процентних точок q для розподілу d
Використовуючи критерій II,гіпотезу про нормальність розподілу результатів вимірювань можна підтвердити, якщо не більше m різниць . Таблиця 8. Квантилі
Значення статистичної значущості p отримують із таблиці 9. Таблиця 9. Значення статистичної значущості p
Гіпотезу про нормальний розподіл даних приймають тільки в тому випадку, якщо для вибірки виконуються два вказані вище критерії. 5.3. Статистичний критерій W (критерій Шапіро-Уілка) Цей критерій є одним з найбільш чутливих щодо перевірки даних на їхній нормальний розподіл. Його застосовують при 10≤n<30. Перевірку гіпотези про те, що дані мають нормальний розподіл здійснюють в наступній послідовності: 1) результати досліджень розміщують у вигляді послідовності:
де n – число досліджень; 2) обчислюють значення величини SS (сума квадратів – S um of S quares):
3) обчислюють значення величини b за формулою:
де значення коефіцієнтів Таблиця 10. Значення коефіцієнтів
Якщо n – парне, то 4) знаходять значення W-критерію за формулою:
5) при певному рівні статистичної значущості (зазвичай p<0,05) перевіряють виконання умови:
де Wкр – критичне значення критерію, що взяте із таблиці 11. Таблиця 11. Критичні значення W -критерію
Якщо така умова (37) виконується, то говорять про нормальний розподіл даних.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-19; просмотров: 425; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.224.73.125 (0.009 с.) |
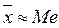
 (31)
(31) (32)
(32) (33)
(33) процентні точки розподілу значень d, які можна знайти по таблиці 7.
процентні точки розподілу значень d, які можна знайти по таблиці 7. перевищили значення
перевищили значення  , де
, де  – верхня квантиль нормованої функції Лапласа (таблиця 8), що відповідає вірогідності р/2, а S – середнє квадратичне відхилення, яке обчислюється за формулою (9).
– верхня квантиль нормованої функції Лапласа (таблиця 8), що відповідає вірогідності р/2, а S – середнє квадратичне відхилення, яке обчислюється за формулою (9).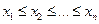 ,
, (34)
(34) (35),
(35), для
для  можна взяти із таблиці 10.
можна взяти із таблиці 10. , а якщо n – непарне, то
, а якщо n – непарне, то  (в цьому випадку
(в цьому випадку  не використовується для обчислень).
не використовується для обчислень). (36);
(36);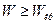 (37),
(37),


