
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Неузгодженості у записах при використанні стандартної похибки середнього
Дуже часто в статтях і дисертаціях зустрічається запис «M ± m», який, як припускається, пояснює тип представлення даних. Автори під M розуміють середню арифметичну величину, а під m – стандартну похибку середнього. Втім, якщо немає деталізації, то лишається не зрозумілим, що саме дослідник вкладає у символи M та m. Для того, щоб запис не залишав сумнівів, ми рекомендуємо в публікаціях давати повне пояснення на кшталт «Всі значення представлені у вигляді середньої ± стандартне відхилення» (у англомовній літературі M ean ± S tandart D eviation (M ± S.D.)) чи «Вибіркові характеристики представлені у вигляді середньої ± помилка середньої». (у англомовній літетарурі M ean ± S tandart E rror of M ean (M ± S.E.M. або M ± S.E.)). РОЗДІЛ 4. АНАЛІЗ ДАНИХ, ЯКІ ВИПАДАЮТЬ В ХОДІ ДОСЛІДЖЕНЬ (ПРОМАХИ І СИСТЕМАТИЧНІ ПОХИБКИ)
Значення, які потрапляють у вибірку, можуть дуже істотно відрізнятись за величиною (неоднорідні дані). Візьмемо наш приклад зі зростом 992 осіб. Вибірка може виглядати по-різному: може включати осіб зі зростом 145, 147, 154 та 199 см, або 145, 165, 181 та 193 см. Звичайно, що у першій вибірці значення 199 см виглядає сумнівним, але зрозуміло, що помилку у вимірюванні зросту важко допустити. В таких випадках кажуть, що вибірка не є репрезентативною, тобто якимось чином у неї потрапили тільки люди низького росту. Коли дослідник отримує неоднорідні дані, то завжди перед ним стоїть питання: які ж дані слід брати до уваги – одні чи інші? В такому випадку часто самовільно викидаються ті дані, які дослідник вважає невдалими – занадто великими, чи занадто малими, тобто малоправдоподібними. Але такий підхід є неправильним і часто приводить до хибності отриманих результатів. Щоб таких помилок не було треба скористатись статистичними критеріями. Розглянемо деякі із них. Критерій Шовене Цей критерій для виключення промахів є досить простим. Для його обчислення, крім значень
або
Після цього обчислення отриманий коефіцієнт співставляють з критичним значенням uкр для n значень. Якщо u≥uкр, то це значення виключають із подальших обрахунків. Величини uкр наведенів таблиці 2.
Таблиця 2. Величини коефіцієнта uкр
Якщо у варіаційному ряді є декілька величин, що різко відрізняються від інших, то можна застосовувати інший підхід. За наведеною вище таблицею залежно від числа варіант визначають uкр і обчислюють Приклад 13. Використавши критерій Шовене, перевіримо наступні дані: 14,8; 14,2; 14,8; 33,6; 14,1 на наявність промахів.
Оскільки кількість варіант дорівнює 5, то, використовуючи таблицю 2, отримаємо uкр = 1,68. Далі обчислюємо:
Оскільки 33,6>32,7, то значення варіанти 33,6 є промахом його виключається з наступних обчислень. Тобто, заново обчислюють Q-критерій Діксона При його використанні отримані результати вимірювань записують у варіаційний ряд за збільшенням:
Даний критерій визначається як:
або Проте розрахунок за цими формулами буде коректним тільки для n =3-7. При n = 8-10 в знаменнику повинна стояти різниця між вірогідним промахом і значенням, найближчим до максимального (або мінімального) значення:
Значення Q порівнюють з критичним значенням критерію, наведеним у таблиці 3. Якщо критичне значення менше дослідного, то вірогідний промах є істинним. При цьому як рівень статистичної значущості p беруть 0,10, а не 0,05. Зазвичай на промахи перевіряють мінімальне і максимальне значення. Після відкидання промахів знову повторюють обчислення.
Таблиця 3. Критичні значення Qкр при різних рівнях статистичної значущості p і числі вимірювань n
Приклад 14. Використавши критерій Діксона, перевіримо на наявність промахів наступні дані: 14,8; 14,2; 14,8; 33,6; 14,1.
1) із поданих даних формуємо варіаційний ряд: 14,1; 14,2; 14,8; 14,8; 33,6 2) за формулою (23) обчислюємо Q:
Порівнюючи Q, яке ми отримали в результаті обчислень (0,964), з критичним значенням Qкр (0,642) при n=5 і рівні статистичної значущості p<0,10 (таблиця 3), значення 33,6 є промахом. Критерій Романовського Його застосовують, якщо n≤20. Для цього обчислюють β за формулами:
Причому середнє арифметичне значення ( Таблиця 4. Критичні значення критерію βкр
Якщо β≥ βкр, то таке значення вважають промахом і відкидають. Приклад 15. Використавши критерій Романовського, перевіримо наступні дані: 14,8; 14,2; 14,8; 33,6; 14,1 на наявність промахів. Величини Використовуючи таблицю 4 для n=4 і p<0,05 отримуємо βкр = 1,71. Далі обчислюємо β за формулою (25): β=(33,6-14,5):0,4=47,7 Отже, β≥ βкр, тому значення 33,6 є промахом. Якщо значення, яке ставилось під сумнів, не виявилось промахом, то заново обраховують величини Критерій Ірвіна Для отриманих експериментальних даних визначають величину критерію λ за формулою:
де хn+1 – вірогідний промах; xn – попереднє значення у варіаційному ряді; s – середнє квадратичне відхилення, яке обчислене за всіма значеннями у варіаційному ряді. При цьому припускається, що об’єм вибірки має бути не менший, ніж n+1 або дорівнює n+1. Потім цей коефіцієнт порівнюють із табличним значенням λкр (таблиця 5). Таблиця 5. Критерій Ірвіна λкр
Якщо λ>λкр, то дана величина, що аналізується, є промахом. Даний критерій можна використовувати при Приклад 16. Використавши критерій Ірвіна, перевіримо наступні дані: 14,8; 14,2; 14,8; 33,6; 14,1 на наявність промахів. 1) із поданих даних формуємо варіаційний ряд: 14,1; 14,2; 14,8; 14,8; 33,6 2) за формулою (26) обчислюємо
3) для n=5 і p<0,05 із таблиці 6 отримаємо Отже, значення 33,6 є промахом, оскільки 2,19>1,87.
Для виявлення промахів у вибірці ми рекомендуємо використовувати хоча б два із вказаних вище критеріїв. Такі славнозвісні критерії,як правило трьох сигм (за цим правилом промахом буде вважатись таке значення, яке не входить в інтервал значень
Критерій Аббе Після виключення отриманих даних промахів за допомогою вказаних вище методів, можна перевірити дані на наявність систематичних помилок, що також часто зустрічається при отриманні результатів дослідження. Для цього можна використати критерій Аббе. Суть даного методу полягає в оцінці дисперсії результатів вимірювань звичайним шляхом за формулою:
і обчисленням суми квадратів послідовних різниць:
Критерій Аббе буде обраховуватись як:
Якщо значення, яке ми отримали, є меншим за критичне vкр, то в результатах вимірювань виявляється систематична похибка. Критичні значення критерію Аббе наведені в таблиці 6.
Таблиця 6. Критичне значення критерію Аббе v кр
Приклад 17. Використавши вищерозглянутий критерій, перевіримо наступні дані: 14,8; 14,2; 14,8; 33,6; 14,1 на наявність систематичних похибок. Після виключення із даних значення 33,6 за допомогою наведних вище критеріїв перевіряємо їх на наявність систематичних похибок: 1) із поданих даних формуємо варіаційний ряд: 14,1; 14,2; 14,8; 14,8 2) використовуючи формулу (27), отримаємо:
3) за допомогою формули (28) знаходимо
4) використовуючи формулу (29), отримаємо
5) за допомогою таблиці 6 для n=4 і рівні статистичної значущості p<0,05 отримаємо значення vкр=0,390. Отже, наші дані не містять систематичних помилок, оскільки 0,434>0,390. Систематичні помилки репрезентативності виникають при порушенні принципу випадковості відбору (упереджений вибір елементів, недосконалий вибір одиниці відбору тощо). Систематичні помилки мають односторонній, тенденційний напрям і призводять до зсунення (викривлення) результатів обстеження в той чи інший бік. Їх ще визначають як помилки зміщення (зсунення).
Так, якщо для визначення середньої успішності потоку студентів взяти вибірку студентів, які сидять на останніх партах, то середня успішність вибірки може бути меншою за середню спішність всього потоку. Якщо вибірку сформувати зі студентів, які сидять в перших рядах, то середня успішність у такій вибірці може бути вищою від середньої успішності потоку. При такому нерівномірному відборі статистична оцінка успішності потоку буде заздалегідь занижена або завищена.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-19; просмотров: 223; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.191.214 (0.042 с.) |
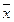 і s, потрібно знайти величину коефіцієнта u (різниця між найбільшою (або найменшою) варіантою і середнім арифметичним, поділена на стандартне відхилення):
і s, потрібно знайти величину коефіцієнта u (різниця між найбільшою (або найменшою) варіантою і середнім арифметичним, поділена на стандартне відхилення):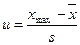 (18)
(18)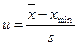 (19)
(19) та
та  . Якщо значення, яке вважають ймовірним промахом, не входить в інтервал цих обчислень, воно дійсно є промахом і відкидається.
. Якщо значення, яке вважають ймовірним промахом, не входить в інтервал цих обчислень, воно дійсно є промахом і відкидається. = 18,3+8,6×1,68=32,7
= 18,3+8,6×1,68=32,7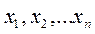 (x1<x2<…<xn)
(x1<x2<…<xn) ( для мінімального значення ) (20)
( для мінімального значення ) (20) (для максимального значення) (21).
(для максимального значення) (21). (для мінімального значення) (22);
(для мінімального значення) (22);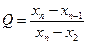 (для максимального значення) (23).
(для максимального значення) (23).
 при xi <
при xi <  (24)
(24) при xi >
при xi >  ) у формулах (24) і (25) обчислюють без врахування ймовірного промаху. Обчислене значення β порівнюють з критичним βкр при рівні статистичної значущості p <0,05 (таблиця 4).
) у формулах (24) і (25) обчислюють без врахування ймовірного промаху. Обчислене значення β порівнюють з критичним βкр при рівні статистичної значущості p <0,05 (таблиця 4). (26),
(26),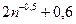
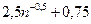
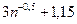
 і при невідомому виді розподілу даних.
і при невідомому виді розподілу даних. для значення 33,6:
для значення 33,6:
 .
. ), критерії Шарльє, Смірнова не можуть бути використані для перевірки варіаційного ряду на наявність промахів, якщо n <30. Критерій Башинського є менш чутливим до наявності промахів, ніж наведені вище методи, хоча і передбачається його використання при 5<n<69.
), критерії Шарльє, Смірнова не можуть бути використані для перевірки варіаційного ряду на наявність промахів, якщо n <30. Критерій Башинського є менш чутливим до наявності промахів, ніж наведені вище методи, хоча і передбачається його використання при 5<n<69. (27)
(27) (28).
(28). (29).
(29).
 :
:
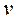 :
: ;
;


