
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Недетерминированный конечный автомат: формальное определение, построение множества достижимых состояний.Стр 1 из 3Следующая ⇒
Недетерминированный конечный автомат: формальное определение, построение множества достижимых состояний. Если язык задан регулярными выражениями, то для него можно построить конечный автомат. КА представляется диаграммой переходов. Узлы - состояния, дуги – переходы, финальное состояние - двойной кружок. Цепочка принимается автоматом, если существует путь из начального состояния в конечное, метки дуг которого, формируют эту цепочку. Автомат называется недетерминированным, если у него есть переходы из одного и того же состояния, помеченные одним и тем же символом, и в нем присутствуют e - переходы. Формально КА определяется пятеркой <S, S, d, s0, F>, S – конечное множество состояний; S –конечное множество входных символов (алфавит); d – отношение переходов, это подмножество S на Σ, к которому добавлена пустая строка; d Í s ×(S È {e})×s s0 – начальное состояние; s0 Î S F Î S – множество финальных состояний. Для каждой пары (начальное состояние и входной символ) можно определить множество конечных состояний. Считая d функцией, через d (s,а) будем обозначать множество состояний, в которые конечный автомат может перейти из состояния s по входному сигналу а. Пользуясь функцией d, можно описать поведение конечного автомата. Функция переходов - D определяет для заданного состояния s и входной последовательности w множество состояний, в которых может оказаться автомат, обработав входную строку w. Определяется: 1) s’Î D(S,e) если s’Í d (s, e) 2) s’Î D(S,e) если есть путь по e переходам, т.е. если есть состояние s’’Î d (S,e) и одновременно s’Î d (s’’,e) 3) когда строка не пустая: s’Î D(S,aw), если есть состояние s’’Î d (s, а) и s’Î D(s’’,w). Язык распознается конечным автоматом, если он является множеством последовательностей: Например, автомат A = <S, Σ, δ, so, F> распознаёт последовательности (язык): L(A) { w | Δ(s0,w) ∩ F ≠ ∅ }, е сли автомат детерминированный: L(A) { w | Δ(s0,w) ∈ ∅ }. 4. Преобразование недетерминированного конечного автомата в детерминированный. Работа конечного автомата заключается в нахождении пути от начального состояния в конечное, по которому можно прочитать лексему. Лексема принимается, если такой путь найден. Недетерминированный конечный автомат включает e-переходы и переходы из одного состояния по одному и тому же входному символу в разные состояния. Поэтому при работе недетерминированного автомата возможны откаты в процессе поиска пути, вследствие этого недетерминированный автомат работает медленно. Для каждого недетерминированного конечного автомата можно построить детерминированный конечный автомат.
Рассмотрим алгоритм преобразования. Входом алгоритма является недетерминированный автомат N, выходом – детерминированный автомат D состоящий из множества состояний Dstates и множества переходов Dtrans. Введем обозначения. S - состояние из N; T - множество состояний из N. При работе алгоритма такие множества становятся состояниями D. Пусть реализованы следующие функции. eclosure(S). Эта функция строит e-замыкание состояния S, то есть множество состояний в которые можно перейти из S по e-переходам, это множество включает также само состояние S; eclosure(T). Функция строит e-замыкание множества состояний T, то есть множество состояний, достижимых из множества состояний T через e-переходы. Это множество включает и состояния, принадлежащие T. Move(T, a). Функция строит множество состояний, в которые можно перейти из Т по входному символу а. Алгоритм состоит в следующем. Dstates:=eclose(S0); заносим в множество Dstates состояние Т = e - closure (s0) и оставляем это состояние не помеченным. Пока в Dstates хотя бы одно множество Т непомеченно выполнить begin пометить множество Т Для каждого входного символа а принадлежащего S - алфавиту автомата выполнить Begin: вычислим множество U:=eclosure(Move(T, a)); Если U Ï Dstates то Dstates:=Dstates+U заносим U в Dstates непомеченным Dtrans[T, a]:=U; end; end; Этот алгоритм позволяет построить ДКА.
Контекстно-свободные языки. Вывод. Дерево вывода. КСЯ можно разбирать на части. Паскаль имеет вложенную структуру. If E then S1 (оператор) else S2 (оператор). Здесь можно выделить синтаксические категории (S1) – нетерминалы и ключевые слова – терминалы (имеют законченный вид). Для описания синтаксиса ЯП используется БНФ. В ней даются определения нетерминалов через терминалы и нетерминалы. Для оператора if:
<оператор>::= if <выражение> then <оператор> else <оператор>. Далее каждый оператор также можно раскрыть. Для каждой грамматики можно определить правило непосредственного вывода: если определены последовательности символов a и b такие, что aÎ V* и bÎ V* (конечное множество грамматических символов), и если задана продукция А→gÎР, то из последовательности символов aАb можно получить agb. Здесь → означает применение правила подстановки или непосредственного вывода. Допустим, если есть последовательность аАВС, то используя грамматику, применив правило 5 только к В, получим: аАВС→аАвВС ↑ Выводом называется последовательность постановок, она обозначается a→*b. Эта запись означает, что из a выводится b за 0 или более шагов.a →+b: из a выводится b за 1 или более шагов. Каждая цепочка символов, встречающихся в выводе, называется промежуточной цепочкой. Если промежуточная цепочка выводима из начального символа, то она называется выводимой цепочкой (сентенциальной формой). Вывод цепочки можно представить в виде дерева. Построение дерева начинаем с корня, и применяя продукции строим ветви.(каждой части правила будет соответствовать ветвь) Вывод цепочки можно представить в виде дерева. Если на каждом шаге заменяется самый левый нетерминал, то вывод называется левосторонним, если самый правый, то правосторонний. В общем случае грамматика может порождать несколько различных деревьев вывода для одной и тоже цепочки (неоднозначная). Однозначная - если каждой выводимой цепочке соответствует единственное дерево вывода. Метод грамматического разбора сверху - вниз. LL(1) – грамматики. Суть: начинаем разбор со стартового нетерминала и, применяя продукции, заменяем нетерминал ее левой части на последовательность символов ее правой части. Цель: получить в обрамлении листьев этого дерева исходную последовательность. Процедура рекурсивного разбора сверху вниз состоит из следующих шагов: - Для узла дерева, помеченного, как нетерминал А, выбирают одну из продукций вида Aàa. После этого строим от А ветви, соответствующие a. - Если в процессе применения продукций получено обрамление, несоответствующее входной последовательности, то производится откат. - Находим следующий узел, помеченный нетерминалом, для подстановки правила. Очень важно уметь правильно выбрать продукцию. Для этого существует разновидность грамматик, называемых LL(k)-грамматики, которые позволяют сделать выбор продукции на основе первых k символов входной последовательности. Самый распространенный вид - LL(1)-грамматики, когда выбрать продукцию можно только на основе 1-го символа. L – входная последовательность обрабатывается слева направо, L – используется левый вывод (заменяется самый левый нетерминал), 1 – количество знаков из входной последовательности, необходимых для выбора продукции. Как сделать выбор среди двух продукций: A → α | β? Находим м-во FIRST для каждой продукции. Если из последовательности α ⇒* x γ (x принадлежит FIRST(α)) и FIRST(α) ⋂ FIRST(β) = ∅ то выбор продукции можно сделать по одному символу продукции. Если ε принадлежит FIRST(α) ≡ α ⇒ ε Для такого случая выбор продукций будет определятся исходя из того какие терминалы могут встречаться непосредственно за А в какой либо сентенциальной форме.
Грамматика относится к классу LL(1) если FIRST(α) ⋂ FIRST(β) = ∅, а если α ⇒* ε то должно выполняться FIRST(β) ⋂ FOLLOW(A) = ∅. Левая факторизация. LL(1)-грамматики нужны для того, чтобы выбрать нужную продукцию для разбора сверху-вниз, чтобы не произошло зацикливание. Иногда существует возможность преобразовать грамматику к LL(1) виду, используя метод левой факторизации. Например: S→ if B then S │if B then S else S Эти продукции нарушают условие LL(1)-грамматик. Эту грамматику можно преобразовать к виду LL(1). S → if B then S Tail Tail → else S | ε В общем виде это преобразование можно определить так: A → α β1 | α β2 … | α βN | γ вводим новый нетерминал В, для которого A → α B | γ B → β1 | β2 … | βN Для B можно применить левую факторизацию. Эта процедура повторяется, пока остается неопределенным выбор продукции (т.е. пока в ней можно что-нибудь изменить). Построение множества FOLLOW Множество Follow для нетерминала определяет множество терминалов, которые могут следовать непосредственно за данным нетерминалом. Алгоритм построения множества Follow выглядит следующим образом: 1. Пусть goal – стартовый нетерминал. Тогда follow(goal) = {EOF}, где EOF – символ конца входной последовательности. Вначале символ конца входной последовательности помещается в множество follow стартового нетерминала 2. Если есть правило A -> aBb, то follow(B) = follow(B) + first(b) - {ɛ}. То есть, если есть правило, утверждающее, что за В следует b, то за нетеримналом будут следовать терминалы, с которых начинается последовательность b. 3. Если есть правило A -> aB, то в множество follow(B) = follow(B) + follow(A). То есть, если есть правило, утверждающее, что нетерминалом В заканчивается последовательность А, то за нетрминалом В будут следовать те же терминалы, что и за всей последовательностью А. 4. Если есть продукция A -> aBb и {ɛ} принадлежит first(B), то follow(B) = follow(B) + follow(A). 5. Если на шагах 2-4 множество follow было изменено, перейти к п.2 Построение множества FIRST Множество First для нетерминала определяет множество терминалов, с которых может начинаться данный нетерминал. 1. Если х - терминал, то first(x)={x}. Так как первым символом последовательности из одного терминала может являться только сам терминал. 2. Если в грамматике присутствует правило Хà e, то множество first(х) включает e. Это означает, что Х может начинаться с пустой последовательности, то есть отсутствовать вообще.
3. Для всех продукций вида XàY1 Y2 … Yk выполняем следующее. Добавляем в множество first(Х) множество first(Yi) до тех пор, пока first(Yi-1) содержит e, а first(Yi) не содержит e. При этом i изменяется от 0 до k. Это необходимо, так как если Yi-1 может отсутствовать, то необходимо выяснить, с чего будет начинаться вся последовательность в этом случае. Исключение левой рекурсии. При процедуре рекурсивного разбора сверху вниз может возникнуть проблема бесконечного цикла. В грамматике для арифметических операций применение второго правила приведет к зацикливанию процедуры разбора. Подобные грамматики называются леворекурсивными. Грамматика называется леворекурсивной, если в ней существует нетерминал А, для которого существует вывод А=>+Аa. В простых случаях левая рекурсия вызвана правилами вида AàAa|b В этом случае вводят новый нетерминал и исходные правила заменяют следующими. AàbB BàaB|e (если есть нетерминал А, для которого существует вывод А→+Аa за 1 или более шагов). Левой рекурсии можно избежать, преобразовав грамматику. Например, продукции A→Aa │β Можно заменить на эквивалентные: A→ β В В→ a В │ ε Для такого случая существует алгоритм, исключающий левую рекурсию: 1) определяем на множестве нетерминалов какой-либо порядок (А1, А2, …, Аn) 2) берем каждый нетерминал, если для него есть продукция, учитывающая нетерминал, стоящий левее, и преобразуем грамматику: for i:=1 to n do for j:=1 to i-1 do if Ai → Ajγ then Ai→δ1γ │ δ2γ │ δkγ, где Aj → δ1│ δ2│ …│ δk 3) исключаем все случаи непосредственной левой рекурсии (правило1) Т.о. алгоритм помогает избежать зацикливания. Общий вид правила исключения левой рекурсии A → A α1 | A α2 ... | A αM | β1 | β2 ... | βN
A → β1 A´ | β2 A´ ... | βN A´ A´ → α1 A´ | α2 A´ ... | αM A´ | ε
Алгоритм LR – разбора. LR-грамматический разбор используется для большого класса КСГ. Полное название – LR(k), т.е. синтаксический анализатор рассматривает последовательность слева направо (L),используется правый вывод (R), k определяет количество символов, рассмотренных во входной последовательности для выбора продукции. Если К не указывается, то К=1.
Занести в стек символ конца входной последовательности (eof) Занести в стек начальное состояние конечного автомата Распознать лексему Повторять Если action[состояние в вершине стека, лексема]=shift S то занести в стек лексему и состояние S, после чего распознать следующую лексему Если action[состояние в вершине стека, лексема]=reduce P то извлечь из стека столько пар <состояние, грамматический символ>, сколько грамматических символов составляют правую часть правила P. В стек занести нетерминал левой части продукции P и goto[состояние в вершине стека, нетерминал левой части продукции P] Если action[состояние в вершине стека, лексема] = accept
то вывести пользователю сообщение об успешном разборе и выйти из цикла Если action[состояние в вершине стека, лексема] = ошибка то обработать ошибочную ситуацию Пока false Достоинства LR- разбора: 1) LR-анализатор может использоваться практически для всех конструкций языков программирования, которые описываются при помощи КСГ. 2) LR-анализатор позволяет обнаруживать ошибки, как только они встретятся во входной последовательности. 3) достаточно сложно строить таблицы разбора.
Типы и проверка типов. Тип данных — фундаментальное понятие теории программирования. Тип данных определяет множество значений, набор операций, которые можно применять к таким значениям и, возможно, способ реализации хранения значений и выполнения операций. Компилятор должен убедиться, что исходная программа следует как синтаксическим, так и семантическим соглашениями исходного языка. Проверка бывает статической(проверяет компилятор) и динамической(выполняется целевой программой). Компилятор должен сообщать об ошибке, если оператор применяется к несовместимому с ним операнду. Проверка типов может осуществляться сразу в семантическом анализаторе или/и после синтаксического анализа и построения синтак. дерева. Программа проверки типов проверяет, чтобы тип конструкции соответствовал ожидаемому в данном контексте. Информация о типах собирается программой проверки типов, может потребоваться при генерации кода. Построение программы проверки типов базируется на информации о синтаксических конструкциях языка, представлении типов и правилах присвоения типов конструкциям. Система типов представляет собой набор правил для назначения выражения типов различными частями программы. Программа проверки реализует систему типа синтаксическим способом.(т.е добавлением условий к правилам). Программа проверки типов представляет собой схему трансляции, синтезирующую тип каждого выражения из типов их подвыражений, и может обрабатывать массивы, указатели, инструкции и функции. Соответствие типов переменных можно сформулировать в виде логических правил типирования. В системе проверки типов содержатся аксиомы и правила вывода, на основе которых можно выводить типы выражений. Тип выражения определяется из контекста программы. Например если возьмем выражение Lispa (let ((x 5) (y 7) (+ x y)) x: int, y: int → (+x y): int (сумма тоже целочисленна) Информацию, получаемую из контекста, будем называть окружением типирования или просто окружением (Е). Тот факт, что е имеет тип τ в окружении Е будем записывать: Е├ е: τ. Такое утверждение называется типированием. Если окружение является пустым, например для одной константы 5, то запишем: ├5:Int. В процессе проверки типов окружение может расширяться, т.е. в него могут добавляться новые сведения о типе. Система проверки типов является дедуктивной системой. В ней аксиомы определяют правильное назначение типа примитивным элементам, а правила – сложным выражениям. А тип сложного выражения определяется исходя из типов составляющих его частей с применением соответствующего правила вывода: t1,t2,…/t, где t1,t2,… - типирование. Если типирование t1,t2,…выполняется (истинно), тогда выполняется и типирование t. Для суммы двух целых чисел применимо следующее правило типирования: Е├е1:Int Е├е2:Int
Все выражения программы должны иметь вывод ├е: τ для некоторого типа τ. Такие выражения называются правильно-типированные. Если для какого-то выражения тип вывести нельзя, то транслятор выдаст сообщение о несоответствии типов: type miss match.
31. L–атрибутные грамматики в детерминированном разборе сверху–вниз. Определение: Символ Устранение левой рекурсии Пусть задана леворекурсивная схема: A -> A1 Y {A.a:= g(A1.a, Y.y)} A -> X {A.a:=f(X.x)} Каждый грамматический символ имеет синтрез атрибуты, f g – произвольные функции. Устраняем левую рекурсию: A -> X R R -> YR | έ Получаем A → X { R.i:= f(X.x) } R { A.a:= R.s } R → Y { R1.i:= g(R.i, Y.y) } R1 { R.s:= R.i } R → ε { R.s:= R.i } Трансляция методом рекурсивного спуска Для построения транслятора мы должны заменить наслед. атрибуты синтезируемыми. Для этого нужно изменить структуру грамматики. Далее мы должны получить набор рекурсивных процедур, которые выполняют трансляцию. Рассмотрим, как эти процедуры построить. Для каждого нетерминала «A» строим ф-цию. В этой ф-ции для каждого наследуемого атрибута добавляем параметр. Ф-ция должна возвращать значения синтезированных атрибутов нетерминала «A». Ф-ции определяют локальные переменные для каждого атрибута, каждого граматического символа, использующего в определении А. Как и предполагает метод рекурсивного спуска ф-ция для нетерминала А сначала разбирает процукцию, которая будет исп-ться в дальнейшем разборе. Для каждой процедуры нужно написать программный код, который будет обрабатывать слева направо последовательность терминалов/нетерминалов, семантических действий, составляющих правую часть продукции: а) для терминала Х с синтезируемым атрибутом «х» он сохраняет значения атрибутов Х.х. Нужно сопоставить терминал Х с текущим символом входной последовательности. Указатель символа нужно сдвинуть вправо. б) для нетерминала В нужно сделать вызов С:=В(b1,b2,…,bn). в) для действия нужно скопировать его код в синтаксический анализатор при этом нужно поменять обращение к атрибутам на обращения к соответствующим переменным
30. L–атрибутные определения. Схемы трансляции. Порядок вычисления семантических правил. Выделим класс синтаксически управляемых определений L-АО, чьи атрибуты всегда м.б. вычислены, если дерево разбора будет строится в глубину. L-left, т.к. значения атрибутов перемещаются слева направо. Синтаксическое управление определения называется L-атрибутным, если каждый наследуемый атрибут символа Xi (1<=i<=n) в правой части продукции А→x1, x2,…,xn зависят только: 1)от атрибутов грамматических символов X1, X2,…,Xi-1 (расположенных левее него) 2) от наследуемых атрибутов символа А А→ X1, X2,…,Xi,…,Xn Схема трансляции Схема трансляции – это КСГ, в которой с грамматическими символами связаны атрибуты, а в правых частях продукций между грамматических символов могут встречаться семантические действия, которые обычно заключаются в фигурные скобки. В схеме трансляции используются как наследуемые, так и синтезируемые атрибуты. Пример использования СТ, в котором индексные выражения с операциями «+» и «-» переводятся в постфиксные. 9-5+2 → 95-2+ Схема трансляции в постфиксную запись: E → T R R → addop T {print (addop.lexem)} R1 (addop – лекс. класс, включающий в себя знаки «+» и «-»). T → num {print (num.value)}
При обходе в глубину выполняются семантические действия и получается постфиксная запись. Семантические действия будут выполняться правильно при использовании L-атрибутных определений. Практически это используется: - при использовании только синтезируемых атрибутов необходимо семантические действия расположить в конце правой части соответствующей продукции. - при использовании еще и наследуемых атрибутов необходимо руководствоваться следующими правилами: 1. наследуемый атрибут грамматического символа правой части продукции д.б. вычислен в действии, стоящем перед этим символом. 2. действие не д. обращаться к синтезируемому атрибуту символа, стоящего от него правее. 3. синтезируемый атрибут нетерминала левой части правила м.б. вычислен только после всех используемых им атрибутов. Такое действие помещается в конце левой части продукции
Недетерминированный конечный автомат: формальное определение, построение множества достижимых состояний. Если язык задан регулярными выражениями, то для него можно построить конечный автомат. КА представляется диаграммой переходов. Узлы - состояния, дуги – переходы, финальное состояние - двойной кружок. Цепочка принимается автоматом, если существует путь из начального состояния в конечное, метки дуг которого, формируют эту цепочку. Автомат называется недетерминированным, если у него есть переходы из одного и того же состояния, помеченные одним и тем же символом, и в нем присутствуют e - переходы. Формально КА определяется пятеркой <S, S, d, s0, F>, S – конечное множество состояний; S –конечное множество входных символов (алфавит); d – отношение переходов, это подмножество S на Σ, к которому добавлена пустая строка; d Í s ×(S È {e})×s s0 – начальное состояние; s0 Î S F Î S – множество финальных состояний. Для каждой пары (начальное состояние и входной символ) можно определить множество конечных состояний. Считая d функцией, через d (s,а) будем обозначать множество состояний, в которые конечный автомат может перейти из состояния s по входному сигналу а. Пользуясь функцией d, можно описать поведение конечного автомата. Функция переходов - D определяет для заданного состояния s и входной последовательности w множество состояний, в которых может оказаться автомат, обработав входную строку w. Определяется: 1) s’Î D(S,e) если s’Í d (s, e) 2) s’Î D(S,e) если есть путь по e переходам, т.е. если есть состояние s’’Î d (S,e) и одновременно s’Î d (s’’,e) 3) когда строка не пустая: s’Î D(S,aw), если есть состояние s’’Î d (s, а) и s’Î D(s’’,w). Язык распознается конечным автоматом, если он является множеством последовательностей: Например, автомат A = <S, Σ, δ, so, F> распознаёт последовательности (язык): L(A) { w | Δ(s0,w) ∩ F ≠ ∅ }, е сли автомат детерминированный: L(A) { w | Δ(s0,w) ∈ ∅ }. 4. Преобразование недетерминированного конечного автомата в детерминированный. Работа конечного автомата заключается в нахождении пути от начального состояния в конечное, по которому можно прочитать лексему. Лексема принимается, если такой путь найден. Недетерминированный конечный автомат включает e-переходы и переходы из одного состояния по одному и тому же входному символу в разные состояния. Поэтому при работе недетерминированного автомата возможны откаты в процессе поиска пути, вследствие этого недетерминированный автомат работает медленно. Для каждого недетерминированного конечного автомата можно построить детерминированный конечный автомат. Рассмотрим алгоритм преобразования. Входом алгоритма является недетерминированный автомат N, выходом – детерминированный автомат D состоящий из множества состояний Dstates и множества переходов Dtrans. Введем обозначения. S - состояние из N; T - множество состояний из N. При работе алгоритма такие множества становятся состояниями D. Пусть реализованы следующие функции. eclosure(S). Эта функция строит e-замыкание состояния S, то есть множество состояний в которые можно перейти из S по e-переходам, это множество включает также само состояние S; eclosure(T). Функция строит e-замыкание множества состояний T, то есть множество состояний, достижимых из множества состояний T через e-переходы. Это множество включает и состояния, принадлежащие T. Move(T, a). Функция строит множество состояний, в которые можно перейти из Т по входному символу а. Алгоритм состоит в следующем. Dstates:=eclose(S0); заносим в множество Dstates состояние Т = e - closure (s0) и оставляем это состояние не помеченным. Пока в Dstates хотя бы одно множество Т непомеченно выполнить begin пометить множество Т Для каждого входного символа а принадлежащего S - алфавиту автомата выполнить Begin: вычислим множество U:=eclosure(Move(T, a)); Если U Ï Dstates то Dstates:=Dstates+U заносим U в Dstates непомеченным Dtrans[T, a]:=U; end; end; Этот алгоритм позволяет построить ДКА.
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 556; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.22.249.158 (0.161 с.) |
 Алгоритм LR-разбора состоит в следующем.
Алгоритм LR-разбора состоит в следующем.
 Е├е1+е2:Int
Е├е1+е2:Int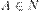 в КС-грамматике
в КС-грамматике  называется рекурсивным, если для него существует цепочка вывода вида
называется рекурсивным, если для него существует цепочка вывода вида  , где
, где  .
.  и
и  , то рекурсия называется левой, а грамматика
, то рекурсия называется левой, а грамматика  - леворекурсивной.
- леворекурсивной.  и
и  , то рекурсия называется правой, а грамматика
, то рекурсия называется правой, а грамматика  и
и 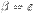 , то рекурсия представляет собой цикл.
, то рекурсия представляет собой цикл. 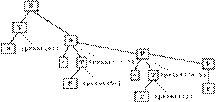 После построения дерева вставим в него семантические действия: При обходе в глубину получим последовательность операций {print}, печатающих постфиксную запись. Операции {print}включают в дерево как обычные терминалы.
После построения дерева вставим в него семантические действия: При обходе в глубину получим последовательность операций {print}, печатающих постфиксную запись. Операции {print}включают в дерево как обычные терминалы.


