Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
К.Є. Золотько, Д.В. КрасношапкаСтр 1 из 11Следующая ⇒
К.Є. Золотько, Д.В. Красношапка
Посібник до вивчення курсу „інтелектуальні системи”
Міністерство освіти і науки України Дніпропетровський національний університет Ім. Олеся Гончара
К.Є. Золотько, Д.В. Красношапка
Посібник до вивчення курсу „інтелектуальні системи”
Дніпропетровськ РВВ ДНУ
УДК 004.8 3-81
Рецензенти: д-р техн. наук, проф. О.І. Михальов д-р техн. наук, проф. О.Г. Байбуз
З-81 Золотько, К.Є. Посібник до вивчення курсу „Інтелектуальні системи” [Текст]/К.Є. Золотько, Д.В. Красношапка. – Д.: РВВ ДНУ, 2013. – 76 с.
Розглянуто теоретичні засади опису, функціонування й побудови інтелектуальних систем, висвітлено основи програмування мовою Visual Prolog та деякі методи штучного інтелекту, реалізовані в середовищі Visual Prolog. Для студентів факультету прикладної математики ДНУ, які вивчають інтелектуальні системи, також може бути корисно для всіх, хто бажає самостійно ознайомитися з методами штучного інтелекту та мовою Visual Prolog.
© Золотько К.Є., Красношапка Д.В., 2013 Вступ
Сучасний розвиток комп’ютерної техніки передбачає вирішення проблем, пов’язаних із вибором раціональної структури апаратних засобів і програмного забезпечення. Крім того, існує великий клас задач, які недостатньо повно сформульовані або мають неоднозначні розв’язки. У цих випадках можна застосувати методи штучного інтелекту. Вони дозволяють за допомогою апаратних та програмних засобів моделювати процес людського мислення. На сьогодні значного поширення набули такі основні напрямки моделювання процесу людського мислення: 1) моделювання мислення на фізіологічному рівні. При цьому в основі апаратних та програмних засобів лежать фізико-хімічні процеси, які відбуваються в нейронах людського мозку. Цей напрямок отримав назву „штучні нейронні мережі”. Використання таких нейронних мереж дозволяє вирішувати проблеми класифікації, кластеризації даних та прогнозування поведінки системи на основі великої кількості вхідних параметрів; 2) моделювання логіки людського мислення. Для моделювання логіки застосовують математичний апарат, призначений для отримання висновків у разі обмеженої кількості даних та їх неповноти. Прикладами таких спеціалізованих математичних напрямків можуть бути байєсівські мережі довіри, теорія нечіткої логіки, теорія Демстера–Шефера та ін. За допомогою цих математичних основ та спеціалізованих програмних засобів було сформовано напрямок розвитку штучного інтелекту, який отримав назву „інтелектуальні системи”.
Системи штучного інтелекту створюють за цими двома напрямками. Однак вони мають крім переваг також і недоліки, що стримує їх упровадження.
Теоретичні основи створення систем штучного інтелекту Методи розв’язання задач Функціонування численних інтелектуальних систем (ІС) має цілеспрямований характер (прикладом можуть служити автономні інтелектуальні роботи). Типовий акт такого функціонування – розв’язання задачі планування шляху досягнення потрібної мети з деякої фіксованої початкової ситуації. Результатом розв’язання задачі повинен бути план дій – частково впорядкована сукупність дій. Такий план нагадує сценарій, де як відношення між вершинами виступають відношення типу „мета – підмета” „мета – дія”, „дія – результат” і под. Будь-який шлях у цьому сценарії, що веде від вершини, відповідної поточній ситуації, до кожної з цільових вершин, визначає план дій. Про пошук плану дій в ІС можна говорити лише тоді, коли ІС стикається з нестандартною ситуацією, для якої немає заздалегідь відомого набору дій, що приводять до досягнення потрібної мети. Усі задачі побудови плану дій можна розбити на два типи, яким відповідають різні моделі: планування в просторі станів (SS-проблема) і планування в просторі задач (PR-проблема). У першому випадку вважають заданим деякий простір ситуацій. Опис ситуацій включає опис стану зовнішнього світу й стану ІС, для яких характерна низка параметрів. Ситуації створюють деякі узагальнені стани, а дії ІС чи зміни в зовнішньому середовищі приводять до зміни актуалізованих у певний момент станів. Серед узагальнених станів виділяють початкові (звичайно один) і кінцеві (цільові) стани. SS-проблема полягає в пошуку шляху, що приводить із початкового стану в один із кінцевих. Якщо, наприклад, ІС призначена для гри в шахи, то узагальненими станами будуть позиції, які створюють на шахівниці. Як початковий стан можна розглядати позицію, зафіксовану в певний момент гри, а як цільові позиції – множину нічийних позицій. Відзначимо, що у випадку шахів прямо перерахувати цільові позиції неможливо. Матові й нічийні позиції описані мовою, відмінною від мови опису станів, для яких характерне розташування фігур на полях дошки. Це утрудняє пошук плану дій у шаховій грі.
У випадку планування в просторі задач ситуація дещо інша. Простір утворюється в результаті введення на множині задач відношень типу: „частина – ціле”, „задача – підзадача”, „загальний випадок – окремий випадок” і под. Іншими словами, простір задач відбиває декомпозицію задач на підзадачі (цілі на підцілі). PR-проблема полягає в пошуку способу декомпозиції вихідної задачі на підзадачі, що приводить до задач, розв’язки яких системі відомі. Наприклад, ІС відомо, як обчислюються значення sin x і cos x для будь-якого значення аргументу і як виробляється операція ділення. Якщо ІС необхідно обчислити tg x, то вирішенням PR-проблеми буде подання цієї задачі у вигляді декомпозиції tg x= sin x/ cos x (крім х= p / 2 +k p). Рис. 3. Фрагмент графа станів
Розв’язання задач дедуктивного вибору
У дедуктивних моделях подання й обробки знань вирішувану проблему записують у вигляді тверджень формальної системи, у вигляді твердження, правдивість якого треба встановити чи спростувати на підставі аксіом (загальних законів) і правил виведення формальної системи. Як формальну систему використовують числення предикатів першого порядку. Відповідно до правил, установлених у формальній системі, заключному твердженню-теоремі, отриманому з початкової системи тверджень (аксіом, посилок), присвоюється значення ІСТИНА, якщо кожній посилці, аксіомі також присвоєно значення ІСТИНА. Процедура виведення – це процедура, яка із заданої групи виразів виводить відмінний від заданих вираз. Звичайно в логіці предикатів застосовують формальний метод доведення теорем, що допускає можливість його машинної реалізації, але існує також можливість доведення неаксіоматичним шляхом – прямим чи зворотним виведенням. Метод резолюції застосовують як повноцінний (формальний) метод доведення теорем. Для застосування цього методу вихідну групу заданих логічних формул потрібно перетворити на деяку нормальну форму. Це перетворення проводять у кілька стадій, що складають машину виведення.
Експертні системи
На початку 80-х рр. у дослідженнях зі штучного інтелекту сформувався самостійний напрямок, що одержав назву експертних систем (ЕС). Мета досліджень із застосуванням ЕС полягає в розробці програм, які в ході розв’язання задач одержують результати, що не поступаються за якістю й ефективністю рішенням, одержуваним експертами. В ЕС часто використовують термін „інженерія знань”, уведений Е. Фейгенбаумом, що означає привнесення принципів та інструментарію досліджень із галузі штучного інтелекту у вирішення складних прикладних проблем, що потребують знань експертів. Програмні засоби (ПЗ), що ґрунтуються на технології ЕС, або інженерії знань набули значного поширення у світі. ЕС призначені для розв’язання так званих неформалізованих задач, тобто ЕС не відкидають і не заміняють традиційного підходу до розробки програм, орієнтованого на розв’язання формалізованих задач.
Неформалізовані задачі звичайно мають такі особливості: – помилковість, неоднозначність, неповнота й суперечливість початкових даних; – помилковість, неоднозначність, неповнота і суперечливість знань про проблемну галузь і розв'язувану задачу; – велика розмірність простору рішення, тобто перебір у процесі пошуку рішення дуже великий; – дані й знання, що динамічно змінюються. Неформалізовані задачі – це великий і дуже важливий клас задач. Багато фахівців вважають, що ці задачі становлять найбільш масовий клас задач, розв'язуваних ЕОМ. ЕС і системи штучного інтелекту відрізняє від систем обробки даних те, що в них в основному застосовується символьний (а не числовий) спосіб подання, символьне виведення й евристичний пошук рішення (а не виконання відомого алгоритму). Основні переваги, яке забезпечує використання ЕС, такі: 1) сталість. Людська компетенція з часом слабшає. Перерва в діяльності людини-експерта може серйозно відбитися на її професійних якостях; 2) простота передачі або відтворення. Передача знань від однієї людини до іншої – досить довгий і дорогий процес. Передача штучної інформації – це простий процес копіювання програми чи файлу даних; 3) стійкість і відтворюваність результатів. Людина-експерт може приймати в тотожних ситуаціях різні рішення через емоційні фактори. Результати ЕС стабільні; 4) вартість. Послуги експертів, особливо висококваліфікованих коштують дуже дорого. ЕС, навпаки, порівняно недорогі. Їх розробка дорога, але вони дешеві в експлуатації. Водночас розробка ЕС не дозволяє цілком відмовитися від експерта-людини. Хоч ЕС добре справляється зі своєю роботою, проте в певних сферах людська компетенція явно перевершує штучну. Однак і в цих випадках із застосуванням ЕС можна відмовитися від послуг висококваліфікованого експерта, залишивши експерта середньої кваліфікації, використовуючи при цьому ЕС для посилення й розширення професійних можливостей людини. Уявлення про те, як функціонує ЕС може дати схема, зображена на рис. 4. Щоб проводити експертизу, комп'ютерна програма має бути здатна розв’язувати задачі за допомогою логічного виведення й одержувати при цьому досить надійні результати. Програма повинна мати доступ до системи фактів, яку називають базою знань.
Програма також повинна під час консультації робити висновок з інформації, що знаходиться в БЗ. Деякі ЕС можуть також використовувати нову інформацію, яку додають під час консультації. ЕС, таким чином, складається з трьох частин: 1) БЗ; 2) механізм виведення; 3) система інтерфейсу користувача. БЗ – центральна частина ЕС. Вона містить правила, що описують відношення або явища, методи і знання для розв’язання задач із галузі застосування системи. БЗ складається з фактичних знань і знань, використовуваних для виведення інших знань. Факти й правила в ЕС не завжди або правильні, або помилкові. Іноді існує деякий ступінь непевності у вірогідності факту або точності правила. Якщо цей сумнів виражений явно, то він має назву коефіцієнта довіри.
Рис. 4. Структура експертних систем
Коефіцієнт довіри – це число, що означає ймовірність чи ступінь упевненості, з яким можна вважати деякий факт або правило достовірним чи правдивим. Багато правил ЕС – евристики, тобто емпіричні правила або спрощення, що ефективно обмежують пошук рішення. ЕС використовує евристики, тому що задачі, які вона розв’язує, важкі, не до кінця зрозумілі, не підлягають строгому математичному аналізу чи алгоритмічному розв’язанню. Алгоритмічний метод гарантує коректне або оптимальне розв’язання задачі, тоді як евристичний метод в основному дає прийнятне рішення. Знання в ЕС організовані таким чином. Зокрема, знання про предметну галузь відокремлені від інших типів знань системи, таких як загальні знання про те, як розв’язувати задачі, чи про те, як взаємодіяти з користувачем. Виділені знання про предметну галузь мають назву БЗ, тоді як загальні знання щодо розв’язання задач називають механізмом виведення. Програмні засоби, що працюють зі знаннями, організованими таким чином, називають системами, заснованими на знаннях. БЗ містить факти (дані) і правила (чи інші подання знань), що застосовують ці факти як основу для прийняття рішень. Існують різні види подання даних, наприклад: · пари атрибут–значення (властивість–значення); · триплети об’єкт–атрибут–значення; · записи; · фрейми; · семантичні мережі. Найбільш фундаментальна є схема, яка використовує пари атрибут–значення. Це, наприклад, пари колір – білий, розмір – великий. Коли система оперує складними об’єктами, необхідно в пару атрибут–значення включити об’єкт. Наприклад, система встановлення меблів у кімнаті могла б мати справу зі складаними стільцями, які мають різні атрибути, такі як розмір. У цьому випадку подання даних повинне включати об’єкт. Оскільки об’єкти включено в систему, кожен із них може мати складні атрибути. Це приводить до структури, яка ґрунтується на записах, де кожен пункт даних складається з імені об’єкта і всіх пов’язаних із ним пар атрибут–значення.
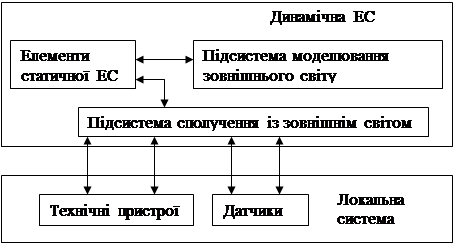
Фрейми – ще більш складний спосіб зберігання об’єктів і їх атрибутів та значень. Фрейми надають інтелектуальності поданню даних і дозволяють об’єктам успадковувати значення від інших об’єктів. Більше того, кожен атрибут може бути пов’язаний із певною процедурою (яку називають „демоном”), виконуваною в процесі запиту або відновлення атрибута. Механізм виведення містить принципи й правила роботи. Він „знає”, як використовувати БЗ, так щоб можна було одержувати розумно погоджені висновки з інформації, що знаходиться в ній. Коли ЕС ставлять питання, механізм виведення вибирає спосіб застосування правил БЗ для розв’язання задачі, окресленої в питанні. Фактично, механізм виведення запускає ЕС в роботу, установлюючи, які правила потрібно викликати і як організувати доступ у БЗ. Механізм виведення виконує правила, визначає, коли знайдено прийнятне рішення, і передає результати програмі інтерфейсу з користувачем. Коли питання треба попередньо обробити, то доступ до БЗ забезпечується через інтерфейс із користувачем. Механізм виведення містить: · інтерпретатор, що визначає, як застосовувати правила для виведення нових знань на основі інформації, що зберігається в БЗ; · диспетчер, що встановлює порядок застосування цих правил. Такі ЕС одержали назву статичних і мають структуру, зображену на рис. 5. Ці ЕС використано в додатках, де можна не враховувати зміни навколишнього світу під час розв’язання задачі. Існує більш високий клас додатків, де потрібно враховувати динаміку зміни навколишнього світу під час виконання додатка. Такі ЕС одержали назву динамічних. Їм властива структура, показана на рис. 6. Порівняно зі статичною ЕС у динамічну входять ще два компоненти: · підсистема моделювання зовнішнього світу; · підсистема сполучення із зовнішнім світом. Динамічна ЕС здійснює зв'язок із зовнішнім світом через систему контролерів і датчиків. Крім того, компоненти БЗ і механізму виведення істотно змінюються, відбиваючи часову логіку подій, що відбуваються в реальному світі.
Рис. 5. Структура статичної експертної системи
Рис. 6. Загальна структура динамічної експертної системи До таких динамічних середовищ розробки ЕС належить сім’я програмних продуктів фірми „Gensym Corp.” (США).Один із таких продуктів – система G2 – базовий програмний продукт, що являє собою графічне об'єктозорієнтоване середовище для побудови й супроводу ЕС реального часу, призначених для моніторингу, діагностики, оптимізації, планування динамічного процесу і керування ним. Існують два порядки механізму виведення – прямий (forward chaining) і зворотний (backward chaining). Інша їх назва – міркування, керовані даними (Data driven reasoning), і міркування, керовані метою (Goal driven reasoning) Прямий порядок виведення будують від активних фактів до висновку, тобто за відомими фактами знаходять висновок, який випливає з цих фактів. Цей механізм аналогічний тому, який застосовує слідчий, коли на основі певної кількості фактів визначає злочинця. За зворотного порядку виведення низку готових висновків послідовно розглядають, доки не будуть знайдені факти конкретної ситуації, які підтверджують який-небудь один висновок, тобто шляхом добору фактів, які підходять під висновок. Цей механізм аналогічний процедурі, коли в слідчого є певна кількість підозрюваних і він по черзі перевіряє кожного з них, знаходячи злочинця. Зворотне виведення ефективне для вирішення так званих проблем „структурного вибору”. Мета системи в цьому разі – зробити найкращий вибір із деякої кількості альтернатив. Наприклад, до цієї категорії потрапляє задача ідентифікації. Цю модель використовують також системи діагностики, тому що мета системи – поставити найточніший діагноз. Для значної кількості проблем неможливо перерахувати всі ймовірні відповіді до певної задачі. До цієї категорії належать, зокрема, проблеми конфігурації. Наприклад, це можуть бути системи: вибору компонентів комп’ютера; проектування монтажних схем; оптимального розміщення меблів у кімнаті і т. д. Оскільки в цьому випадку вхідні дані дуже різноманітні і їх можна скомбінувати майже нескінченною кількістю способів, зворотне виведення не ефективне. У цьому разі доцільно застосовувати пряме виведення. Системи, які ґрунтуються на прямому виведенні, часто називають продукційними. Система інтерфейсу з користувачем приймає інформацію від користувача й передає йому інформацію. Просто кажучи, система інтерфейсу повинна переконатися, що після того як користувач описав завдання, усю необхідну інформацію отримано. Інтерфейс, ґрунтуючись на виді й природі інформації, уведеної користувачем, передає необхідні дані механізму виведення. Коли механізм виведення повертає знання, виведені з БЗ, інтерфейс передає їх назад користувачу в зручній формі. Інтерфейс із користувачем і механізм виведення можна розглядати як „додаток” до БЗ. Вони разом утворюють оболонку ЕС. Для БЗ, що містить різноманітну інформацію у великому обсязі, можна розробити й реалізувати кілька різних оболонок. Добре розроблені оболонки ЕС звичайно містять механізм для додавання і відновлення інформації в БЗ. В інтерфейсі з користувачем мовою спілкування є обмежена природна мова, а не формальна мова програмування. У ньому можна використовувати всі відомі форми діалогу: · директивна. Словник цієї форми складається з ключових слів природної мови, скорочень, чисел, мнемокодів; · таблична. Складається з таких типів: вибір операції для виконання з меню; заповнення і редагування шаблону; · фразова. Використовує обмежену природну мову. Фразову форму використано в численних існуючих ЕС, але на досить примітивному рівні. Допустимі вхідні повідомлення користувача обмежені набором понять, які містяться в БЗ. Перспективний напрямок становить розробка ЕС, орієнтованих на користувача-нефахівця, який може спілкуватись із системою за допомогою повних речень, що містять будь-які частини мови. Для зменшення часу набору фраз можна застосовувати скорочення, шаблони фраз, запрограмовані клавіші ключових слів і меню. Для обробки фраз застосовують такі види аналізу: · морфологічний (лексичний) – обробка словоформ (відрізок тексту між двома сусідніми пробілами) без зв’язку з контекстом. Виділяють два методи: – декларативний – пошук у словнику всіх можливих словоформ кожного слова. Застосування цього методу уможливлює обробку повідомлень, які складаються з малих і великих літер у довільній комбінації; – процедурний – виділення в поточній словоформі основи з подальшим ідентифікуванням; · синтаксичний – побудова на основі інформації, отриманої після морфологічного аналізу, синтаксичної структури вхідного повідомлення, тобто розбір речення; · семантичний – визначення смислових відношень між словоформами (знаходження головних предикатів). Стосовно цього виду аналізу можна виділити такі функції інтерфейсу: - перетворення природномовної форми повідомлення на форму внутрішнього вигляду і зворотне перетворення; - аналіз і синтез повідомлень користувача й системи; - відстеження й запам’ятовування пройденого шляху.
Загальний огляд мови Пролог
Пролог – це мова логічного програмування, назву якої утворено від скорочення „програмування в термінах логіки”. Перший розроблений інтерпретатор Прологу було написано мовою Фортран, він працював досить повільно. У 1977 р. в Единбурзькому університеті було створено ефективний інтерпретатор/компілятор мови Пролог для комп’ютера DEC-10, що сприяло підвищенню її популярності. Відтоді було створено багато діалектів мови Пролог: СProlog, Turbo Prolog, Strawberry Prolog, Visual Prolog та ін. Visual Prolog 5.2 – це середовище програмування для мови Visual Prolog, створене фірмою „Prolog Development Center A/S” (Данія). Воно містить усі необхідні засоби для створення великих комерційних додатків, включаючи компілятор, компонувальник і велику бібліотеку підпрограм. Пролог значно відрізняється від інших традиційних мов програмування, таких як Бейсик, Паскаль чи Сі. Програміст, створюючи програму, наприклад, мовою Сі, указує, як програма повинна працювати, щоб уможливити досягнення бажаної мети (тобто визначає процедуру розв’язання задачі). Якщо програміст пише програму мовою Пролог, він спочатку описує структуру прикладної задачі, а потім указує, що треба знайти, тобто зазначає мету. Його не цікавить, яким чином ця задача буде розв’язана, це питання він перекладає на Пролог-систему. Тому Пролог належить до декларативних (описувальних) мов програмування, а Бейсик, Паскаль та Сі – до процедурних мов. Якщо класифікувати мови програмування за рівнем, то Асемблер можна віднести до мов низького рівня, Сі – до мов середнього рівня, Фортран, Бейсик, Паскаль – до мов високого рівня, Пролог – до мов надвисокого рівня.
Car(black). Speak(liza, english). Природною мовою ці факти означають таке: „Автомобіль чорний” та „Ліза говорить англійською”. Правило містить твердження, істинність якого залежить від деяких умов. Формат запису правила має вигляд голова правила>:– <тіло правила. Голова – це факт, що буде правильним за виконання умов, які знаходяться в тілі правила. Умови в тілі правила являють собою терми, з’єднані між собою комою або крапкою з комою (кома означає „і”, а крапка з комою – „або”). Символ „:–”, який стоїть між головою та тілом правила, означає „якщо”. Наприклад, правило DOMAINS author, name, publisher = symbol price = byte quantity = ulong PREDICATES CLAUSES book(alexander_abramov,riders_from_nowhere,raduga,15,200). book(agatha_christie,selected_stories,progress,20,150). book(jennifer_niederst,html,o_reilly,10,100). GOAL book(agatha_christie,selected_stories, _, _,X). Ця програма знаходить у БД кількість книжок автора Агати Крісті з назвою „Вибрані оповідання”. Нас не цікавлять видавництво й ціна, тому вони позначені анонімними змінними – знаком підкреслювання. Значення анонімних змінних не виводяться під час відповіді системи на запит. V. Розділ database (або facts) – динамічна БД. У ній розміщено факти, які можна змінювати, видаляти чи додавати в БД під час виконання програми. VІ. Розділ constants містить оголошення символічних констант. Синтаксис оголошення такий: <Id> = <Macro definition> де <Id> –ім’я символічної константи; <Macro definition> – значення, яке присвоюють константі; наприклад: CONSTANTS zero = 0 ten = (1*(10–1)+1) pi = 3.141592653 Існує декілька обмежень щодо використання символьних констант: визначення констант не може посилатися саме на себе; система не розрізняє літери верхнього і нижнього регістрів, тому в розділі clauses перша літера імені символьної константи повинна бути нижнього регістру, щоб система не сплутала константу зі змінною; у програмі може бути декілька розділів clauses, але оголосити символьну константу слід до її використання. VІІ. Розділи global domains, global predicates і global facts дозволяють оголошувати глобальні домени, предикати та речення в програмі. Ці розділи розміщують на початку програми.
Об’єкти даних Об’єкти даних можуть бути простими та складними (або структурами). Прості дані – це змінні і константи. Константа може бути символьною (char), числовою (integer, real) або атомарною (symbol, string). Складні об’єкти (далі – структури) – це об’єкти, які складаються із декількох компонент. Ці компоненти також можуть бути структурами. Наприклад, дату можна розглядати як структуру, що складається з трьох компонентів: день, місяць та рік. Для об’єднання цих компонентів у структуру треба вибрати так званий функтор – ім'я складного об'єкта. У розглядуваному випадку можна використати функтор data: Date(1, april, 2000). Структури можна зображати у вигляді дерев. Корінь дерева – це функтор, а гілки – компоненти. Якщо компонент являє собою структуру, то його можна зобразити у вигляді піддерева. Наприклад, якщо об’єкт – комп’ютер, то він становить сукупність таких компонент, як процесор, обсяг оперативної пам’яті й монітор, у свою чергу процесор включає тип, тактову частоту, обсяг кеш-пам’яті. Структуру computer(processor(Pentium – 4, 3.0, 1024), 512, Samsung 913N) можна зобразити у вигляді дерева, показаного на рис. 7.
computer / | \ processor 512 Samsung 913N / | \ Pentium 4 3.0 1024
Рис.7. Структура computer, подана як дерево
Завдання 1 Використовуючи предикати parent(string parent, string son-daughter), women(symbol) і man(symbol), розробити предикати, що визначають такі поняття: 1. Правнучка. 2. Двоюрідний брат. 3. Внук. 4. Дівер. 5. Зять. 6. Тесть. 7. Свекруха. 8. Теща. 9. Свекор. 10. Прадід. 11. Племінник. 12. Прабабуся. 13. Племінниця. 14. Свояк. 15. Тітка. 16. Своячка. 17. Дядько. 18. Дідусь. 19. Правнук. 20. Внучка. 21. Бабуся. Написати програму для пошуку й виведення на екран інформації про відповідного родича в БД.
Керування бектрекінгом
В основі роботи Пролог-системи лежить два механізми – уніфікація та бектрекінг. Уніфікація – це процес перевірки на збіг двох об’єктів і конкретизація вільних змінних. Правила уніфікації такі: 1. Якщо два об’єкти – константи, то їх можна уніфікувати, якщо вони становлять один і той же об’єкт. 2. Якщо один об’єкт – змінна, а інший – довільний об’єкт, то їх можна уніфікувати, а змінній присвоїти значення довільного об’єкта. 3. Якщо два об’єкти – структури, їх можна уніфікувати за умови, якщо: а) обидва вони мають однаковий головний функтор; б) усі їх відповідні компоненти можна уніфікувати. Наведемо приклади об’єктів, які можна уніфікувати: константи 2 і 2, ‘ s ’ і ‘ s ’; змінна X і структура data(12, May, 2004), у результаті змінній X буде присвоєне значення data(12, May, 2004); можна уніфікувати структури data(X, Y, 2004) та data(12, May, 2004), у результаті змінним X i Y будуть присвоєні значення 12 і May. Бектрекінг – це механізм циклічного рекурсивного повернення для знаходження додаткових фактів і правил, необхідних для досягнення цілі, якщо поточна спроба її досягнення виявилася невдалою. Таким чином, роботу Пролог-системи можна розглядати як рекурсивний циклічний процес уніфікації та досягнення підцілей. Наведемо для пояснення такий приклад.
Domains parent = symbol son_daughter = symbol Facts parent(parent, son_daughter) Women(symbol) Man(symbol) Predicates nondeterm son_daughter(son_daughter, parent) Clauses parent(pam, bob). Parent(bob, ann). Women(pam). Women(ann). man(bob). son_daughter(X, Y):- parent(Y, X), man(X). son_daughter(X, Y):- parent(Y, X), women(X). Goal son_daughter(ann, bob). Пролог-системі поставлено запитання, чи є Анн дочкою або сином Боба: son-daughter(ann, bob). Пролог-система починає з цілі й застосовуючи правила, замінює поточні цілі новими, допоки ці нові цілі не стануть простими фактами. Спочатку Пролог-система шукає таке речення в програмі, голову якого можна уніфікувати з ціллю, тобто із son-daughter(ann, bob). Такими реченнями є два речення, стосовні предиката son-daughter. Спочатку Пролог-система вибирає речення, яке стоїть у програмі першим: Rule:- <предикати>, Fail.
Наприклад, наведена нижче програма виводить на екран назви всіх міст, які знаходяться в БД. Щоб увімкнути підтримку кирилиці, необхідної для запуску цієї програми, треба виконати такі дії: вибрати пункт меню Options – Global (.INI)-Environment, потім у вікні Environment перейти на вкладку Fonts і в області Editor Windows клацнути кнопку Change Font, далі у вікні Шрифт у списку Набор символов вибрати Кириллический і OK).
Domains town = string Facts Town(town) Predicates print_town Clauses Town(“Київ”). Town(“Одеса”). Town(“Харків”). print_town:- Goal print_town.
Процедура, яка реалізує предикат print_town, складається з двох речень. Перше речення town(X), write(X), nl, fail. говорить: “Знайти розв’язок предиката town(X), надрукувати цей розв’язок, перейти на наступний рядок, потім повернутись і пошукати інший розв’язок”. Повернення й пошук іншого розв’язку забезпечує вбудований предикат fail, який завжди має хибне значення. Таким чином він активує бектрекінг. Без другого речення print_town. виконання програми закінчувалося б неуспішно і після виведення на екран назв усіх міст на екрані з’являлося б слово No. Інший цікавий спосіб застосування бектрекінгу для організації циклу полягає у використанні предиката repeat, який визначають таким чином:
Repeat. Repeat:- repeat. Наприклад, нижчеподана програма виводить на екран усі символи, які вводить користувач, і закінчує роботу у випадку введення символу „.” (крапка).
Predicates Nondeterm repeat Nondeterm print Clauses Repeat. Repeat:- repeat. Print:- repeat, readchar(X), write (X), X=’.’, nl. Goal Print.
Процедура print виконується таким чином. Спочатку виконується предикат repeat, який нічого не здійснює, потім зчитується з клавіатури в змінну Х деякий символ, далі він виводиться на екран, перевіряється на рівність крапці „.”. За умови, якщо символ дорівнює крапці, відбувається перехід на наступний рядок і процедура закінчується. У противному разі починається бектрекінг і перегляд альтернатив. Ні write (X),ні readchar(X) не породжують нових альтернатив, тому бектрекінг приводить далі назад до предиката repeat, який дозволяє отримати альтернативні розв’язки. Керування переходить знову на початок, зчитується символ і т. д. У цій програмі предикати repeat і print оголошуються з ключовим словом nondeterm. Це означає, що ці предикати можуть генерувати альтернативні множинні розв'язки. Такі предикати можуть також зазнавати неуспіху і в цьому випадку не породжувати ніяких розв'язків. Для організації повторів у мові Пролог також застосовують рекурсію. Як відомо, процедуру називають рекурсивною, якщо вона безпосередньо або через інші процедури звертається сама до себе. Загальний вигляд рекурсивної процедури, яка складається з двох правил, у мові Пролог такий:
rule:- <predicates>. % нерекурсивне правило rule:- <predicates>, % рекурсивне правило Rule.
Нерекурсивне правило застосовують для виходу з рекурсії, а рекурсивне – для організації рекурсії. Прикладом використання рекурсії може бути програма обчислення факторіала числа n!:
Domains chyslo = integer factorial = integer Predicates Clauses factorial(1, 1):-!. factorial(N, FactN):- N_1=N-1, factorial(N_1, FactN_1), FactN=N*FactN_1. Goal Предок(X, Z):- Батько(X, Z). Предок(X, Z):- Батько(X, Y), предок(Y, Z).
Перше і друге правила можна сформулювати відповідно так: · для всіх X і Z X є предком Z, якщо X – батько Z; · для всіх X і Z X є предком Z, якщо існує такий Y, що X є батьком Y і Y – предок Z. Як видно, перше правило рекурсивної процедури відображає окремий випадок відношення (предком є батько), а друге – загальний випадок (предком є будь-який родич за висхідною лінією). Це загальний підхід до визначення рекурсивних відношень. Domains dom_tovar = tovar(symbol,real,integer) Database Predicates Start Greeting nondeterm input_tovar nondeterm output_tovar Clauses Tovar(milk, 2.5, 100). Tovar(butter, 10.5, 50). Start:- greeting, input_tovar, output_tovar,!. Greeting:- write("Введіть назви товарів, ціну, вартість у базу даних, наприклад tovar(\"tea\", 3.4, 100).",'\n', "Назву товару введіть у лапках.","Для закінчення введення введіть крапку."), nl. input_tovar:- readchar(X),X='.',!. input_tovar:- readterm(dom_tovar, tovar(X,Y,Z)), assert(tovar(X,Y,Z)), input_tovar. output_tovar:- tovar(X,Y,Z), write(X," ",Y," ",Z), nl, fail. Goal Start. Завдання 2 Розв'язати задачі, аналогічні поданим у завданні 1 (див. розд. 2.5), з урахуванням того, що родинне дерево з фактами повинне знаходитися в динамічній БД. Користувач має сам заповнити цю БД під час виконання програми, а потім записати її у файл. Треба забезпечити можливість у подальшому зчитувати її з файлу. Програма повинна мати меню, яке дозволяє виконувати команди користувача, наприклад: 1) заповнити БД; 2) записати БД у файл; 3) зчитати БД із файлу; 4) знайти прадіда; 5) закрити програму.
Рекурсивні структури даних Рекурсивними можуть бути не тільки правила, а й структури даних. Пролог належить до тих мов програмування, у яких дуже зручно можна організовувати, описувати й реалізовувати дані рекурсивного типу. Тип даних буде рекурсивним, якщо він являє собою структуру, яка у своєму визначенні використовує структуру, подібну собі.
|
||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-08; просмотров: 341; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.129.209.84 (0.223 с.) |