
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Файловые системы, как предшественники бд. Недостатки файловых системСтр 1 из 8Следующая ⇒
Файловые системы, как предшественники БД. Недостатки файловых систем Первые АИС появились в 60е гг. В основе лежали файловые системы. Файловые системы – набор программ, предназначенных для решения той или иной задачи (расчет зарплаты и совокупность файлов, содержащих необходимые данные). Со временем стали очевидны след.недостатки файловых систем: 1) зависимость программ от данных т.к. программы на алгоритмическом языке содержат описание данных, то при изменении их структуры приходилось изменять исходные тексты программ. 2) файлы разных систем могли пересекаться, т.е. содержать одни и те же данные, например, система расчета зарплаты. Это приводило к неэкономному использованию дисковой памяти или к нарушению целостности данных. 3) невозможность совместной обработки, т.к. разные системы были написаны на разных языках программирования, то и файлы этих систем хранились в разных форматах ⇒пользователь одной системы не имел доступа к файлам другой системы. 4) быстрый рост приложений, поскольку в то время отсутствовали средства генерации отчетов произвольной формы, то для формирования каждого отчета приходилось создавать соответствующее приложение. Перечисленные недостатки являются следствием 2х причин: 1) отсутствие др. средств доступа к данным кроме приложений; 2)необходимости описания данных в приложении. Попытки исправить эти недостатки и устранить эти причины привели к появлению концепции банка данных (БнД).
Понятие, свойства и виды систем Система – организационное сложное целое, состоящее из множества элементов, расположенных в определенном порядке и зависящих друг от друга, взаимодействующих между собой при помощи отношений и связей, и образованное для выполнения конкретной цели. Свойства системы могут быть условно разделены: • на свойства I ряда – свойства, имеющие непосредственное системное происхождение: • целостность – система представляет собой организационное сложное целое; • делимость – система всегда может быть разделена на подсистемы, компоненты и элементы; • множественность – каждая система состоит из множества частей (уровни иерархии, количество элементов и связей); • целеустремленность – каждая составляющая системы должна быть ориентирована на достижение общей цели;
• свойства II ряда – свойства, которые обеспечивают работоспособность системы: • гомогенность (однородность) – система должна иметь хотя бы одно общее свойство; • гетерогенность (разнородность) – в каждой системе должно быть многообразие свойств разнородных элементов; • самоорганизованность – самостоятельно существующая и функционирующая система не должна разрушаться; • иерархичность – система – это совокупность элементов, расположенных на разных уровнях иерархии; • централизованность – в каждой системе должно быть центральное звено, которое будет стоять над всеми уровнями иерархии; • эмерджентность – свойства системы в целом отличаются от свойств отдельных ее элементов. Системы можно классифицировать: по способу образования: • естественные – системы, созданные природой без вмешательства человека; • искусственные – системы, созданные человеком для удовлетворения различных потребностей; сущности: • космические; • биологические; • технические; • социальные; • экономические; • экологические; • политические и др.; отношению к целевому назначению: • целенаправленные – системы, которые заранее программируют работы, для достижения поставленных целей; • целеустремленные – поставленные цели достигаются путем выбора альтернативных способов;
наличию центрального ведущего элемента: • централизованные – системы, в составе которых есть центральное звено, играющее ведущую роль; • децентрализованные – системы, в которых роли распределяются равномерно между элементами;
Размеру: • малые (включают менее 30 элементов); • средние (включают до 300 элементов); • большие (содержат больше 300 элементов, такие системы трудно исследовать без предварительного разбиения их на более простые функциональные составляющие);
степени сложности: • простые – системы, которые не нуждаются в разбиении на составляющие при решении проблем; • сложные – системы, подсистемы которых необходимо изучать не изолированно друг от друга, так как все элементы являются
взаимосвязанными и взаимозависимыми;
отношению к изменениям во времени: • относительно статичные – системы, имеющие одно возможное и заданное состояние; • динамичные (изменяются с течением времени);
продолжительности функционирования: • краткосрочные; • среднесрочные; • долгосрочные; • специализации: • специализированные – системы, выполняющие одну функцию при создании продукции или услуги; • комплексные – выполняют все функции при производстве продукции; • предсказуемости поведения: • детерминированные – результаты деятельности, которые могут быть предсказаны; • стохастические – результаты деятельности, которые определены вероятностью;
взаимодействию с внешней средой: • изолированные – при функционировании не имеют связей с внешней средой; • закрытые – функционируют независимо от окружающей среды и имеют строго фиксированные границы (пример, натуральное хозяйство); • открытые – взаимодействие с окружающей средой носит двусторонний характер: системы влияют на окружающую систему и на себе испытывают ее влияние.
Концептуальное, логическое и физическое проектирование базы данных Концептуальное (инфологическое) проектирование — построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных. Термины «семантическая модель», «концептуальная модель» и «инфологическая модель» являются синонимами. Кроме того, в этом контексте равноправно могут использоваться слова «модель базы данных» и «модель предметной области» (например, «концептуальная модель базы данных» и «концептуальная модель предметной области»), поскольку такая модель является как образом реальности, так и образом проектируемой базы данных для этой реальности. Конкретный вид и содержание концептуальной модели базы данных определяется выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобные ER-диаграммам. Чаще всего концептуальная модель базы данных включает в себя: · описание информационных объектов, или понятий предметной области и связей между ними. · описание ограничений целостности, т.е. требований к допустимым значениям данных и к связям между ними.
Логическое (даталогическое) проектирование — создание схемы базы данных на основе конкретной модели данных, например, реляционной модели данных. Для реляционной модели данных даталогическая модель — набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи. Преобразование концептуальной модели в логическую модель, как правило, осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован. На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД. Физическое проектирование — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т.п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и т.д.
Понятие модели Модель данных - это совокупность структур данных и операций их обработки. Рассмотрим три основных типа моделей данных: иерархическую, сетевую и реляционную. Иерархическая модель представляет собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое по структуре дерево (граф). К основным понятиям иерархической структуры относятся уровень, узел и связь. Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину, не подчиненную никакой другой вершине и находящуюся на самом верхнем - первом уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т. д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один иерархический путь от корневой записи. В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом. Реляционная модель данных объекты и связи между ними представляет в виде таблиц, при этом связи тоже рассматриваются как объекты. Все строки, составляющие таблицу в реляционной базе данных, должны иметь первичный ключ. Все современные средства СУБД поддерживают реляционную модель данных. Эта модель характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами: 1. Каждый элемент таблицы соответствует одному элементу данных. 2. Все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип и длину. 3. Каждый столбец имеет уникальное имя. 4. Одинаковые строки в таблице отсутствуют; 5. Порядок следования строк и столбцов может быть произвольным.
Понятие модели данных. Модель данных - интегрированный набор понятий для описания данных, связей между ними и ограничений, накладываемых на данные в некоторой организации. При разработке базы данных обычно выделяется несколько уровней моделирования, при помощи которых происходит переход от предметной области к конкретной реализации базы данных средствами конкретной СУБД. Можно выделить следующие уровни: - Сама предметная область - Модель предметной области - Логическая модель данных - Физическая модель данных - Собственно база данных и приложения
12. Логические модели данных. Логическая модель данных. Логическая модель описывает понятия предметной области, их взаимосвязь, а также ограничения на данные, налагаемые предметной областью. Примеры понятий - "сотрудник", "отдел", "проект", "зарплата". Примеры взаимосвязей между понятиями - "сотрудник числится ровно в одном отделе", "сотрудник может выполнять несколько проектов", "над одним проектом может работать несколько сотрудников". Примеры ограничений - "возраст сотрудника не менее 16 и не более 60 лет".
Основные понятия реляционной алгебры Реляционной базой данных называется совокупность отношений, содержащих всю информацию, которая должна хранится в базе. строка в таблице является кортежем в реляционной теории. Множество упорядоченных кортежей называется отношением. В отношении требованием является то, что все кортежи должны различаться. Для однозначной идентификации кортежа существует первичный ключ. Первичный ключ это атрибут или набор из минимального числа атрибутов, который однозначно идентифицирует конкретный кортеж и не содержит дополнительных атрибутов. В реляционной БД таблицы взаимосвязаны и соотносятся друг с другом как главные и подчиненные. Связь главной и подчиненнной таблицы осуществляется через первичный ключ (primarykey) главной таблицы и внешний ключ (foreignkey) подчиненной таблицы.
Определение сущности. Сущность – любой различимый объект (объект, который мы можем отличить от другого), информацию о котором необходимо хранить в базе данных. Сущностями могут быть люди, места, самолеты, рейсы, вкус, цвет и т.д. Необходимо различать такие понятия, как тип сущности и экземпляр сущности. Понятие "тип сущности" относится к набору однородных личностей, предметов, событий или идей, выступающих как целое. Экземпляр сущности относится к конкретной вещи в наборе.
Понятие первичного ключа
Перви́чный ключ — в реляционной модели данных один из потенциальных ключей отношения, выбранный в качестве основного ключа (или ключа по умолчанию). Если в отношении имеется единственный потенциальный ключ, он является и первичным ключом. Если потенциальных ключей несколько, один из них выбирается в качестве первичного, а другие называют «альтернативными». С точки зрения теории все потенциальные ключи отношения эквивалентны, то есть обладают одинаковыми свойствами уникальности и минимальности. Однако в качестве первичного обычно выбирается тот из потенциальных ключей, который наиболее удобен для тех или иных практических целей, например для созданиявнешних ключей в других отношениях либо для создания кластерного индекса. Поэтому в качестве первичного ключа, как правило, выбирают тот, который имеет наименьший размер (физического хранения) и/или включает наименьшее количество атрибутов. Другой критерий выбора первичного ключа — сохранение уникальности со временем. Всегда существует вероятность того, что некоторый потенциальный ключ перестанет быть таковым в долговременной перспективе или при изменении требований к системе. Например, если номер студенческой группы включает последнюю цифру года поступления, то номера групп для идентификации групп уникальны только в течение 10 лет. Поэтому в качестве первичного ключа стараются выбирать такой потенциальный ключ, который с наибольшей вероятностью не утратит уникальность.
Операция ограничения Операция ограничения требует наличия двух операндов: ограничиваемого отношения и простого условия ограничения. Простое условие ограничения может иметь либо вид (a comp-op b), где а и b - имена атрибутов ограничиваемого отношения, для которых осмысленна операция сравнения comp-op, либо вид (a comp-opconst), где a - имя атрибута ограничиваемого отношения, а const - литерально заданная константа. В результате выполнения операции ограничения производится отношение, заголовок которого совпадает с заголовком отношения-операнда, а в тело входят те кортежи отношения-операнда, для которых значением условия ограничения является true. Пусть UNION обозначает операцию объединения, INTERSECT - операцию пересечения, а MINUS - операцию взятия разности. Для обозначения операции ограничения будем использовать конструкцию A WHERE comp, где A - ограничиваемое отношение, а comp - простое условие сравнения. Пусть comp1 и comp2 - два простых условия ограничения. Тогда по определению: · A WHERE comp1 AND comp2 обозначаеттожесамое, чтои (A WHERE comp1) INTERSECT (A WHERE comp2) · A WHERE comp1 OR comp2 обозначаеттожесамое, чтои (A WHERE comp1) UNION (A WHERE comp2) · A WHERE NOT comp1 обозначаеттожесамое, чтои A MINUS (A WHERE comp1) С использованием этих определений можно использовать операции ограничения, в которых условием ограничения является произвольное булевское выражение, составленное из простых условий с использованием логических связок AND, OR, NOT и скобок. На интуитивном уровне операцию ограничения лучше всего представлять как взятие некоторой "горизонтальной" вырезки из отношения-операнда. Операция взятия проекции Операция взятия проекции также требует наличия двух операндов - проецируемого отношения A и списка имен атрибутов, входящих в заголовок отношения A. Результатом проекции отношения A по списку атрибутов a1, a2,..., an является отношение, с заголовком, определяемым множеством атрибутов a1, a2,..., an, и с телом, состоящим из кортежей вида <a1:v1, a2:v2,..., an:vn> таких, что в отношении A имеется кортеж, атрибут a1 которого имеет значение v1, атрибут a2 имеет значение v2,..., атрибут an имеет значение vn. Тем самым, при выполнении операции проекции выделяется "вертикальная" вырезка отношения-операнда с естественным уничтожением потенциально возникающих кортежей-дубликатов. Операция деления отношений Эта операция наименее очевидна из всех операций реляционной алгебры и поэтому нуждается в более подробном объяснении. Пусть заданы два отношения - A с заголовком {a1, a2,..., an, b1, b2,..., bm} и B с заголовком {b1, b2,..., bm}. Будем считать, что атрибут bi отношения A и атрибут bi отношения B не только обладают одним и тем же именем, но и определены на одном и том же домене. Назовем множество атрибутов {aj} составным атрибутом a, а множество атрибутов {bj} - составным атрибутом b. После этого будем говорить о реляционном делении бинарного отношения A(a,b) на унарное отношение B(b). Результатом деления A на B является унарное отношение C(a), состоящее из кортежей v таких, что в отношении A имеются кортежи <v, w> такие, что множество значений {w} включает множество значений атрибута b в отношении B. Предположим, что в базе данных сотрудников поддерживаются два отношения: СОТРУДНИКИ (ИМЯ, ОТД_НОМЕР) и ИМЕНА (ИМЯ), причем унарное отношение ИМЕНА содержит все фамилии, которыми обладают сотрудники организации. Тогда после выполнения операции реляционного деления отношения СОТРУДНИКИ на отношение ИМЕНА будет получено унарное отношение, содержащее номера отделов, сотрудники которых обладают всеми возможными в этой организации именами. Общая операция соединения Соединением отношений
Таким образом, операция соединения есть результат последовательного применения операций декартового произведения и выборки. Если в отношениях Тэта-соединение Определение. Пусть отношение
Это частный случай операции общего соединения. Иногда, для операции
Пример. Рассмотрим некоторую компанию, в которой хранятся данные о поставщиках и поставляемых деталях. Пусть поставщикам и деталям присвоен некий статус. Пусть бизнес компании организован таким образом, что поставщики имеют право поставлять только те детали, статус которых не выше статуса поставщика (смысл этого может быть в том, что хороший поставщик с высоким статусом может поставлять больше разновидностей деталей, а плохой поставщик с низким статусом может поставлять только ограниченный список деталей, важность которых (статус детали) не очень высока).
Таблица 1 Отношение A (Поставщики)
Таблица 2 Отношение B (Детали) Ответ на вопрос "какие поставщики имеют право поставлять какие детали?" дает
Таблица 3 Отношение "Какие поставщики поставляют какие детали" Экви-соединение Наиболее важным частным случаем Синтаксис экви-соединения:
Пример. Пусть имеются отношения
Таблица 4 Отношение P (Поставщики)
Таблица 5 Отношение D (Детали)
Таблица 6 Отношение PD (Поставки) Ответ на вопрос, какие детали поставляются поставщиками, дает экви-соединение
Обычно, такой сложной формой записи не пользуются. Но как бы то ни было, в результате имеем отношение:
Таблица 7 Отношение "Какие детали поставляются какими поставщиками" Недостатком экви-соединения является то, что если соединение происходит по атрибутам с одинаковыми наименованиями (а так чаще всего и происходит!), то в результатирующем отношении появляется два атрибута с одинаковыми значениями. В нашем примере атрибуты PNUM1 и PNUM2 содержат дублирующие данные. Избавиться от этого недостатка можно, взяв проекцию по всем атрибутам, кроме одного из дублирующих. Именно так действует естественное соединение. Естественное соединение Определение 10. Пусть даны отношения Тогда естественным соединением отношений Естественное соединение настолько важно, что для него используют специальный синтаксис:
Замечание. В синтаксисе естественного соединения не указываются, по каким атрибутам производится соединение. Естественное соединение производится по всем одинаковым атрибутам. Замечание. Естественное соединение эквивалентно следующей последовательности реляционных операций: 1. Переименовать одинаковые атрибуты в отношениях 2. Выполнить декартово произведение отношений 3. Выполнить выборку по совпадающим значениям атрибутов, имевших одинаковые имена 4. Выполнить проекцию, удалив повторяющиеся атрибуты 5. Переименовать атрибуты, вернув им первоначальные имена Замечание. Можно выполнять последовательное естественное соединение нескольких отношений. Нетрудно проверить, что естественное соединение (как, впрочем, и соединение общего вида) обладает свойством ассоциативности, т.е.
поэтому такие соединения можно записывать, опуская скобки:
Пример. В предыдущем примере ответ на вопрос "какие детали поставляются поставщиками", более просто записывается в виде естественного соединения трех отношений
Таблица 8 Отношение P JOIN PD JOIN D
Таблица 1 Отношение P JOIN PD JOIN D Таблица 3 Отношение X DEVIDEBY Y Оказалось, что только поставщик с номером 1 поставляет все детали.
Язык SQL:группировкастрок Группировка данных в операторе SELECT осуществляется с помощью ключевого слова GROUP BY и ключевого слова HAVING, с помощью которого задаются условия разбиения записей на группы. GROUP BY неразрывно связано с агрегирующими функциями, без них оно практически не используется. GROUP BY разделяет таблицу на группы, а агрегирующая функция вычисляет для каждой из них итоговое значение. Определим для примера количество книг каждего издательства в нашей базе данных:
SELECT таб1.поле1, count(таб2.поле2) FROM таб2,таб1 WHERE таб1.поле=таб2.поле GROUP BY таб1.поле1; Kлючевое слово HAVING работает следующим образом: сначала GROUP BY разбивает строки на группы, затем на полученные наборы накладываются условия HAVING. Включить в результат только те поля, данные которых оканчивается на подстроку "Press": SELECT таб1.поле, count(таб2.поле2) FROM таб1,таб2 WHERE таб1.поле1=таб2.поле1 GROUPBY таб1.поле HAVING таб1.поле LIKE '%Press';
Язык SQL:соединение таблиц. Выборка из двух таблиц путем их внутреннего соединения по столбцу КодРегиона FROM Регион INNER JOIN Поставщик ON Регион.КодРегиона = Поставщик.КодРегиона FROM table WHERE expr operator (SELECT select_list FROM table) Здесь в качестве оператора может играть роль такие операторы сравнения как >;>=;<;<=;OR;IN при работе с запросами возравщающие ровно одно значение, а также для решения задач запросами возвращающие множество строк используйте в качестве операторов IN; ANY; ALL. При этом сперва выполняется подзапрос (внутренней запрос), а результат операции будет передан основному запросу. Подзапрос – есть операция SELECT которая передает свое значения другому основному запросу. При этом возможности подзапроса велики, поэтому использования подзапросов открывает перед вами большие возможности. При этом возможно использовать подзапросы в следующих частях оператора SELECT:
Рассмотрим список правил, которые необходимо соблюдать во время построение подзапроса:
Типы подзапросов Как уже вы наверное понили из описания подзапросов существует два типа подзапросов:
Схема подзапроса возражающей одно значение: Схема подзапроса возражающей множество строк, хотя схематично изображено всего две строки, но на самом деле их может быть от двух и более. EXISTS Оператор EXISTS берет подзапрос, как аргумент, и оценивает его как верный, если подзапрос возвращает какие-либо записи и неверный, если тот не делает этого. То есть если наш подзапрос возвращает хотя бы одну строку то - это выражение принимается за истину. Читателю может показаться что это функция редко используемая - но такое мнение может сложится только при небольшом опыте общения с коллегами из департамента маркетинга. Иногда маркетологи придумывают ужасные условия и хотят тут же получить результат. EXIST поможет вам справиться как и с ужасными условиями так и с быстротой получение результата. Так как использование оператора EXIST увеличивает производительность выполнения отчета.
SELECT * FROM emp e1 WHERE EXISTS(SELECT * FROM emp e2 WHERE e1.job=e2.job and e2.sal>=3000) ORDER BY sal, job
Рассмотрим, более подробно оператор EXISTS. EXISTS как мы поняли это оператор, который возвращает всего лишь два значение TRUE | FALSE. В случае если результат подзапроса возвращает хотя бы одну строку, то TRUE, иначе FALSE. Таким образом, верхний запрос возвращает всех сотрудников, если поданнойпрофесии есть хотя бы один сотрудник кто получает >= 3000. Хотя на практике можно встретить, верхний запрос переписанный в такой вид: SELECT ename, job, sal, deptno FROM emp e1 WHERE 0 < (SELECT COUNT(*) FROM emp e2 WHERE e1.job=e2.job and e2.sal>=3000) ORDER BY sal, job
54 Язык SQL:основные команды определения данных. Таблицы создаются командой createtable. Эта команда создает пустую таблицу. Команда createtable задает имя таблицы, столбцы таблицы в виде описания набора имен столбцов, указанных в определенном порядке, а также она может определять главный и вторичные ключи таблицы. Кроме того, она указывает типы данных и размеры столбцов. Каждая таблица должна содержать, по крайней мере, один столбец. Примеркоманды create table: create table ClientInfo (FirstNamevarchar(20), LastNamevarchar(20), Address varchar(20), Phone varchar(15) Тип varchar предназначен для хранения символов не в кодировке Unicode. Число, указываемое в скобках, определяет максимальный размер поля и может принимать значение от 1 до 8000. Если введенное значение поля меньше зарезервированного, при сохранении будет выделяться количество памяти, равное длине значения. После выполнения этого запроса в окне «Сообщения» появляется сообщение: Команды выполнены успешно. После перезапуска ManagementStudio в списке таблиц появилась новая таблица Итак, была создана таблица, состоящая из четырех полей типа varchar, причем для трех полей была определена максимальная длина 20 байт, а для одного - 15. Значения полей не заполнены - на это указывает величина Null. Можно удалить созданную таблицу непосредственно в интерфейсе ManagementStudio, щелкнув правой кнопкой и выбрав «Удалить».
55 Представления (view), их назначение и использование. Представление(view) – это программно создаваемая и визуально отображаемая таблица, заполняемая данными из других таблиц, временно существующая в оперативной памяти. Для создания представления используют запрос языка SQL, реализация которого обеспечивает выборку данных для представления. Для ссылки на представление используют ключевое слово VIEW. На представлении можно выполнять операции поиска, замены, удаления записей, а также выполнять SQL-запросы. Изменение данных в представлении автоматически ведет к изменению данных в тех таблицах, из которых построено представление. Представление может быть получено как результат выборки данных через соединение с удаленными компьютерами.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-06; просмотров: 1066; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.191.132.194 (0.136 с.) |
 и
и 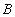 по условию
по условию  называется отношение
называется отношение
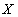 , отношение
, отношение 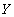 , а
, а 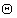 - один из операторов сравнения (
- один из операторов сравнения ( и т.д.). Тогда
и т.д.). Тогда 
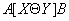
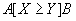 :
: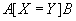
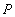 ,
,  и
и 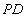 , хранящие информацию о поставщиках, деталях и поставках соответственно (для удобства введем краткие наименования атрибутов):
, хранящие информацию о поставщиках, деталях и поставках соответственно (для удобства введем краткие наименования атрибутов): . На самом деле, т.к. в отношениях имеются одинаковые атрибуты, то требуется сначала переименовать атрибуты, а потом выполнить экви-соединение. Запись становится более громоздкой:
. На самом деле, т.к. в отношениях имеются одинаковые атрибуты, то требуется сначала переименовать атрибуты, а потом выполнить экви-соединение. Запись становится более громоздкой: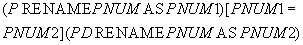
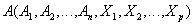 и
и 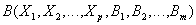 , имеющие одинаковые атрибуты
, имеющие одинаковые атрибуты 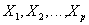 (т.е. атрибуты с одинаковыми именами и определенные на одинаковых доменах).
(т.е. атрибуты с одинаковыми именами и определенные на одинаковых доменах).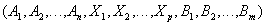 и телом, содержащим множество кортежей
и телом, содержащим множество кортежей 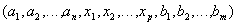 , таких, что
, таких, что  и
и 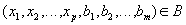 .
.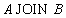
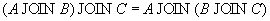
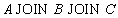
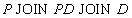 (для удобства просмотра порядок атрибутов изменен, это является допустимым по свойствам отношений):
(для удобства просмотра порядок атрибутов изменен, это является допустимым по свойствам отношений):


