
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Методы классификации. Алгоритмы классификации.
Системы классификации, построенные с использованием методов обучения, реализуются с помощью различных алгоритмов, в большей или меньшей степени эвристических. Среди множества таких алгоритмов рассмотрим три: алгоритм максимина, алгоритм К-средних, алгоритм ИЗОДАТА. Алгоритм максимина Алгоритм Максимина используют для автоматического нахождения экземпляров классов на базе обучающей выборки объёмом
Рассмотрим словесное описание этого алгоритма. Шаг 1. Задать количество образов в выборке - Шаг 2. Из совокупности образов (обучающей выборки), произвольным образом выбрать один, в качестве экземпляра первого класса. Пусть это будет образ Шаг 3. Вычислить расстояния между экземпляром первого класса
При этом образ Шаг 4. Вычислить величину порогового расстояния, равную половине расстояния между экземплярами классов
Шаг 5. Увеличить число классов на единицу: Шаг 6. Выбрать образ Шаг 7. Вычислить расстояния между экземплярами классов Шаг 8. Найти наименьшие расстояния между образом и экземплярами классов Шаг 9. Если наибольшее из наименьших расстояний Шаг 10. Если Шаг 11. Из массива Задача классификации считается выполненной, если количество экземпляров классов не изменяется, а все образы распределены по классам. Рассмотрим реализацию данного алгоритма на примере. Пусть в обучающей выборке шесть объектов, а количество существенных признаков объектов равно двум.
Для удобства описания вычислений, будем использовать четыре таблицы. Первая – это таблица значений существенных признаков объектов
Вторая таблица – таблица пометок объектов. Если объект – это экземпляр класса, то ему присваивают отрицательную пометку (номер экземпляра класса с отрицательным знаком) или положительную пометку равную номеру класса, к которому отнесён данный объект.
Третья таблица – это расстояния в выбранной метрике между экземплярами классов и непомеченными объектами.
Четвертая таблица – это таблица наименьших расстояний между объектом, который нужно классифицировать, и экземплярами классов. Она имеет следующую структуру:
Номер строки таблицы – это порядковый номер экземпляра класса; первый столбец – значение минимального расстояния; второй столбец – порядковый номер непомеченного объекта, который находится на минимальном расстоянии от данного экземпляра класса; третий столбец – номер этого класса. Выберем в качестве экземпляра первого класса первый объект:
Вычислим расстояния
Занесем полученные расстояния в таблицу
Находим наибольшее расстояние между экземпляром класса и непомеченными объектами
запоминаем номер этого объекта Выберем этот объект в качестве экземпляра следующего класса
Вычислим пороговое значение расстояния
Вычислим расстояния между экземпляром нового класса и всеми непомеченными объектами
Для всех объектов находим наименьшие расстояния между непомеченным объектом экземплярами классов:
Занесем эти расстояния, номера соответствующих объектов и классов в таблицу
Упорядочим данные в таблице в порядке убывания расстояний
Сравним
Таблица пометок будет иметь вид
Уточним значение порогового расстояния
Тогда
Вычисляем расстояния от экземпляра класса
Находим наименьшие расстояния между непомеченными объектами и экземплярами классов:
Все значения наименьших расстояний, как это следует из таблицы, меньше порога. Распределим объекты по классам: объект с номером
Поскольку в таблице пометок больше нет непомеченных объектов, то, следовательно, алгоритм закончен. Таблица пометок содержит информацию об экземплярах классов и распределении объектов между этими классами. Алгоритм К-средних Для систем автоматической классификации является характерным то, что предполагается заранее известным либо количество классов, либо объекты – представители классов. Для реализации систем автоматической классификации, при известном или заданном количестве классов, используется алгоритм К-средних. Алгоритм К-средних отличается от алгоритма Максимина, в первую очередь тем, что заранее известно или задано количество классов
здесь
Отсюда следует что положение центра
Тогда получим, что
здесь Определив новые положения центров всех классов, повторяют процедуру распределения объектов по классам. Определение новых положений центров классов и распределение объектов по классам с новыми центрами продолжают до тех пор, пока положения центров классов не перестанут изменяться. Рассмотрим словесное описание алгоритма К–средних. Он состоит из следующих шагов. Шаг 1. Задать количество классов Шаг 2. На первой итерации (
Шаг 3. Распределить объекты обучающей выборки по классам. Классы формируют следующим образом. Пусть необходимо установить к какому из классов принадлежит объект
Здесь
запомним соответствующий номер класса - Шаг 4. Положить
то есть для определения новых центров классов необходимо вычислить Шаг 5. На этом шаге используется процедура, которая позволяет установить окончание алгоритма (окончание процесса обучения системы классификации). Для этого необходимо вычислить расстояния в выбранной метрике между центрами одноименных классов на
Если при этом выполняется условие
то есть отклонение новых положений центров классов лежит в пределах заданной точности вычислений, то алгоритм закончен. В противном случае, когда
нужно вернуться к шагу 3. Рассмотрим реализацию этого алгоритма на примере, когда количество объектов равно Для удобства вычислений будем использовать четыре таблицы. Первая – это таблица значений существенных признаков объектов
Вторая таблица – таблица пометок объектов. Если объект – это центр класса, то ему присваивают отрицательную пометку (номер класса с отрицательным знаком) или положительную пометку равную номеру класса, к которому отнесён данный объект.
Третья таблица - это расстояния в выбранной метрике между координатами центров классов и непомеченными объектами.
Четвертая таблица – координаты центров классов.
Зададим желаемое число классов
и присвоим им отрицательные пометки в таблице пометок
Вычислим расстояние между центрами классов и всеми непомеченными объектами (в метрике Манхэттена).
Найдем минимальные расстояния между центрами классов и всеми непомеченными объектами, т.е. минимальные значения в каждом столбце таблицы
Здесь объекту с номером Вычислим новые значения координат центров. С этой целью поставим в соответствие всем объектам каждого класса, включая центры, векторы в пространстве существенных признаков. Например, для первого класса это будут векторы
В координатном представлении:
Поступая аналогичным образом, найдем центры оставшихся классов: Найдем расстояния между новыми и предыдущими центрами одноименных классов:
Найдем наибольшее из них Для второго центра координаты не изменились, поэтому его пометку не изменяем.
Занесем новые координаты центров в соответствующую таблицу.
Обнуляем все положительные пометки. В данном случае таблица пометок примет вид:
Вычисляем расстояния между центрами классов и непомеченными объектами
Находим наименьшие расстояния в столбцах этой таблицы. Классифицируем объекты и заполняем таблицу пометок
Вычисляем новые координаты центров
Заносим координаты новых центров в таблицу, если они изменились
Координаты центров поменялись, выполняем следующую итерацию. Обнуляем все положительные пометки.
Вычисляем расстояния от новых центров классов до всех объектов
Классифицируем объекты:
Вычисляем координаты новых центров и сравниваем их с предыдущими значениями.
Поскольку координаты центров не изменились, то алгоритм закончен. Таблица пометок содержит всю информацию о распределении объектов между классами.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-10; просмотров: 876; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.188.40.207 (0.083 с.) |
 и распределения образов по классам. При этом неизвестны, ни количество классов, ни экземпляры классов. Идея данного алгоритма заключается в следующем. В качестве экземпляра первого класса выбирают произвольно один из образов. Пусть это будет образ
и распределения образов по классам. При этом неизвестны, ни количество классов, ни экземпляры классов. Идея данного алгоритма заключается в следующем. В качестве экземпляра первого класса выбирают произвольно один из образов. Пусть это будет образ  . Вычисляют расстояния между экземпляром первого класса и всеми оставшимися образами -
. Вычисляют расстояния между экземпляром первого класса и всеми оставшимися образами -  . Среди этих расстояний найдем наибольшее
. Среди этих расстояний найдем наибольшее .
. Очевидно, что образ
Очевидно, что образ  , расположенный на наибольшем расстоянии, является экземпляром второго класса:
, расположенный на наибольшем расстоянии, является экземпляром второго класса:  . Обозначим через
. Обозначим через  подмножество образов не являющихся экземплярами классов. Вычислим расстояния между экземпляром второго класса и всеми оставшимися образами:
подмножество образов не являющихся экземплярами классов. Вычислим расстояния между экземпляром второго класса и всеми оставшимися образами:  . Для дальнейшего, необходимо установить решающее правило, которое, с одной стороны, обеспечивало бы распределение образов по классам, а с другой – создание новых классов. Сформулируем его следующим образом. Обозначим через
. Для дальнейшего, необходимо установить решающее правило, которое, с одной стороны, обеспечивало бы распределение образов по классам, а с другой – создание новых классов. Сформулируем его следующим образом. Обозначим через  пороговое значение расстояния. При этом параметр
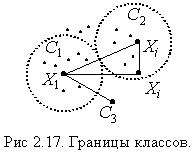
пороговое значение расстояния. При этом параметр  - это радиус сферы, ограничивающей класс, в центре которой расположен экземпляр класса. На рис.2.17 изображены на плоскости два класса и их границы – окружности с радиусом равным
- это радиус сферы, ограничивающей класс, в центре которой расположен экземпляр класса. На рис.2.17 изображены на плоскости два класса и их границы – окружности с радиусом равным  . Образы, принадлежащие каждому из классов, находятся внутри этих окружностей. При этом если минимальное расстояние между образом и экземплярами классов меньше порогового
. Образы, принадлежащие каждому из классов, находятся внутри этих окружностей. При этом если минимальное расстояние между образом и экземплярами классов меньше порогового  , т.е.
, т.е.  . Положить
. Положить  , т.е. задать количество созданных классов.
, т.е. задать количество созданных классов. и всеми оставшимися образами -
и всеми оставшимися образами -  . Из всей совокупности расстояний выбрать наибольшее
. Из всей совокупности расстояний выбрать наибольшее .
. :
: .
. .
. .
. и всеми оставшимися образами
и всеми оставшимися образами 
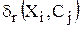 :
:  и упорядочить их в порядке убывания. Установить количество образов, которые не являются экземплярами классов
и упорядочить их в порядке убывания. Установить количество образов, которые не являются экземплярами классов 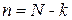 , и положить
, и положить  .
.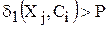 , то к уже имеющимся классам добавляется новый экземпляр класса
, то к уже имеющимся классам добавляется новый экземпляр класса  , то алгоритм закончен.
, то алгоритм закончен.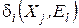 определить номер образа и номер класса. Отнести образ
определить номер образа и номер класса. Отнести образ  , т.е.
, т.е.  . Увеличить счетчик классифицированных образов на единицу
. Увеличить счетчик классифицированных образов на единицу  и перейти к шагу 10.
и перейти к шагу 10. (номер строки – номер объекта номер столбца – номер существенного признака).
(номер строки – номер объекта номер столбца – номер существенного признака).
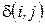
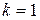 . В таблице пометок, первому элементу присвоим пометку
. В таблице пометок, первому элементу присвоим пометку 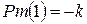 .
.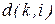 между экземпляром класса k=1 и всеми непомеченными объектами с номерами
между экземпляром класса k=1 и всеми непомеченными объектами с номерами  в метрике Манхеттена.
в метрике Манхеттена.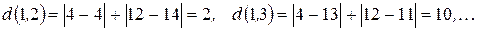
 .
.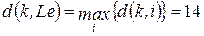 ,
, .
. . Присвоим объекту
. Присвоим объекту 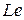 пометку
пометку 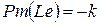 .
.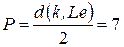 .
. и занесем данные в таблицу
и занесем данные в таблицу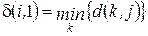
 . В рассматриваемом примере - это
. В рассматриваемом примере - это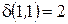 ,
,  ,
,  ,
,  ,
,  ,
,  ...
...
 с порогом. Если значение
с порогом. Если значение  , то увеличим количество классов на единицу
, то увеличим количество классов на единицу 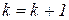 и объекту с номером
и объекту с номером  присвоим пометку
присвоим пометку .
. .
. .
. до всех непомеченных объектов.
до всех непомеченных объектов. .Упорядочим их в порядке убывания и занесем в таблицу
.Упорядочим их в порядке убывания и занесем в таблицу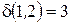 принадлежит к классу с номером
принадлежит к классу с номером  , т.е.
, т.е. 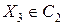 , и т.д. Занесем соответствующие пометки в таблицу пометок.
, и т.д. Занесем соответствующие пометки в таблицу пометок. . В качестве представителей этих классов могут использовать либо
. В качестве представителей этих классов могут использовать либо 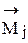 . Установив центры классов необходимо провести первый этап классификации, который заключается в распределении объектов обучающей выборке по заданным классам по принципу наименьшего расстояния. Это означает, что объект
. Установив центры классов необходимо провести первый этап классификации, который заключается в распределении объектов обучающей выборке по заданным классам по принципу наименьшего расстояния. Это означает, что объект  относят к тому классу, для которого
относят к тому классу, для которого  является наименьшим. Распределив все объекты обучающей выборки по классам, находят новые центры классов. Новые положения центров классов в пространстве существенных признаков определяют из условия минимума среднеквадратического отклонения объектов данного класса от его центра
является наименьшим. Распределив все объекты обучающей выборки по классам, находят новые центры классов. Новые положения центров классов в пространстве существенных признаков определяют из условия минимума среднеквадратического отклонения объектов данного класса от его центра
 - вектор соответствующий центру
- вектор соответствующий центру 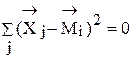 .
. ,
, - количество объектов в
- количество объектов в  .
. ) выбирают в качестве экземпляров классов первые
) выбирают в качестве экземпляров классов первые 
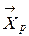 . Вычислим расстояния между данным объектом и центрами классов в выбранной метрике (например, пусть это будет метрика Евклида)
. Вычислим расстояния между данным объектом и центрами классов в выбранной метрике (например, пусть это будет метрика Евклида) .
. -количество существенных признаков,
-количество существенных признаков,  - существенный признак или
- существенный признак или  -ая координата объекта в пространстве существенных признаков,
-ая координата объекта в пространстве существенных признаков,  - координаты центра
- координаты центра  найдем наименьшее из них
найдем наименьшее из них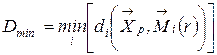 ,
,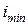 . Отнесем объект
. Отнесем объект 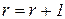 и вычислить новые положения центров классов
и вычислить новые положения центров классов ,
, -ой и
-ой и 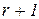 итерациях
итерациях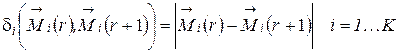 .
. ,
,
 , а количество существенных признаков равно
, а количество существенных признаков равно 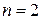 .
.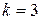 и параметр
и параметр  . Выберем в качестве экземпляров первого, второго и третьего класса соответственно первый, второй и третий объекты обучающей выборки.
. Выберем в качестве экземпляров первого, второго и третьего класса соответственно первый, второй и третий объекты обучающей выборки.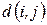 . Классифицируем объекты по критерию минимального расстояния и заполняем таблицу пометок:
. Классифицируем объекты по критерию минимального расстояния и заполняем таблицу пометок:  следовательно объект
следовательно объект 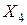 принадлежит классу
принадлежит классу  . В итоге получим
. В итоге получим ,
,  и
и 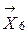 . Новое положение центра первого класса вычисляется по формуле
. Новое положение центра первого класса вычисляется по формуле .
. .
. и
и  .
.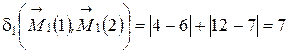 ,
, 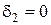 и
и  .
. . Поскольку
. Поскольку  , то необходимо повторить процедуру распределения объектов по классам с новыми центрами. Для этого необходимо выполнить следующие действия. Поскольку положения центров первого и третьего классов изменилось, то изменим знаки их пометок:
, то необходимо повторить процедуру распределения объектов по классам с новыми центрами. Для этого необходимо выполнить следующие действия. Поскольку положения центров первого и третьего классов изменилось, то изменим знаки их пометок: 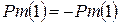 и
и  .
. ,
,  ,
,  , сравниваем их с предыдущими значениями. Положение центра
, сравниваем их с предыдущими значениями. Положение центра  изменилось и его предыдущая пометка отрицательная, поэтому изменим ее знак:
изменилось и его предыдущая пометка отрицательная, поэтому изменим ее знак:  .
.


