
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Множественное линейное уравнение регрессии
Пусть требуется построить линейную модель зависимости признака Y от набора независимых переменных
где Пусть для оценки неизвестных параметров bj (j = 1,… k) уравнения регрессии (2.1) взята случайная выборка объемом n и yi, xi1,…xik – результат i наблюдения, где i =1,… n. То есть имеется n наблюдений объясняемой переменной В матричной форме линейная модель имеет вид: Y=Xβ+ε, (2.2) где
Применяя метод наименьших квадратов, получим вектор оценок коэффициентов модели: b=(XTX)-1XTY. (2.3) Тогда выборочное уравнение регрессии имеет вид:
Несмещенную оценку остаточной дисперсии найдем по формуле:
Для проведения регрессионного анализа рассчитывают следующие показатели: - коэффициент детерминации имеет тот же самый смысл, что и R2 для парной регрессии:
- множественный коэффициент корреляции, являющийся мерой линейной зависимости между переменной у и факторами х1, х2,…, xk:
- скорректированный коэффициент детерминации корректирует значение коэффициента R2 с учетом числа независимых переменных и размером выборки, чтобы снизить влияние количества переменных:
- стандартная ошибка представляет собой стандартное отклонение для остатков. Измеряет рассеивание значений у относительно регрессии:
Для проверки значимости уравнения регрессии находят: - общую сумму квадратов, которая объясняет общую изменчивость:
- сумму квадратов остатков – это часть дисперсии, не объясненная линейной зависимостью: Qост = - сумму квадратов, обусловленных регрессией, которая измеряет часть дисперсии, объясняемую регрессионной зависимостью: Qрегр = Выполняется условие:
Для оценки значимости уравнения регрессии, то есть проверки гипотезы H0: β1= β2=…= βk=0 рассчитывают статистику:
имеющую распределение Фишера-Снедекора (F -распределение). По таблице F -распределения находят критическое значение Fкр (a; ν1,ν2), где a - уровень значимости; ν1, ν2 - число степеней свободы, ν1=k, ν2=n-k-1. Если выполняется Fнабл > Fкр, то гипотеза отвергается и уравнение считается значимым. Значимость коэффициентов регрессии βj проверяется с помощью t -критерия. Рассчитывают статистику:
где
Из таблиц распределения Стьюдента (t -распределения) находят критическое значение tкр(α; ν=n-k-1), где ν - число степеней свободы. Если |tнабл|>tкр, то гипотеза H0: βj=0 отвергается и коэффициент считается значимым. Если |tнабл| Доверительные интервалы для значимых коэффициентов регрессии строятся по формуле:
где tγ определяется из таблицы распределения Стьюдента для уровня значимости α= 1 -γ и числа степеней свободы ν=n-k-1.
Задача 2
Имеются данные о зависимости прибыли у (тыс. руб) от расходов на рекламу (тыс. руб) х1 и стоимости основных фондов х2 (тыс. руб) Данные приведены в таблице 2.1. На основании данных таблицы: а) построить уравнение регрессии у = b0+ b1х1 +b2х2 + e; б) найти оценку и проверить на 5% уровне значимость уравнения регрессии, то есть гипотезу Н0: β1= β2= 0; в) проверить значимость каждого коэффициента регрессии; г) Найти коэффициент детерминации R2. Таблица 2.1
Решение
Решим задачу в программе Exel с помощью пакета «Анализ данных». Для проведения регрессионного анализа на панели инструментов выберите «Сервис», затем «Надстройки» и при появлении окна поставить флажок на «Пакет анализа», нажать ОК. Для решения задачи введем данные задачи в столбцы А, В и С (рис.2.1).
Рис. 2.1. Входные данные
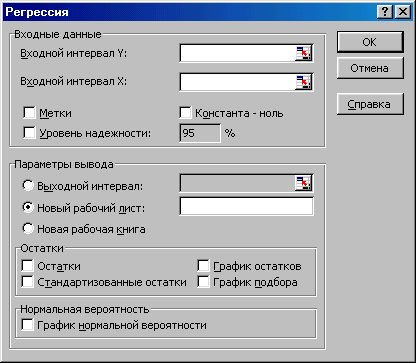
Выберите еще раз «Сервис» и «Анализ данных». При появлении окна «Анализ данных» - нажмите курсором на инструмент анализа: «Регрессия» (см. рис. 2.2). После выбора «Регрессии» появляется окно «Регрессия» (см. рис. 2.3).
Рис. 2.2. Окно «Анализ данных»
Рис. 2.3. Окно «Регрессия»
В категории Входные данные окна «Регрессия» необходимо указать: - Входной интервал Y – диапазон зависимых переменных, состоящих из одного столбца; - Входной интервал Х - диапазон независимых переменных, подлежащих анализу. Может состоять из одного или более столбцов. Максимальное количество столбцов равно 16; - Константа-ноль – для построения регрессии без свободного члена (b0), то поставьте флажок в этом окне; - Уровень надежности – для включения дополнительного уровня надежности, установите флажок в соответствующем окне. По умолчанию уровень надежности равен 95%; - Остатки (остатки, стандартизированные остатки, график остатков и график подбора) – используются как дополнительный анализ параметров вывода.
Укажем курсором столбцы входных данных (см. рис. 2.4). Выбор столбцов проводится курсором.
Входной интервал Y – это столбец С2 – С45. Входной интервал Х – это два столбца А2 до В21.
Необходимо заполнить Параметры вывода: можно установить Выходной интервал, то есть указать ячейку, в которой появится результат. Если выходной интервал не устанавливать, то решение появится на новом листе Exel.
Рис. 2.4. Выбор диапазона регрессии
Нажав ОК, получим результаты решения задачи (см. рис. 2.5).
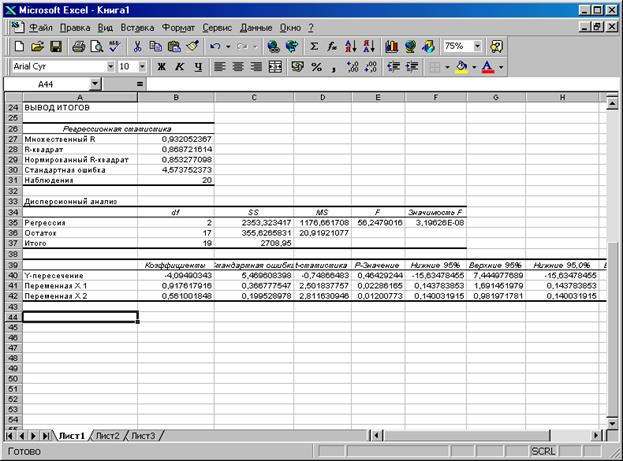
Рис. 2.5. Вывод итогов построения регрессии
В столбце «Коэффициенты» получены коэффициенты уравнения регрессии. Коэффициент b0 = - 4,09 в Таблице анализа – это Y -пересечение. Таким образом, получили уравнение регрессии:
Коэффициент b1 =0,92 показывает, что при увеличении расходов на рекламу на 1 тыс. руб. прибыль увеличивается в среднем на 0,92 тыс. руб., а увеличение стоимости основных фондов на 1 тыс. руб. приводит к увеличению прибыли в среднем на 0,56 тыс. руб. Стандартные ошибки коэффициентов:
где
Они составляют: Для проверки значимости коэффициентов регрессии рассчитываются t –статистики по формуле (2.15). Получены следующие t -статистики (рис. 2.5):
Находим критическое значение распределения Стьюдента для вероятности (уровня значимости) 0,05 и число степеней свободы n = n - k -1=20-2-1=17. Критическое значение находим из таблиц распределения Стьюдента или с помощью статистической функции СТЮДРАСПОБР(0,05;17) = 2,11. Для проверки гипотезы H0: βj=0 сравниваем полученные значения для всех коэффициентов tнабл с tкр =2,11. Получим, что все коэффициенты значимы, кроме b0. То есть на прибыль значимо оказывают влияние расходы на рекламу и стоимость основных фондов.
Для проверки значимости коэффициентов можно использовать Р -значения (ячейки Е40-Е42). По величине Р -значения возможно определять значимость коэффициентов, не находя критическое значение t -статистики. Если значение t -статистики велико, то соответствующее значение вероятности значимости мало – меньше 0,05, и можно считать, что коэффициент регрессии значим. И наоборот, если значение t -статистики мало, соответственно вероятность значимости больше 0,05 – коэффициент считается незначимым. Для коэффициентов b1 значения вероятности близко к нулю (0,02), следовательно, коэффициент b1 можно считать значимым. Аналогично определяется значимость коэффициента b2. Далее на рис. 2.5 представлены доверительные интервалы (нижняя и верхняя границы), рассчитываемые по формуле (2.15). В разделе Регрессионная статистика получили: - коэффициент детерминации R2 =0,98, рассчитывается по формуле (2.6), и показывает, что модель достаточно хорошо описывает данные, так как R2 близок к 1; - скорректированный коэффициент детерминации имеет тот же смысл, что и R2, но считается, что он точнееотражает степень адекватности модели; - стандартная ошибка, рассчитываемая по формуле (2.9). В Дисперсионном анализе вычисляются: - df – число степеней свободы; - SS – суммы квадратов разностей; - МS - оценки дисперсий; - F – вычисленное значение критерия Фишера; - Значимость F. Сумма квадратов регрессии вычисляется по формуле (2.12): Qрегр = - сумма квадратов остатков: Qост = - общая сумма квадратов:
Выполняется условие (2.13):
То есть 2353,32+355,62=2706,95. Число степеней свободы df для SS1 равно df1 =2 (k - число независимых переменных или факторов), для SS2: df2 = n – k – 1= 20 – 2 –1 =17, для SS: df = n – 1= 20 – 1 =19. Получены оценки средних кавдратов:
наблюдаемое значение F -критерия (2.14):
Сравним полученное значение Fнабл с критическим. Так как Fкрит =3,59< Fнабл =3,59, то гипотеза Н0: β1= β2= 0 отвергается и уравнение считается значимым. Значимость F – это вероятность значимости для F критерия. В нашем случае она фактически равна нулю (3,19Е-8=3,19·10-8=0), то есть гипотеза H0: β1= β2=0 отвергается и уравнение считается значимым.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-08; просмотров: 449; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.144.212.145 (0.042 с.) |
 . Модель множественной линейной регрессии записывается в виде:
. Модель множественной линейной регрессии записывается в виде: , (2.1)
, (2.1) – коэффициенты модели, e - случайная величина, удовлетворяющая условиям: математическое ожидание ошибки равно нулю; дисперсия ошибки не зависит от номера наблюдения; ошибки разных наблюдений не зависят друг от друга.
– коэффициенты модели, e - случайная величина, удовлетворяющая условиям: математическое ожидание ошибки равно нулю; дисперсия ошибки не зависит от номера наблюдения; ошибки разных наблюдений не зависят друг от друга. , и n наблюдений k объясняющих переменных
, и n наблюдений k объясняющих переменных  .
. - вектор-столбец наблюдений размерности n;
- вектор-столбец наблюдений размерности n;  - матрица независимых переменных размерности n´(k+1);
- матрица независимых переменных размерности n´(k+1); - вектор-столбец неизвестных параметров, подлежащих оцениванию, размерности (k+1);
- вектор-столбец неизвестных параметров, подлежащих оцениванию, размерности (k+1); - вектор-столбец случайных ошибок размерности n.
- вектор-столбец случайных ошибок размерности n. . (2.4)
. (2.4) . (2.5)
. (2.5) ; (2.6)
; (2.6) ; (2.7)
; (2.7)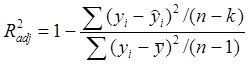 ; (2.8)
; (2.8) . (2.9)
. (2.9)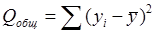 ; (2.10)
; (2.10)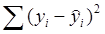 ; (2.11)
; (2.11)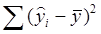 . (2.12)
. (2.12) , то есть
, то есть , (2.14)
, (2.14) , (2.15)
, (2.15) - дисперсия коэффициента регрессии bj;
- дисперсия коэффициента регрессии bj;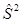 - несмещенная оценка остаточной дисперсии (2.5);
- несмещенная оценка остаточной дисперсии (2.5);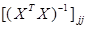 - элементы обратной матрицы, стоящие на главной диагонали;
- элементы обратной матрицы, стоящие на главной диагонали; - стандартная ошибка коэффициента bj. Измеряет отклонение имеющихся данных уi от их оценок
- стандартная ошибка коэффициента bj. Измеряет отклонение имеющихся данных уi от их оценок  .
. tкр, то гипотеза H0 не отвергается.
tкр, то гипотеза H0 не отвергается. , (2.16)
, (2.16)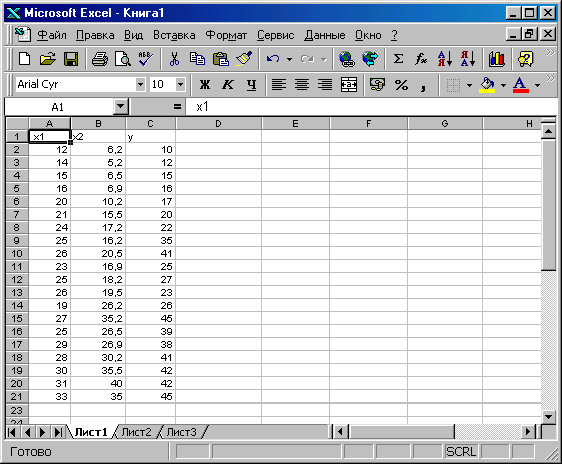


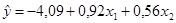 .
. ,
,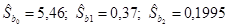 .
.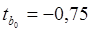 ;
; 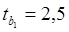 ;
; 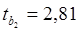 .
. = SS1 + SS2 = SS.
= SS1 + SS2 = SS. ;
; ;
; .
.


