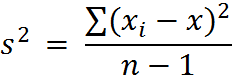Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Описание данных: «меры рассеяния»
Обобщение данных Если кратко изложить две меры непрерывной переменной, одна из которых показывает «средние» данные, а другая описывает «рассеяние» наблюдений, то данные удастся значительно сконцентрировать. Размах (интервал изменения) Размах – разность между максимальным и минимальным значениям переменной в наборе данных; вы найдете эти две величины, на которые ссылаются вместо их разности. Обратите внимание, что этот размах вводит в заблуждение, если одно из значений – выброс. Размах, полученный из процентилей Что такое процентили? Предположим, что мы расположим наши данные упорядоченно, начиная с самой маленькой величины переменной X и заканчивая самой большой величиной. Величина X, до которой расположен 1% наблюдений, находящихся ниже X (99% наблюдений находятся выше значения X), называется первый процентиль. Величина X, до которой находится 2% наблюдений, называется второй процентиль и т.д. Величины Х, которые делят упорядоченный набор значений на 10 равных групп, т.е. 10-й, 20-й, 30-й, …, 90-й процентили, называются децили. Величины X, которые делят упорядоченный набор значений на четыре равные группы, т.е. 25-й, 50-й, и 75-й процентили, называются квартили. 50-й процентиль – медиана. Применение процентилей Мы можем добиться такой формы описания рассеяния, на которую не повлияет выброс (аномальное значение), при этом, исключая экстремальные величины в наборе данных и определяя размах остающихся наблюдений. Межквартильный размах – разница между первым и третьим квартилем, т.е. между 25-м и 75-м процентилями. В него входят центральные 50% наблюдений в упорядоченном наборе, где 25% наблюдений находятся ниже центральной точки и 25% - выше. Интердецильный размах содержит в себе центральные 80% наблюдений, т.е. те наблюдения, которые располагаются между 10-м и 90-м процентилями. Часто используют размах, который содержит 95% наблюдений, т.е. он исключает 2,5% наблюдений снизу и 2,5% сверху. Можно применить этот интервал, осуществляя диагностику болезни. В этом случае он называется референтный интервал, референтный размах или нормальный размах. ДИСПЕРСИЯ (от лат. – disperses – рассеянный, рассыпанный). Один из способов измерения рассеяния данных заключается в том, чтобы определить степень отклонения каждого наблюдения от средней арифметической. Очевидно, что чем больше отклонение, тем больше изменчивость, вариабельность наблюдений. Однако мы не можем использовать среднее этих отклонений как меру рассеяния, потому что положительные отклонения компенсируют отрицательные отклонения (их сумма тождественно равна нулю). Для того чтобы решить эту проблему, мы возводим в квадрат каждое отклонение и находим среднее возведенных в квадрат отклонений; эта величина называется вариацией, или дисперсией. Возьмем, например, n наблюдений, x1, x2, x3, …, xn, средняя которых равняется
мы вычисляем дисперсию, обычно обозначаемую как S2, этих наблюдений следующим образом:
Мы видим, что это не то же, что среднее арифметическое возведенных в квадрат отклонений, потому что мы разделили на (n-1) вместо n. Причина этого в том, что мы почти всегда полагаемся на выборочные данные в наших исследованиях. Теоретически можно показать, что мы получим более точную дисперсию, если разделим не на n, а на (n-1). Единица измерения (размерность) вариации – квадрат единиц измерения первоначальных наблюдений, например: если вариация измеряется в килограммах, то единицей измерения вариации будет «кг2». СТАНДАРТНОЕ ОТКЛОНЕНИЕ Стандартное (среднее квадратичное) отклонение – положительный квадратный корень из дисперсии. На примере n наблюдений это выглядит так:
Мы можем размышлять о стандартном отклонении как о своего рода среднем отклонении наблюдений от среднего. Его вычисляют в тех же самых единицах (размерностях), что и исходные данные. Если разделить стандартное отклонение на среднее арифметическое и выразить этот показатель в процентах, получится коэффициент вариации. Это мера рассеяния которая не зависит от единиц измерения (безразмерная), но имеет некоторые теоретические неудобства, поэтому статистики её не всегда одобряют. Понимание вероятности. Вероятность измеряет неопределенность.Она находится в самом центре статистической теории. Вероятность измеряет возможность появления данного события. Можно вычислить вероятность, используя различные подходы.
- Субъективная – индивидуальная степень уверенности, что данное событие произойдет (например, случится конец света в 2050 г.). - Частотная – выражающая соотношение количества событий, которые могли бы произойти, если бы мы повторяли эксперимент огромное количество раз (например, если бы мы бросали монету 100 раз, сколько бы раз выпал «орёл»). - Априорная – требующая знания теоретической модели, называемой распределением вероятности, которая отображает вероятности всех возможных результатов «эксперимента». Например, генетическая теория позволяет нам отобразить вероятность распределения цвета глаз у ребёнка при рождении, если у женщины голубые глаза, а мужчины карие, первоначально определяя весь возможный генотип цвета глаз у ребенка и их вероятности.
|
||||||
|
|
Последнее изменение этой страницы: 2017-01-27; просмотров: 397; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.220.160.216 (0.025 с.) |