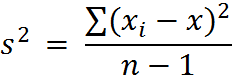Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Отношение шансов (odds ratio)Стр 1 из 8Следующая ⇒
Отношение шансов (odds ratio) это отношение шансов для первой группы объектов к отношению шансов для второй группы объектов. Интерпретация: 1) Если отношение шансов=1, то шанс для первой группы равен шансу для второй группы. 2) Если отношение шансов>1, то шанс для первой группы больше шанса для второй группы. 3) Если отношение шансов<1, то шанс для первой группы меньше шанса для второй группы.
Правило сложения вероятностей Если два события, А и В, взаимоисключающие, несовместимые, то вероятность события А или В равна сумме их вероятностей: Р(А или В)= р(А)+р(В)
Правило умножения вероятностей: Если два события, А и В, независимы (т.е. возникновение одного события не влияет на возможность появления другого), то вероятность того, что оба события произойдут, равна произведению вероятности каждого: P(A и B)=p(A)*p(B)
Случайная величина – величина, которая при реализации определенного комплекса условий может принимать различные значения. Закон больших чисел: при достаточно большом числе наблюдений случайные отклонения взаимно погашаются, и проявляется основная тенденция (закономерность).
Приступая к изучению основ статистического анализа необходимо выделить два основных этапа: - описание полученного в ходе исследования массива данных - анализ данных и проверка различных статистических гипотез
Прежде чем приступить к анализу данных и проверке различных гипотез: 1) Сформулируйте вопрос, на который Вы хотите ответить с помощью статистического анализа. 2) Выберите наиболее адекватный для ответа на данный вопрос статистический критерий или метод. 3) Правильно интерпретируйте его результаты.
Анализ организации конкретного исследования и его результатов: - оценить адекватность дизайна научного исследования решению той или иной проблемы эпидемиологии и общественного здоровья. - Анализ технологии приведенного исследования. - Оценка полученных результатов. - практическое применение полученных результатов. Знание возможностей статистических методов необходимо каждому работающему в медицине и здравоохранении. Пакеты прикладных программ: SPSS (Statistical Package for Social Science) SAS STATA STATISTICA BIOSTATISTICA Epilnfo программа «R» Сплошное исследование – такое наблюдение, при котором изучаются все единицы наблюдения объекта исследования, т.е. так называемая генеральная совокупность.
Выборочное наблюдение – это вид несплошного наблюдения, при котором отбор подлежащих обследованию единиц наблюдения осуществляется случайно из генеральной совокупности, после чего результаты распространяются на всю исходную совокупность. Сформированная таким образом совокупность называется выборочной или выборкой.
Sample Population Примеры генеральной совокупности: 1. Аспирин произведенный в прошлом, выпускаемый сейчас и весь, который будет произведен в будущем. 2. Студенты 3 курса, учившиеся в прошлом, учащиеся в этом году и которые будут учиться в будущем. Под количественной репрезентативностью понимают достаточное число единиц наблюдения в выборке для проявления закона больших чисел. Закон больших чисел сформулированный Якобом Бернулли (1654-1705) закон, который гласит, что точность среднего значения выборки увеличивается (или стандартная ошибка статистики уменьшается) с ростом количества единиц в выборке. Чем больше выборка, тем с большей вероятностью ее можно рассматривать в качестве «универсума» (генеральной совокупности). Закон достоверен только для несмещенных выборок. Под качественной репрезентативностью понимают соответствие признаков у единиц наблюдения генеральной и выборочной совокупностей. Репрезентативность выборки зависит от её численности и от способов формирования выборочной совокупности, т.е. способов отбора единиц наблюдения (методов рандомизации). Главное требование, предъявляемое к отбору – это его случайность (рандомизированный отбор). При этом каждой единице наблюдения обеспечивается одинаковая вероятность попадания в выборку благодаря случайности отбора. Случайность отбора достигается путем выбора и применения адекватного метода рандомизации, от которого будет зависеть полноценность получаемых данных и, в конечном итоге, успех всего исследования. Типы признаков Качественные, категориальные или номинальные – не поддающиеся непосредственному измерению, например, характеристики пациента: диагноз, пол, профессия, семейное положение.
Качественные данные, которые могут быть отнесены только к двум противоположным категориям (да-нет), принимающие одно из двух значений (жив-умер; курит-не курит) называются дихотомическими. Порядковые, ординальные или ранжируемые – эти признаки можно расположить в естественном порядке (ранжировать), но при этом отсутствует количественная мера расстояния между величинами. Примеры порядковых признаков: - оценка тяжести состояния пациента; - стадия болезни; - самооценка состояния здоровья. При этом допускается, что тяжелое течение заболевания «хуже», чем среднетяжелое, а очень тяжелое – «еще хуже», однако нельзя сказать во сколько и на сколько хуже. Таким образом, порядковые данные занимают промежуточное положение между количественными и номинальными типами. Их можно упорядочить как количественные данные, но над ними нельзя производить арифметические действия, также как и над номинальными данными. Количественные или интервальные – признаки, количественная мера которых четко определена; наиболее удобный для статистического анализа тип данных. Количественные признаки могут быть непрерывными, принимающими любое значение на непрерывной шкале (масса тела, температура, биохимические показатели крови). Дискретными, принимающие лишь определенные значения из диапазона измерения, обычно целые (число рецидивов, число детей в семье, число заболеваний у одного больного, число выкуриваемых сигарет). Пример с оценкой результата забега на скачках Номинальный признак - Эта лошадь пришла первой??? 0 – нет; 1 – да. Интервальный признак - Какой результат у этой лошади??? 60 сек. Типы данных Цель большинства исследований состоит в сборе данных, которые впоследствии помогают получить информацию относительно какой-либо области исследования. Данные всегда основаны на наблюдениях одной или нескольких переменных; термин переменная означает количественный показатель, способный изменяться. Например, мы можем собрать основную клиническую и демографическую информацию о пациентах со специфической болезнью. Интересующими нас переменными могут пол, возраст и рост больного. Обычно мы получаем данные из выборки индивидуумов, представляющих популяцию – группу индивидуумов, которая представляет для нас интерес. Цель состоит в том, чтобы сгруппировать эти данные и извлечь полезную информацию. Статистика использует различные методы, например, сбор данных, их обобщение, анализ и подведение итогов, основанных на полученных сведениях. Существуют различные формы данных. Прежде чем решить, какой статистический метод окажется наиболее подходящим для конкретного случая, мы должны знать, к какому типу данных относится каждая переменная. Все переменные, результирующие показатели, можно разделить на 2 типа: категориальный (качественный) или числовой (количественный). Форматы ввода данных. Существует несколько способов ввода данных и сохранения их в компьютере. Большинство статистических пакетов позволяют сразу же вводить данные. Однако существуют ограничения, а именно: вы не сможете переносить данные из одного пакета в другой. Простейшая альтернатива – сохранять данные либо в электронной таблице, либо в пакете баз данных. К сожалению, их статистические процедуры часто ограничены, и обычно возникает необходимость вводить данные в статистический пакет, чтобы провести исследования.
Используя любой подход, при исследовании принято, чтобы каждая строка данных соответствовала отдельному индивидууму и каждая колонка соответствовала переменной, хотя может возникнуть необходимость в продолжении последовательных рядов, в случае если на каждого индивидуума собрано большое количество переменных. Категориальные данные. С нечисловыми данными могут возникнуть проблемы при занесении их в некоторые статистические пакеты, поэтому вам необходимо назначить числовые коды категориальным данным, прежде чем вводить данные в компьютер. Например, вы можете выбрать следующие коды: 1, 2, 3 и 4 категориям «нет боли», «легкая боль», «средняя боль» и «сильная боль» соответственно. Эти коды могут быть добавлены к формам при сборе данных. Для бинарных данных, например, ответов «да/нет», очень удобно установить код 1 (например, для «да») и 0 (для «нет»). - переменные с единственным альтернативным вариантом ответа. Существует только один возможный вариант на вопрос. Например, на вопрос «Умер ли пациент?» невозможно ответить и «да» и «нет». - Переменные с несколькими альтернативами ответа. Возможен более чем один ответ. Например, на вопрос: «Каковы симптомы болезни у пациента» - можно перечислить несколько симптомов. Существует два способа обработки этих данных в зависимости от того, какую из двух следующих ситуаций применить. ü Существует несколько возможных симптомов и многие из них присутствуют у пациента. Можно создать ряд различных бинарных переменных, все зависит от того, ответит ли больной «да» или «нет» относительно возможных симптомов. Например, был ли у него кашель, болело ли горло. ü Существует огромное количество возможных симптомов, но у пациента могут быть только некоторые из них. Можно создать ряд различных номинальных переменных, каждая из которых позволит определить наличие того или иного симптома больного. Например, какой симптом возник первым, какой вторым и т.д. Вы заранее должны определить максимальное количество симптомов, которые, вы полагаете, могут быть у больного. Числовые данные должны быть введены с той же самой точностью, с которой были проведены измерения, и единица измерения должна быть едина для всех наблюдений данной переменной. Например, масса должна быть записана в килограммах или в граммах, но не попеременно то в кг, то в г.
Проверка ошибок и выбросов При любом исследовании всегда есть опасность допустить ошибки при наборе данных либо вначале, при измерениях, либо при сборе, переписывании и вводе данных в компьютер. Довольно трудно избежать этих ошибок. Однако можно сократить количество опечаток и описок путем тщательной проверки данных, как только они будут введены. Даже бегло просмотрев таблицу, можно обнаружить очевидные ошибки. Опечатки Опечатки – самые распространенные ошибки при вводе данных. Если количество данных невелико, мы можете сравнить уже напечатанные с оригинальными, просто просмотрев их, и проверить, нет ли ошибок. Однако при большом объеме данных на это потребуется слишком много времени. Можно ввести данные дважды и сравнить их при помощи компьютерной программы. Любы различия между двумя вариантами будут обнаружены. Хотя не исключено, что одна и та же ошибка может быть допущена в обоих случаях или данные в форме/анкете неправильные, но по крайней мере это сводит к минимуму количество ошибок. Недостаток этого метода заключается в том, что приходится дважды вводить данные, а это может повлечь большие затраты денег и времени. Проверка ошибок - категориальные данные. Относительно легко проверить категориальные данные, так как отклики на каждую переменную (переменная отклика) могут принимать только одно из ограниченного ряда значений, поэтому данные, которые недопустимы, должны считаться ошибочными. - числовые (количественные) данные. При вводе числовых данных достаточно просто поменять местами цифры или не туда поставить десятичную запятую – и данные искажены, поэтому их довольно трудно проверить, но и здесь надо попытаться устранить ошибки. Числовые данные можно проверить по размаху, т.е. задать верхние и нижние ограничения для каждой переменной. Если величина находится за пределами этого интервала, то она не используется при дальнейшем исследовании. - Даты. Часто трудно проверить точность дат, хотя иногда вам следует знать, что в определенный период времени данные могут выпадать (исчезать). Даты необходимо проверять хотя бы ради того, чтобы удостовериться, что они действительны. Во всех проверках величина должна быть исправлена только в том случае, если ошибка очевидна. Не следует менять данные только потому, что они выглядят необычными. Проверка выбросов Самый простой метод состоит в том, чтобы во время набора данных проверять их глазами. Это приемлемо, если количество наблюдений не слишком большое и потенциальный выброс намного ниже или выше, чем остальная часть данных. Выбросы также можно увидеть на гистограммах и диаграммах рассеяния. Обращение с выбросами Нельзя убрать индивидуума из анализа только потому, что его/ее данные выше или ниже, чем должны быть. Однако включение выбросов может повлиять на результаты, когда используются какие-нибудь статистические методы. Самый простой метод состоит в том, чтоб повторить анализ как с включенными, так и с исключенными данными. Если результаты окажутся одинаковыми, то в этом случае выбросы не окажут большого влияния на результаты. Однако, если результаты сильно отличаются, следует применить соответствующие методы, при которых выбросы не повлияют на исследование данных. Они включают в себя применение преобразований и непараметрических критериев.
Круговая диаграмма Круговая диаграмма делится на секции, каждой из которых отводится определенная категория, таким образом, чтобы площадь каждого сектора была пропорциональна частоте этой категории. Гистограмма Здесь не должно быть пробелов между столбцами, так как данные непрерывны. Ширина каждого столбца гистограммы должна соответствовать интервалу значений данной переменной. Площадь столбца пропорциональна частоте в данном интервале, поэтому, если одна из групп охватывает более широкий интервал, чем другие, то основание столбца будет шире, а высота, соответственно меньше. Точечный график Каждое наблюдение изображено одной точкой на горизонтальной (или вертикальной) линии. Этот тип графика очень просто чертить, но только при небольшом объеме данных. График «стебель и листья» Это смесь диаграммы и таблицы; он похож на гистограмму и эффективен для отображения данных по увеличению порядка величины. Обычно чертят вертикальный стебель, который состоит из нескольких первых цифр данных, приведенных по порядку. Выходящие наружу от этого стебля листья – конечная цифра всех данных по порядку, которые написаны горизонтально в порядке увеличения порядка расположения числа. График Box-plot Этот тип графиков часто называют «ящиком с усами». Это вертикальный или горизонтальный прямоугольник, где две параллельных стороны отвечают верхнему и нижнему квартилям данных. Линия, проведенная поперек прямоугольника, отвечает значению среднего. «Усы», начинающиеся в конце прямоугольника обычно показывают минимальные и максимальные значения, но иногда указывают и особые процентили, например, 5-й и 95-й процентили. Здесь же могут быть обозначены и выбросы (аномально большие или малые значения). ДВЕ ПЕРЕМЕННЫЕ Если одна переменная категориальная, тогда отдельные диаграммы, показывающие распределение второй переменной, должны быть начерчены для каждой категории. Другие графики, подходящие для таких данных, включают групповые или сегментные линии или графики с колонками. Если обе переменные непрерывные или ординальные, то связь между ними можно изобразить при помощи двухмерной диаграммы рассеяния (скаттерплот). Это двухмерный график, где оси переменных перпендикулярны друг другу. Одна переменная обычно называется x переменная и отображается на горизонтальной оси. Вторая переменная, известная как y переменная, наносится на вертикальную ось. Обобщение данных Довольно трудно «прочувствовать» числовые измерения, до тех пор, пока данные не будут обобщены содержательным образом. Диаграмма бывает, полезна в качестве отправной точки. Также можно сжать информацию, представив величины, наиболее важные для характеристики данных. В частности, если знать, из чего состоит представленная величина или насколько широко рассеяны наблюдения, можно сформировать образ этих данных. Мера положения — общее понятие для числового выражения локализации (на числовой оси); которое описывает типичный результат измерения. Мы посвящаем эту главу мерам положения, самые распространённые из которых — среднее и медиана (табл. 5-1). СРЕДНЕЕ АРИФМЕТИЧЕСКОЕ (ARITHMETIC MEAN) – сумма значений, полученных в ходе нескольких измерений, деленная на количество этих значений. СРЕДНЯЯ АРИФМЕТИЧЕСКАЯ (MEAN, ARITHMETIC) – одна из мер центральной тенденции. Вычисляется путем суммирования всех величин в группе и последующего деления полученной суммы на число слагаемых. Среднее арифметическое, которое очень часто называют просто среднее, для набора значений вычисляют следующим образом: складывают все значения и делят эту сумму на количество значений в этом наборе. Можно суммировать это буквальное выражение при помощи алгебраической формулы. Используя математическую систему обозначения, мы можем изобразить набор n наблюдений переменной х, как х1, х2, х3,.., хn. Например, х мог бы обозначать рост индивидуума (сантиметры), так чтобы х1 обозначал рост первого индивидуума, а хi — рост i индивидуума и т.д. Мы можем написать формулу для среднего арифметического наблюдений, пишется, x произносится «х с чертой»:
Используя математическую систему обозначения, мы можем сократить это выражение:
МЕДИАНА Вид меры центральной тенденции. Простейшее деление набора измерений на две части: нижнюю и верхнюю половины. Точка на шкале, которая делит группу таким образом, называется медианой. Если мы упорядочим данные по величине, начиная с самой маленькой величины и заканчивая самой большой, то медиана также будет характеристикой усреднения в упорядоченном наборе данных. Медиана делит ряд упорядоченных значений пополам, с равным числом этих значений как выше, так и ниже её (левее и правее медианы на числовой оси). Вычислить медиану легко, если количество наблюдений n нечётное. Это будет наблюдение с номером (n+1)/2 в нашем упорядоченном наборе данных. Например, если n=11, то медиана — (11+1)/2=12/2=6, 6-е наблюдение в упорядоченном наборе данных. Если n чётное, тогда, строго говоря, медианы нет. Однако обычно мы вычисляем её как среднее арифметическое двух соседних средних наблюдений в упорядоченном наборе данных [т.е. наблюдений с номерами (n/2) и (n/2+1)]. Так, например, если n=20, то медиана — среднее арифметическое из наблюдений с номерами 20/2=10 и (20/2+1)=11 в упорядоченном наборе данных. Медиана подобна среднему значению, если данные симметричны (рис. 5-1), меньше, чем среднее значение, если данные скошены вправо (рис. 5-2), и больше, чем среднее значение, если данные скошены влево. Мода Мода — значение, которое встречается наиболее часто в наборе данных; если данные непрерывные, то мы обычно группируем их и вычисляем модальную группу. Некоторые наборы данных не имеют моды, потому что каждое значение встречается только один раз. Иногда можно встретить более одной моды; это происходит тогда, когда два значения или более встречаются одинаковое количество раз и частота встречаемости каждого из этих значений больше, чем таковые для любого другого значения. Мы редко используем моду как обобщающую характеристику. Обобщение данных Если кратко изложить две меры непрерывной переменной, одна из которых показывает «средние» данные, а другая описывает «рассеяние» наблюдений, то данные удастся значительно сконцентрировать. Размах (интервал изменения) Размах – разность между максимальным и минимальным значениям переменной в наборе данных; вы найдете эти две величины, на которые ссылаются вместо их разности. Обратите внимание, что этот размах вводит в заблуждение, если одно из значений – выброс. Что такое процентили? Предположим, что мы расположим наши данные упорядоченно, начиная с самой маленькой величины переменной X и заканчивая самой большой величиной. Величина X, до которой расположен 1% наблюдений, находящихся ниже X (99% наблюдений находятся выше значения X), называется первый процентиль. Величина X, до которой находится 2% наблюдений, называется второй процентиль и т.д. Величины Х, которые делят упорядоченный набор значений на 10 равных групп, т.е. 10-й, 20-й, 30-й, …, 90-й процентили, называются децили. Величины X, которые делят упорядоченный набор значений на четыре равные группы, т.е. 25-й, 50-й, и 75-й процентили, называются квартили. 50-й процентиль – медиана. Применение процентилей Мы можем добиться такой формы описания рассеяния, на которую не повлияет выброс (аномальное значение), при этом, исключая экстремальные величины в наборе данных и определяя размах остающихся наблюдений. Межквартильный размах – разница между первым и третьим квартилем, т.е. между 25-м и 75-м процентилями. В него входят центральные 50% наблюдений в упорядоченном наборе, где 25% наблюдений находятся ниже центральной точки и 25% - выше. Интердецильный размах содержит в себе центральные 80% наблюдений, т.е. те наблюдения, которые располагаются между 10-м и 90-м процентилями. Часто используют размах, который содержит 95% наблюдений, т.е. он исключает 2,5% наблюдений снизу и 2,5% сверху. Можно применить этот интервал, осуществляя диагностику болезни. В этом случае он называется референтный интервал, референтный размах или нормальный размах. ДИСПЕРСИЯ (от лат. – disperses – рассеянный, рассыпанный). Один из способов измерения рассеяния данных заключается в том, чтобы определить степень отклонения каждого наблюдения от средней арифметической. Очевидно, что чем больше отклонение, тем больше изменчивость, вариабельность наблюдений. Однако мы не можем использовать среднее этих отклонений как меру рассеяния, потому что положительные отклонения компенсируют отрицательные отклонения (их сумма тождественно равна нулю). Для того чтобы решить эту проблему, мы возводим в квадрат каждое отклонение и находим среднее возведенных в квадрат отклонений; эта величина называется вариацией, или дисперсией. Возьмем, например, n наблюдений, x1, x2, x3, …, xn, средняя которых равняется мы вычисляем дисперсию, обычно обозначаемую как S2, этих наблюдений следующим образом:
Мы видим, что это не то же, что среднее арифметическое возведенных в квадрат отклонений, потому что мы разделили на (n-1) вместо n. Причина этого в том, что мы почти всегда полагаемся на выборочные данные в наших исследованиях. Теоретически можно показать, что мы получим более точную дисперсию, если разделим не на n, а на (n-1). Единица измерения (размерность) вариации – квадрат единиц измерения первоначальных наблюдений, например: если вариация измеряется в килограммах, то единицей измерения вариации будет «кг2». СТАНДАРТНОЕ ОТКЛОНЕНИЕ Стандартное (среднее квадратичное) отклонение – положительный квадратный корень из дисперсии. На примере n наблюдений это выглядит так:
Мы можем размышлять о стандартном отклонении как о своего рода среднем отклонении наблюдений от среднего. Его вычисляют в тех же самых единицах (размерностях), что и исходные данные. Если разделить стандартное отклонение на среднее арифметическое и выразить этот показатель в процентах, получится коэффициент вариации. Это мера рассеяния которая не зависит от единиц измерения (безразмерная), но имеет некоторые теоретические неудобства, поэтому статистики её не всегда одобряют. Понимание вероятности. Вероятность измеряет неопределенность.Она находится в самом центре статистической теории. Вероятность измеряет возможность появления данного события. Можно вычислить вероятность, используя различные подходы. - Субъективная – индивидуальная степень уверенности, что данное событие произойдет (например, случится конец света в 2050 г.). - Частотная – выражающая соотношение количества событий, которые могли бы произойти, если бы мы повторяли эксперимент огромное количество раз (например, если бы мы бросали монету 100 раз, сколько бы раз выпал «орёл»). - Априорная – требующая знания теоретической модели, называемой распределением вероятности, которая отображает вероятности всех возможных результатов «эксперимента». Например, генетическая теория позволяет нам отобразить вероятность распределения цвета глаз у ребёнка при рождении, если у женщины голубые глаза, а мужчины карие, первоначально определяя весь возможный генотип цвета глаз у ребенка и их вероятности. Дополнительные свойства. · Среднее и медиана нормального распределения равны. · Вероятность того, что нормально распределенная случайная переменная X, со средним µ и стандартным отклонением σ, находящаяся между: o (µ-σ) и (µ+σ), равна 0,68; o (µ-1,96σ) и (µ+1,96σ), равна 0,95; o (µ-2,58σ) и (µ+2,58σ), равна 0,99; T-распределение - получено Вильямом Госсетом, который публиковался под псевдонимом Студент (Student), поэтому его часто называют t-распределением Стьюдента. - Параметры, которые характеризуют t-распределение, - это степени свободы (df), так как мы сможем начертить функцию плотности распределения вероятности только в том случае, если мы будем знать уравнение t-распределения и степени свободы. Степени свободы часто выражаются через объем выборки. - Форма подобна форме для стандартизованного нормального распределения, но более приплюснута и с более длинными хвостами. Форма приближается к нормальной кривой, по мере того как увеличиваются степени свободы. - В частности, его применяют для вычисления доверительных интервалов и исследования гипотез с одной или двумя средними. Отношение шансов (odds ratio) это отношение шансов для первой группы объектов к отношению шансов для второй группы объектов. Интерпретация: 1) Если отношение шансов=1, то шанс для первой группы равен шансу для второй группы. 2) Если отношение шансов>1, то шанс для первой группы больше шанса для второй группы. 3) Если отношение шансов<1, то шанс для первой группы меньше шанса для второй группы.
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-01-27; просмотров: 1126; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 13.58.244.216 (0.07 с.) |